
لماذا تنسى الذكاء الاصطناعي ما قلته؟
نماذج اللغة الكبيرة لا تمتلك ذاكرة طويلة الأمد — فهي لا "ترى" سوى نافذة متحركة من الرموز الحديثة، وكل ما هو خارج هذه النافذة يُنسى أو يُضغط. تشرح هذه المقالة ما يعنيه ذلك لموجّهاتك وكيفية العمل ضمن هذه الحدود (وحولها).
ما هي نافذة السياق؟
نافذة السياق هي الحد الأقصى لكمية النص (مقاسة بالرموز) التي يمكن لنموذج اللغة الكبير مراعاتها عند توليد مخرجاته التالية.
فكّر فيها كـ"النص المرئي" للنموذج في أي لحظة معينة. عند إرسال رسالة إلى GPT-5.5 بنافذة سياق ١٢٨ك رمز، يمكن للنموذج "رؤية" آخر ١٢٨٠٠٠ رمز من المحادثة — أي نحو ٩٦٠٠٠ كلمة. كل ما يسبق ذلك غير مرئي للنموذج ولا يؤثر في استجابته.
الرموز مقابل الكلمات: الرمز ليس كلمة. في المتوسط، رمز واحد ≈ ٤ أحرف أو نحو ٠.٧٥ كلمة. نافذة سياق بـ٤٠٠٠ رمز ≈ ٣٠٠٠ كلمة من النص الإنجليزي العادي. للكود الكثيف أو اللغات كاليابانية، تختلف النسبة.
تتباين أحجام نوافذ السياق بشكل كبير بين النماذج:
| النموذج | نافذة السياق |
|---|---|
| GPT-5.5 mini | ٤ك رمز (≈ ٣٠٠٠ كلمة) |
| GPT-5.5 | ١٢٨ك رمز (≈ ٩٦٠٠٠ كلمة) |
| Claude Opus 4.8 | ٢٠٠ك رمز (≈ ١٥٠٠٠٠ كلمة) |
| Gemini 3.1 Pro | ٢٠٠٠٠٠٠ رمز (≈ ١٥٠٠٠٠٠ كلمة — أكبر سياق متاح) |
| النماذج المحلية (Ollama, LM Studio) | قابلة للتهيئة من ٤ك إلى ١٢٨ك+، مقيّدة بـVRAM المتاحة |
المبدأ متطابق في جميع النماذج: كل ما هو خارج النافذة غير مرئي.
لماذا "تنسى" الذكاء الاصطناعي؟
عندما يتجاوز إجمالي الرموز في محادثة ما (موجّه النظام + سجل المحادثة + إدخال المستخدم + الأدوات + المخرجات المتوقعة) نافذة السياق، تُقتطع الأجزاء القديمة أو تُلخَّص أو تُحذف كليًّا.
هذا ليس فقدانًا للذاكرة كالنسيان البشري. النموذج لا "يفكر ثم ينسى." إنه لا يرى النص المقتطع حرفيًّا — لم يعد موجودًا في فضاء إدخال النموذج.
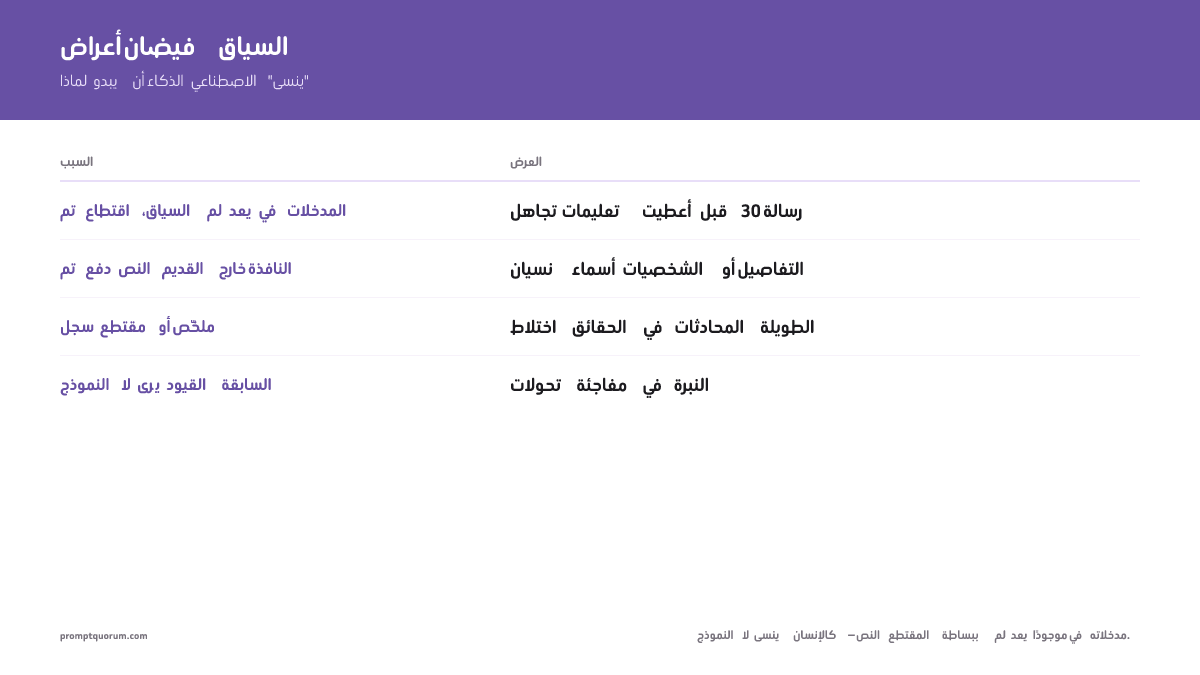
الأعراض الشائعة عند الوصول إلى حد السياق:
- الذكاء الاصطناعي يتجاهل أو يتناقض مع تعليمة أعطيتها قبل ٣٠ رسالة
- في قصة إبداعية طويلة، ينسى النموذج أسماء الشخصيات والتفاصيل والقيود التي وضعتها سابقًا
- في محادثة بحثية متعددة الأدوار، تختلط الحقائق أو يعيد النموذج اختراع المعلومات
- يغيّر الذكاء الاصطناعي نبرته فجأة أو ينتهك قيودك الأصلية دون تفسير
ما الذي يحدث فعليًّا؟
تستخدم معظم واجهات المحادثة إحدى هذه الاستراتيجيات:
- 1حذف الرسائل الأقدم — تتناسب أحدث N رسالة مع النافذة؛ تُتجاهل الأقدم كليًّا
- 2تلخيص المحادثة السابقة — يضغط النظام الرسائل المبكرة في ملخص وجيز ("سبق أن ناقشت X، Y، Z…") للحفاظ على السياق
- 3تثبيت موجّهات النظام/المطوّر — تبقى رسالة النظام ثابتة بينما تتناوب رسائل المستخدم
جميع هذه الطرق تحفظ "جوهر" المحتوى لكنها تفقد التفاصيل المحددة. حين لا يرى النموذج التعليمة الأصلية بعد الآن، لا يمكنه اتباعها.
نوافذ السياق والهلوسة
الحمل الزائد للسياق يضخّم الهلوسة لأن النموذج يملأ الفجوات بتخمينات معقولة حين لا تكون المعلومات الأصلية مرئية بعد الآن.
هذا هو النمط: تطلب من الذكاء الاصطناعي الرجوع إلى شيء ذكرته قبل ٥٠ رسالة. لكن تلك الرسالة انتهى دورانها خارج نافذة السياق. النموذج لا يمكنه الوصول إلى الحقيقة الفعلية، فيولّد إجابةً تبدو معقولة بناءً على ما يستنتجه من السياق الحالي. النتيجة: اختلاق.
لهذا تنتج المحادثات الطويلة عالية السياق في الغالب هلوسات أكثر من التبادلات القصيرة المركّزة. النموذج لا يفقد قدرته على الاستدلال — إنه يعمل بمعلومات ناقصة.
التفاعل مباشر: سياق أقل → تأسيس ناقص → خطر هلوسة متزايد.
يتضاعف هذا التأثير مع إعدادات درجة الحرارة وtop-p الأعلى التي تزيد العشوائية أصلًا.
كيف يساعدك تصميم الموجّه على البقاء ضمن النافذة
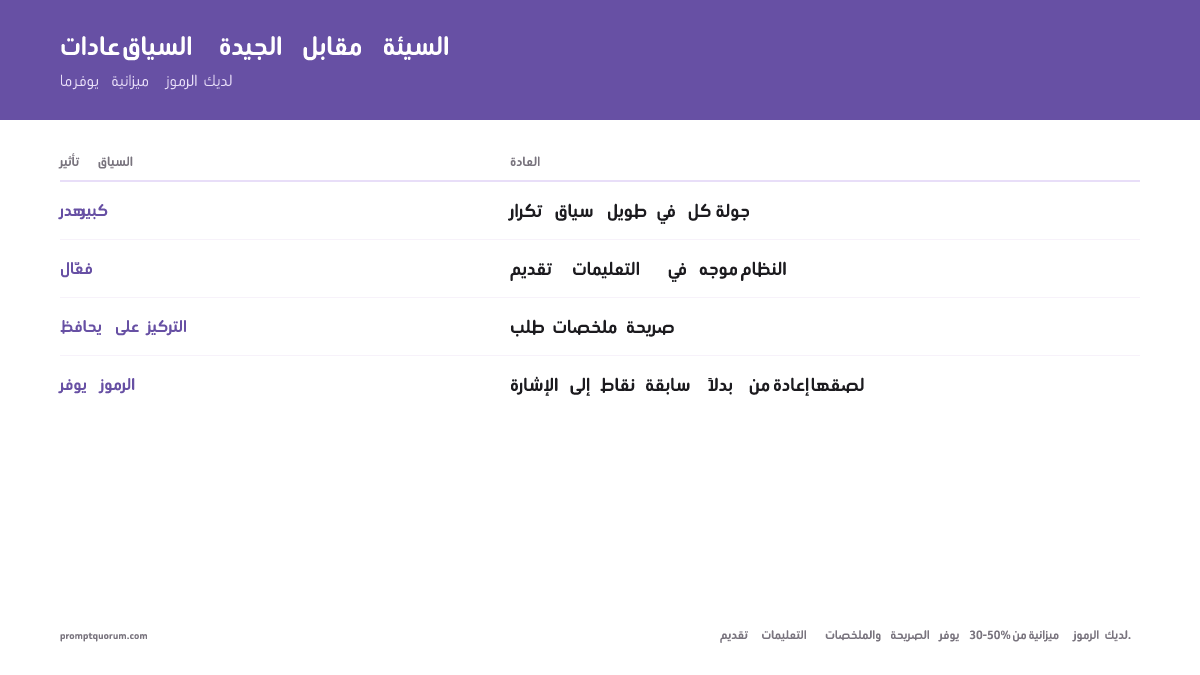
بنية موجّهاتك بشكل استراتيجي تتيح لك إنجاز المزيد ضمن ميزانية سياق ثابتة.

ضع التعليمات الحرجة في المقدمة. ضع أهم قيودك وقواعدك وتعريفاتك في موجّه النظام أو أول رسالة للمستخدم. هذه أقل عرضة للخروج من السياق مقارنةً بالتعليمات المدفونة بعد ٢٠ دورًا.
تجنّب التكرار. إن كنت قد شرحت شيئًا مرة واحدة، لا تلصقه مجددًا. أشِر إليه بدلًا من ذلك: "كما ناقشنا في الملخص أعلاه…" هذا يوفّر الرموز.
لخّص صراحةً. اطلب من النموذج تلخيص القرارات والقيود والحقائق الرئيسية حتى الآن. ثم ابنِ الاستجابة التالية على ذلك الملخص بدلًا من الاعتماد على سياق مبكر متفرق.
أبقِ الأدوار مركّزة. الحديث الطويل متعدد المواضيع يستخدم السياق بكفاءة منخفضة. قسّمه إلى تبادلات منفصلة ضيقة النطاق.
أحجام نوافذ السياق (٢٠٢٦)
العمل مع المستندات الطويلة
لصق كتب كاملة أو ملفات PDF مئات الصفحات في نافذة سياق واحدة أمر غير كفوء، حتى مع نافذة ٢ مليون رمز لـGemini 3.1 Pro، لأن النموذج لا يستطيع التركيز بفعالية على أقسام متباينة متعددة في آن واحد.
كتاب من ١٠٠٠ صفحة ≈ ٢٥٠٠٠٠ رمز. تقنيًّا، يستطيع Gemini 3.1 Pro استيعابه. عمليًّا، يتدهور استدلال النموذج حين يُطلب منه الإجابة عن أسئلة عبر أقسام متباعدة جدًّا. نهج أفضل للمستندات الطويلة:
- 1عالج الأقسام بشكل تسلسلي. استخرج قسمًا أو فصلًا في كل مرة. اطرح أسئلة مركّزة لكل قسم: "ما الاستنتاجات الرئيسية في القسم الثالث؟" ثم انتقل إلى القسم التالي.
- 2التلخيص الهرمي. استخرج النقاط الرئيسية من الصفحات ١-١٠، ثم ١١-٢٠، ثم ادمج هذه الملخصات في ملخص على مستوى الفصل. ادمج الفصول في ملخص على مستوى المستند.
- 3الاستخراج المنظّم. حوّل المستند إلى جداول أو JSON أو قوائم نقطية قبل طرح أسئلة أعلى مستوى. هذا يضغط المعلومات.
- 4استخدم RAG (التوليد المعزّز بالاسترجاع). للمجموعات الضخمة حقًّا (١٠٠+ صفحة)، تعمل الأنظمة القائمة على الاسترجاع بشكل أفضل.
كيف يساعدك PromptQuorum في إدارة السياق
العمل بالقرب من حدود السياق أمر صعب لأن كل نموذج له حدود مختلفة وسلوك اقتطاع وتسعير ومتطلبات VRAM (للنماذج المحلية). PromptQuorum يجعل هذه القيود شفافة: قبل الإرسال، يمكنك رؤية كمية السياق التي يستهلكها كل نموذج ومتى يُحتمل حدوث الفيضان.
ضبط نافذة السياق للنماذج المحلية
حين تشغّل نموذجًا في LM Studio أو Ollama، يمكنك تهيئة حجم نافذة السياق. افتراضيًّا، تضبط الأدوات في الغالب الحد الأقصى للنموذج (مثلًا ٣٢ك لنموذج 7B). لكن هذا نادرًا ما يكون ما تحتاجه.
يتكامل PromptQuorum مع LM Studio ويتيح لك ضبط نافذة السياق لكل مهمة: اختر ٤ك للأسئلة والأجوبة الخفيفة السريعة؛ اختر ٣٢ك لتحليل المستندات العميق؛ اختر ٦٤ك للمحادثات الطويلة.
فحوصات فيضان السياق التلقائية
يتحقق PromptQuorum قبل الإرسال: بالنظر إلى موجّه النظام + سجل المحادثة الحالي + إدخالك الجديد + طول المخرجات المتوقعة، هل يتناسب مع نافذة السياق المهيّأة لكل نموذج؟
إن كان الفيضان مرجّحًا، يحذّرك PromptQuorum أو يطلب منك تقليص المحادثة أو تلخيصها قبل الإرسال. لا مزيد من الاقتطاع المفاجئ.
نافذة السياق ↔ مقايضة VRAM
للنماذج المحلية، تتطلب نوافذ السياق الأكبر VRAM أكثر بشكل ملحوظ. نموذج 7B بتكميم Q4_K_M يحتاج ≈٥ جيجابايت عند ٤ك، و≈٨-١٠ جيجابايت عند ٣٢ك، و≈١٢-١٤ جيجابايت عند ١٢٨ك. تجاوز VRAM المتاحة يتسبب في انهيار العملية أو التراجع إلى الاستدلال بالمعالج المركزي (أبطأ بـ١٠-١٠٠ مرة).
لأحدث النماذج ذات نوافذ السياق الطويلة للنشر المحلي — بما فيها متطلبات العتاد — انظر نماذج اللغة المحلية ذات السياق الطويل.
الوعي متعدد النماذج
حين ترسل موجّهًا إلى GPT-5.5 (نافذة ١٢٨ك) وClaude (نافذة ٢٠٠ك) ونموذج 7B محلي (نافذة ٣٢ك)، يحافظ PromptQuorum تلقائيًّا على موجّهك ضمن الحدود الثلاثة. موجّه واحد، نماذج متعددة، دون إعادة كتابة يدوية.
وصفات عملية لإدارة السياق
الوصفة الأولى: محادثة طويلة حول مشروع — الحفاظ على محادثة متعددة الأدوار حول مشروع واحد دون فقدان القرارات السابقة.
- 1في موجّه النظام، ضمّن القيود الرئيسية للمشروع (النطاق والجمهور والنبرة والحدود التقنية) مرة واحدة. لا تكررها.
- 2بعد كل ١٠-١٥ تبادل، اطلب من النموذج تلخيص الحالة الراهنة: "ما أهم ٥ قرارات اتخذناها حتى الآن؟"
- 3استخدم ذلك الملخص سياقًا لدورك التالي بدلًا من الاعتماد على رسائل مبكرة متفرقة.
- 4في PromptQuorum، عيّن نافذة سياق ٣٢ك-٦٤ك وفعّل تحذيرات الفيضان لمعرفة متى تلخّص.
الوصفة الثانية: تحليل تقرير طويل — استخراج رؤى من مستند مؤلّف من ٥٠-١٠٠ صفحة.
- 1قسّم المستند إلى ٣-٥ أقسام (فصول، أجزاء).
- 2لكل قسم، اكتب موجّهًا مركّزًا: "لخّص النتائج الرئيسية لهذا القسم في ٥ نقاط."
- 3اجمع تلك الملخصات الخمسة من كل قسم.
- 4في دور أخير، اسأل: "بالنظر إلى هذه الملخصات، ما الاستنتاج الإجمالي؟"
- 5لقد بقيت ضمن حدود السياق بشكل جيد وتجنّبت مشكلة "الضياع في كتاب."
الوصفة الثالثة: الموجّه عند حافة نافذة السياق — استخدام نافذة السياق الكاملة تقريبًا دون فيضان.
- 1احسب ميزانيتك: حجم نافذة السياق − رموز موجّه النظام − رموز المخرجات المتوقعة = الرموز المتاحة لإدخالك + التاريخ.
- 2مثال: نافذة ١٢٨ك، موجّه نظام بـ٢٠٠ رمز، مخزن مؤقت للمخرجات ١ك = ١٢٦.٨ك رمزًا متاحًا.
- 3قبل الإرسال، تحقق في PromptQuorum: "كم رمزًا يستهلك هذا الإدخال؟"
- 4إن كنت قريبًا من الحد، اقطع الدور الأقدم أو لخّصه قبل المتابعة.
- 5هذا يبقيك تعمل بوعي بالقرب من الحد، لا تصطدم به عشوائيًّا.
الوصفة الرابعة: نموذج محلي بـVRAM محدودة — تشغيل نموذج محلي بفعالية دون انهيارات.
- 1ابدأ بنافذة سياق محافظة (٨ك-١٦ك) لـVRAM نموذجك.
- 2في إعدادات PromptQuorum، لاحظ متطلب VRAM عند ذلك الحجم.
- 3شغّل مهمتك. إن حدث فيضان، لخّص المحادثة وابدأ من الملخص.
- 4إن لم تقترب أبدًا من الحد، زِد نافذة السياق تدريجيًّا وأعِد الاختبار.
- 5اعثر على نافذة السياق "المناسبة للحجم" لنموذجك بالنسبة لعتادك ومهامك.
الأخطاء الشائعة مع نوافذ السياق
- "النموذج يتذكر جميع محادثاتي السابقة." لا. كل محادثة جديدة تبدأ بسياق صفري من المحادثات الماضية. حتى ضمن محادثة واحدة، حين يتجاوز تبادلك نافذة السياق، تختفي التفاصيل.
- "سألصق نفس السياق الطويل في كل دور." هذا يهدر الرموز ولا يساعد — النموذج لا يزال غير قادر على الاستدلال بفعالية على ٣٠٠ صفحة. بدلًا من ذلك، لخّص وأشِر إلى الملخص.
- "سأخلط خمسة مشاريع مختلفة في محادثة طويلة." كل مشروع يتنافس على الرموز. حين يمتلئ السياق، تُقتطع التفاصيل. استخدم محادثات منفصلة لكل مشروع.
- "الذكاء الاصطناعي سيء في الاستدلال — يجب أن تكون درجة الحرارة أو top-p." ربما. لكن أولًا تحقق من نافذة السياق. إن لم يعد النموذج يرى القيد الأصلي، فهذه ليست مشكلة معاملات؛ إنها معلومات ناقصة.
- "سأعظّم نافذة السياق على نموذجي المحلي." ثم ستنفد VRAM، وتنهار العملية، ويتراجع الاستدلال إلى وضع المعالج المركزي البطيء. عوضًا عن ذلك، عيّن السياق ليتناسب مع عتادك.
- "التطبيق حذّرني من الفيضان، لكنني أرسلت على أي حال." ثِق بالتحذير. الفيضان يؤدي إلى اقتطاع صامت وهلوسة مخفية ورموز مهدرة. لخّص أولًا.
الأسئلة الشائعة
هل يتذكر النموذج محادثاتي السابقة؟
لا. كل جلسة محادثة جديدة تبدأ بتاريخ صفري. النموذج يرى فقط الرموز ضمن نافذة السياق الحالية. إن أردت الإشارة إلى محادثة سابقة، يجب نسخ الأجزاء ذات الصلة في المحادثة الحالية.
لماذا تجاهل الذكاء الاصطناعي تعليمة أعطيتها قبل ٢٠ رسالة؟
على الأرجح انزلقت تلك التعليمة خارج نافذة السياق. النموذج لم يعد يراها، فلا يمكنه اتباعها. الحل: كرّر التعليمات الحرجة في موجّه النظام أو اطلب من النموذج إعادة تلخيص التعليمة وإعادة تضمينها في منتصف المحادثة.
هل نافذة السياق الأكبر دائمًا أفضل؟
لا. النافذة الأكبر تتيح لك تضمين محتوى أكثر، لكنها تزيد التكلفة (رموز أكثر للمعالجة) وبالنسبة للنماذج المحلية، استهلاك VRAM. اختر نافذة سياق تتناسب مع مهمتك: ٤ك للأسئلة والأجوبة البسيطة، ٣٢ك للمحادثات الطويلة، ١٢٨ك+ لتحليل المستندات. الأكبر ليس "أفضل" — المناسب هو الأفضل.
كيف أعرف حين أبلغ حد السياق؟
تتغيّر نبرة استجابات النموذج، أو تتناقض مع التعليمات السابقة، أو تفقد تفاصيل حدّدتها سابقًا. استخدم فحص فيضان السياق في PromptQuorum قبل الإرسال — يحذّرك حين تقترب من الحد.
كيف يؤثر حجم نافذة السياق في VRAM للنماذج المحلية؟
نموذج 7B (تكميم Q4_K_M) يحتاج ≈٥ جيجابايت VRAM عند ٤ك، و≈٨-١٠ جيجابايت عند ٣٢ك، و≈١٢-١٤ جيجابايت عند ١٢٨ك. الزيادة ليست خطية بالضبط. تحقق من حاسبة VRAM في PromptQuorum لمعرفة سقف عتادك.
هل تستطيع أدوات كـPromptQuorum منع فيضان السياق؟
نعم. يتحقق PromptQuorum من عدد رموز موجّهك ونافذة السياق المهيّأة والحد الفعلي لنموذجك، ثم يحذّرك قبل الإرسال إن كان الفيضان مرجّحًا. يمكنك بعدها التقليص أو التلخيص قبل المتابعة.
هل تتعامل النماذج المختلفة مع السياق الطويل بشكل مختلف؟
نعم. Claude Opus 4.8 يحافظ على التركيز جيدًا عبر ٢٠٠ك رمز. GPT-5.5 متين عند ١٢٨ك. النماذج الأصغر (مثل LLaMA 3.1 7B) أحيانًا تفقد تماسك الاستدلال بعد ٨ك-١٦ك، حتى لو كانت نافذة سياقها أكبر تقنيًّا. النهج الأأمن: اختبر نموذجك ومهمتك المحددين.
قراءات ذات صلة
- المكوّنات الخمسة لكل موجّه — كيفية بنية الموجّهات قبل أن يصبح السياق قيدًا
- هلوسة الذكاء الاصطناعي: لماذا يخترع الذكاء الاصطناعي الأشياء؟ — لماذا يزيد السياق الناقص من خطر الهلوسة
- RAG مشروح: كيف تربط إجابات الذكاء الاصطناعي بالبيانات الحقيقية؟ — كيفية التعامل مع مجموعات المستندات الكبيرة باسترجاع بدلًا من السياق الخام
المصادر
- OpenAI, 2026. "API reference: Models and context windows" — توثيق رسمي حول حدود الرموز والتسعير لكل نموذج
- Anthropic, 2026. "Claude model context windows and token costs" — نوافذ سياق Claude ونظرة عامة على النماذج الحالية
- Raffel et al., 2020. "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer" — بحث أساسي حول تأثيرات نافذة السياق في المحوّلات