الحد الخفي: حقيقة تواريخ انقطاع المعرفة
<strong>تاريخ انقطاع المعرفة هو التاريخ الذي يتوقف فيه نموذج الذكاء الاصطناعي عن تلقي بيانات التدريب.</strong> الأحداث التي وقعت بعد الانقطاع وإطلاقات المنتجات والأبحاث الجديدة وتغيرات الأسعار أو أي تطورات أخرى غير مرئية للنموذج.
هذا يخلق نمط فشل منهجي: الذكاء الاصطناعي يقدم إجابات واثقة عن موضوعات لا يعرفها إطلاقًا. لأن النموذج لا يعرف ما لا يعرفه.
يزيد الالتباس لأن كثيرًا من المنتجات السحابية تضيف بحثًا مباشرًا فوق النموذج الأساسي. حين يجيب ChatGPT على سؤال عن أخبار اليوم، يستخدم Bing — وليس بيانات التدريب.
🔍 مرجع سريع
تحتاج الجدول فقط؟ راجع <a href="/ar/prompt-bites/ai-model-knowledge-cutoff-dates" class="text-primary hover:underline">ورقة مرجع تواريخ انقطاع معرفة الذكاء الاصطناعي</a>.
تاريخ الانقطاع مقابل البحث المباشر: الفرق الذي يغير كل شيء
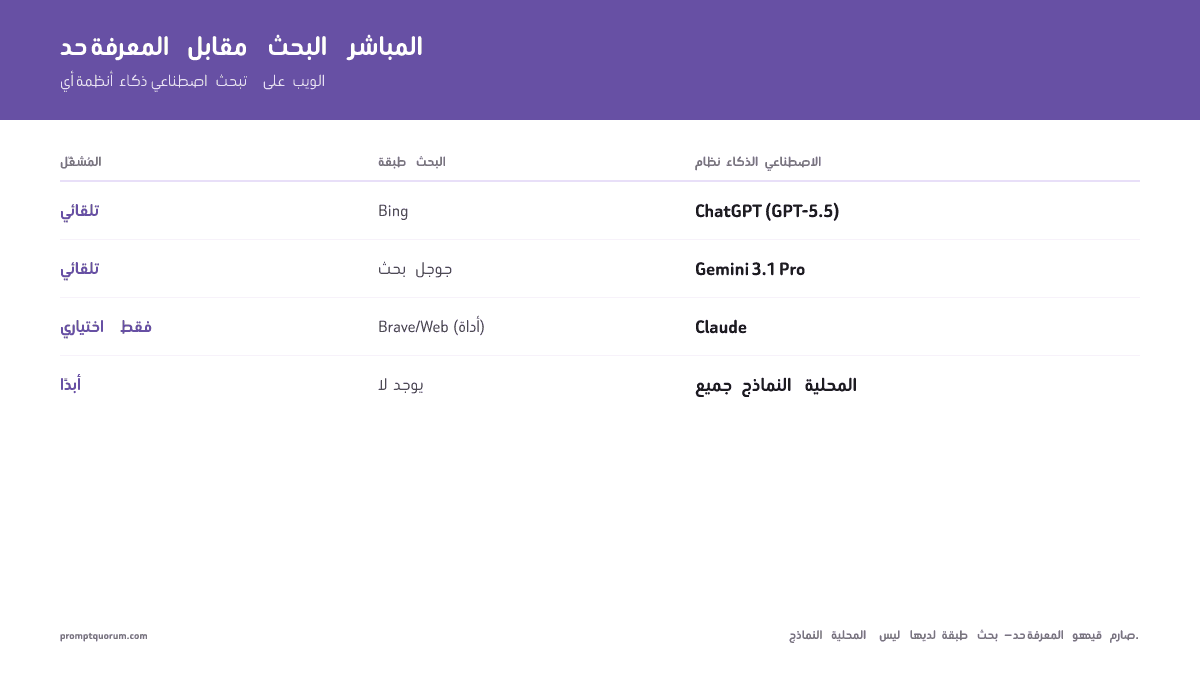
<strong>التمييز الأهم هو بين انقطاع التدريب (خاصية النموذج) والبحث المباشر (ميزة المنتج).</strong>
<strong>انقطاع التدريب</strong> مضمّن في أوزان النموذج. لا يمكن تغييره دون إعادة تدريب النموذج.
<strong>طبقة البحث المباشر</strong> أداة خارجية مدمجة على مستوى المنتج. حين يحتاج ChatGPT إلى معلومات حالية، يستعلم API Bing ويجمع النتائج مع قدرته الاستدلالية.
| النموذج / المنتج | طبقة البحث | محفّز البحث | ملاحظة |
|---|---|---|---|
| GPT-5.5 (ChatGPT) | Bing | تلقائي — النموذج يقرر | مفعّل افتراضيًا في ChatGPT Plus/Pro؛ مطفأ في API المباشر |
| Gemini 3.1 Pro | Google Search | تلقائي — النموذج يقرر | Google Grounding API للمطورين |
| Grok 4.3 (X.com) | X (Twitter) | تلقائي — النموذج يقرر | DeepSearch = بحث أوسع، اختياري |
| Perplexity | ويب متعدد المصادر | دائمًا — في كل استعلام | بحث-أولًا بالتصميم؛ يستشهد بالمصادر |
| Claude (Anthropic) | Brave / ويب (أداة) | اختياري للمطور فقط | مطفأ افتراضيًا؛ يتطلب تكوين أدوات API |
| DeepSeek (سحابة) | لا شيء | لا ينطبق | بلا طبقة بحث؛ تاريخ الانقطاع حد صلب |
| Mistral (سحابة) | لا شيء | لا ينطبق | بلا طبقة بحث؛ تاريخ الانقطاع حد صلب |
| جميع نماذج LLM المحلية | لا شيء | لا ينطبق | بلا وصول للإنترنت افتراضيًا؛ يتطلب RAG للمعلومات الحالية |
البيانات الموثّقة الكاملة: جميع النماذج الرئيسية
📍 In One Sentence
من بين نماذج السحابة، Claude وحده يتطلب تكوينًا صريحًا من المطور لبحث الويب — جميع الآخرين لديهم البحث المباشر مفعّلًا افتراضيًا.
💬 In Plain Terms
نماذج الذكاء الاصطناعي السحابية كباحثين يمكنهم البحث بين الإجابات. نماذج الذكاء الاصطناعي المحلية كباحثين كانوا دون اتصال منذ تاريخ محدد.
الجدول أدناه يستخدم فقط بيانات المصادر الأولية. حيث لا يوجد مصدر أولي يُعلَّم تاريخ الانقطاع "غير مُفصح عنه علنًا".
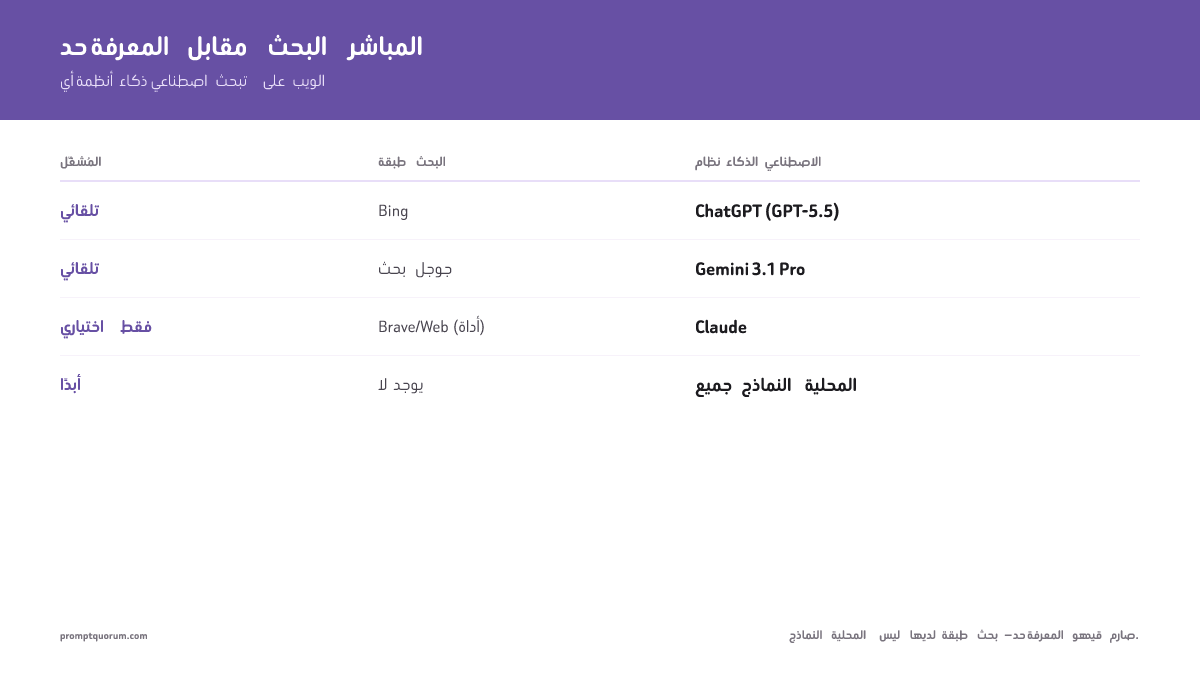
<strong>النماذج السحابية:</strong>
| النموذج | المزوّد | تاريخ الانقطاع | موثّق | بحث افتراضي | طبقة البحث |
|---|---|---|---|---|---|
| Claude Opus 4.8 | Anthropic | 2026-01 | ✓ | عبر أداة فقط | Tool-use only |
| GPT-5.5 (ChatGPT) | OpenAI | 2025-08 | ✓ | نعم | Bing |
| GPT-4o (legacy) | OpenAI | 2023-10 | ✓ | نعم | Bing |
| Gemini 3.1 Pro | 2025-01 | ✓ | نعم | ||
| Grok 4.3 | xAI | 2024-11 | ✓ | نعم | X (Twitter) |
| Mistral Large 3 | Mistral AI | Not publicly disclosed | — | لا | None |
| DeepSeek-V3 / R1 | DeepSeek | 2024-07 | ✓ | لا | None |
النماذج المحلية / open-weight: تواريخ انقطاع موثّقة
<strong>نماذج open-weight المحلية — جميعها بطبقة بحث "لا شيء":</strong>
| النموذج | المزوّد | تاريخ الانقطاع | موثّق | النشر | الترخيص |
|---|---|---|---|---|---|
| Llama 4 Scout / Llama 3.3 70B | Meta | Not publicly disclosed | — غير مُفصح | Both | Open weights |
| Qwen3 14B / Qwen2.5 72B | Alibaba | 2023-12 | ✓ مصدر أولي | Both | Open weights |
| Mistral Small 3 / Mistral 7B | Mistral AI | Not publicly disclosed | — غير مُفصح | Both | Open weights |
| DeepSeek-V3 (open weights) | DeepSeek | 2024-07 | ✓ مصدر أولي | Both | Open weights |
| Gemma 3 27B | 2024-08 | ✓ مصدر أولي | Both | Open weights | |
| Phi-4 | Microsoft | 2024-06 | ✓ مصدر أولي | Both | Open weights |
⚠️ الرؤية الأساسية
جميع النماذج المحلية في هذا الجدول لديها طبقة بحث "لا شيء". هذه خاصية هيكلية لنماذج LLM المنشورة محليًا، وليست قيدًا على نموذج بعينه.
مشكلة LLM المحلي: التشغيل بمعرفة مجمّدة
<strong>عند تشغيل LLM محلي عبر Ollama أو LM Studio أو llama.cpp، أنت تشغّل نموذجًا معرفته مجمّدة كليًا في تاريخ محدد.</strong>
هذه ليست مجرد إزعاج — إنها خاصية معمارية أساسية. الأوزان على القرص لا تتغير بين التشغيلات.
أنماط فشل محددة: نموذج يُسأل عن شركة أعادت تسميتها بعد الانقطاع سيستخدم الاسم القديم. نموذج يُسأل عن منتج أُطلق بعد الانقطاع سيخترع وصفًا مقنعًا.
<strong>الآلاف من التطبيقات المبنية على نماذج LLM المحلية تشترك في مشكلة المعرفة المجمّدة هذه.</strong> أي منظمة تنشر Llama أو Qwen أو Gemma أو Phi داخليًا بلا RAG تشغّل برمجيات لا تعرف ما حدث بعد تاريخ الانقطاع.
| السيناريو | LLM سحابي مع بحث | LLM محلي بلا RAG |
|---|---|---|
| سؤال عن أخبار اليوم | يبحث في Bing/Google؛ إجابة حالية | يعترف بالجهل أو يهلوس |
| سؤال عن إطلاق منتج 2025 | يبحث على الويب؛ مواصفات حالية | بلا معرفة إذا كان بعد الانقطاع |
| سؤال عن شركة (بعد الانقطاع) | يستطيع البحث عن الموقع | لا يجد؛ غير موجود في بيانات التدريب |
| إعادة تسمية منافس | يجد الاسم الحالي عبر البحث | يستخدم الاسم القديم من التدريب |
| لائحة تنظيمية جديدة | يبحث عن النص القانوني الحالي | معرفة ما قبل اللائحة فقط |
| ترتيب نماذج الذكاء الاصطناعي | يبحث عن المعايير؛ محدّث في معظمه | مجمّد عند تاريخ الانقطاع؛ ترتيب قديم |
🔍 قيود LLM المحلي
للتحليل الكامل راجع <a href="/ar/local-llms/local-llm-limitations" class="text-primary hover:underline">قيود LLM المحلي: ما لا يستطيع فعله</a>.
الآثار على المستخدمين: كيفية الوثوق بإجابات الذكاء الاصطناعي
<strong>القاعدة الأهم: اسأل نفسك دائمًا إذا كانت الإجابة قد تغيرت بعد تاريخ انقطاع النموذج.</strong> إذا نعم، تحقق باستقلالية.
تتعامل أنظمة الذكاء الاصطناعي المختلفة مع الفجوات بعد الانقطاع بطرق مختلفة.
| نظام الذكاء الاصطناعي | السلوك بعد الانقطاع | موثوقية المعلومات الحالية | كيفية التحسين |
|---|---|---|---|
| ChatGPT (مدفوع) | يبحث تلقائيًا في Bing | عالية للحقائق؛ منخفضة للفروق الدقيقة | اطلب استشهادات بالمصادر؛ تحقق من الادعاءات الرئيسية |
| Gemini (مدفوع) | يبحث تلقائيًا في Google | عالية للحقائق؛ منخفضة للفروق الدقيقة | فعّل التأريض؛ راجع روابط URL المستشهد بها |
| Grok (X.com) | يبحث تلقائيًا في منشورات X | جيد للاتجاهات الاجتماعية؛ غير منتظم للحقائق | استخدم DeepSearch لتغطية أوسع |
| Claude (مجاني/برو) | يستخدم بيانات التدريب فقط افتراضيًا | متوسط — انقطاع موثوق يناير 2026 | الصق النص الحالي في السياق |
| Perplexity | يبحث على الويب دائمًا أولًا | عالية — منتج بحث أصيل | يستشهد بالمصادر بالتصميم بالفعل |
| جميع نماذج LLM المحلية | بيانات تدريب فقط — بلا تجاوز | منخفضة جدًا للمواضيع بعد الانقطاع | ابنِ خط أنابيب RAG؛ الصق السياق يدويًا |
⚠️ خطر الهلوسة
أعلى خطر للهلوسة يكون حين يُسأل النموذج عن محتوى بعد تاريخ الانقطاع يبدو مشابهًا لما يعرفه النموذج. سيقدم إجابة واثقة بدلًا من الاعتراف بالجهل.
الآثار على الشركات: استراتيجية GEO لكل نظام ذكاء اصطناعي
<strong>GEO (تحسين محرك التوليد) هو ممارسة جعل علامتك التجارية أو منتجك أو محتواك يظهر في إجابات الذكاء الاصطناعي.</strong>
لكن نماذج LLM المحلية تكسر هذا النموذج كليًا. Llama أو Qwen المنشور محليًا لا يبحث في الويب.
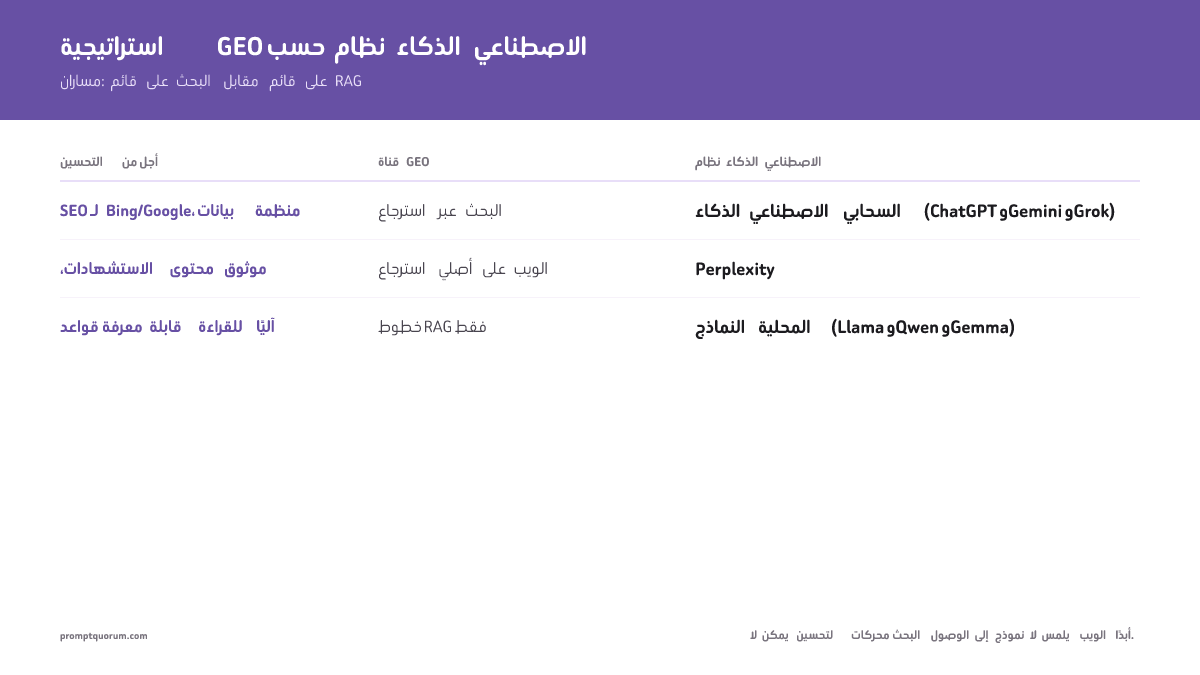
هذا الجدول يُعيّن قنوات GEO لكل نظام ذكاء اصطناعي:
| نظام الذكاء الاصطناعي | قناة GEO | ما يجب تحسينه | هل يغيّر النشر المحلي هذا؟ |
|---|---|---|---|
| GPT-5.5 (ChatGPT) | بحث Bing | SEO Bing: SEO تقني وBing Webmaster Tools وبيانات منظّمة | نعم — استدعاءات API المحلية بلا Bing |
| Gemini 3.1 Pro | تأريض Google Search | SEO Google + بيانات منظّمة | ليس بعد — Gemini سحابة فقط |
| Grok 4.3 | محتوى X (Twitter) | حضور على X: حساب موثّق ومنشورات عالية التفاعل | ليس بعد — Grok سحابة فقط |
| Perplexity | بحث ويب أصيل | جميع محركات البحث + مصادر موثوقة | لا — ويب أصيل بالتصميم |
| Claude (API) | بحث عبر أداة — اختياري | حضور ويب عام؛ محتوى منظّم لملاءمة المقتطفات | نعم — كثير من نشريات Claude لديها البحث معطّلًا |
| Llama (محلي) | خط أنابيب RAG فقط | RAG: تنسيقات بيانات منظّمة وقاعدة معرفة وAPIs للمستندات | هذا هو النشر المحلي — SEO غير ذي صلة |
| Qwen / Gemma / Phi (محلي) | خط أنابيب RAG فقط | RAG: خط أنابيب جمع مستندات المنظمة المنشِرة | هذا هو النشر المحلي — SEO غير ذي صلة |
⚠️ نقطة عمياء GEO للـLLM المحلي
معظم أدلة GEO تركز على ذكاء اصطناعي السحابة فقط. ذلك النصح عديم الجدوى للوصول إلى نشريات داخلية من Llama أو Qwen. هذه النماذج لا تبحث. قناة GEO الوحيدة الفعّالة هي إقناع المنظمة المنشِرة بتضمين محتواك في خط أنابيب RAG.
حل GEO: بناء ميزة تنافسية لكلا نوعَي الذكاء الاصطناعي
<strong>استراتيجية GEO الكاملة في 2026 تتطلب مسارين متوازيين: تحسين البحث للذكاء الاصطناعي السحابي والجاهزية لـRAG للذكاء الاصطناعي المحلي.</strong>
<strong>المسار 1 — الذكاء الاصطناعي السحابي:</strong> تقنيات SEO التقليدية مع إضافات خاصة بالذكاء الاصطناعي — هيكلة المحتوى لملاءمة المقتطفات ودقته واقعيًا وسلطته.
<strong>المسار 2 — الذكاء الاصطناعي المحلي:</strong> إنشاء قاعدة معرفة قابلة للقراءة آليًا (Markdown وJSON-LD ومواصفات OpenAPI)؛ المشاركة في مبادرات البيانات المفتوحة؛ بناء علاقات مع عملاء مؤسسيين.
المسار 1 جارٍ عادةً كجزء من SEO. المسار 2 يتطلب عملًا جديدًا — إنشاء محتوى محسّن لجمع الآلات.
- 1مراجعة الظهور في الذكاء الاصطناعي: اختبر ChatGPT وGemini وGrok وPerplexity والنشريات المحلية بشكل منفصل
- 2لثغرات الذكاء الاصطناعي السحابي: طبّق ترميز البيانات المنظّمة (FAQPage وHowTo وTechArticle) وحسّن حضور Bing Webmaster
- 3لثغرات الذكاء الاصطناعي المحلي: أنشئ قاعدة معرفة قابلة للقراءة آليًا (JSON منظّم ومستندات Markdown)
- 4وثّق حقائق العلامة التجارية بتنسيق ثابت — أسماء النماذج والأوصاف والميزات والأسعار
- 5انشر ملف llms.txt والبيانات المنظّمة في جميع الصفحات الرئيسية
- 6تتبّع معدل الذكر في جميع أنظمة الذكاء الاصطناعي ربع سنويًا
🔍 موارد RAG المحلي
للتطبيق التقني، راجع <a href="/ar/local-llms/local-rag-2026" class="text-primary hover:underline">RAG المحلي 2026: أفضل الأدوات والأطر</a> و<a href="/ar/local-llms/corporate-rag-local-llms" class="text-primary hover:underline">RAG المؤسسي مع نماذج LLM المحلية</a>.
الأسئلة الشائعة
ما هو تاريخ انقطاع معرفة الذكاء الاصطناعي؟
تاريخ انقطاع المعرفة هو التاريخ الذي تنتهي عنده بيانات تدريب النموذج. لا يمتلك النموذج أي معلومات عن الأحداث أو المنتجات أو المحتوى بعد هذا التاريخ. يمكن لنماذج السحابة التعويض جزئيًا، لكن نماذج LLM المحلية لا تستطيع.
إذا كان انقطاع ChatGPT في أكتوبر 2023، لماذا يعرف الأحداث الأخيرة؟
ChatGPT (المنتج) يبحث في Bing افتراضيًا في الخطط المدفوعة. النموذج الأساسي GPT-4o لا يزال بتاريخ انقطاع أكتوبر 2023 — ما تراه هو طبقة البحث، وليس بيانات تدريب محدّثة.
هل تتلقى نماذج LLM المحلية كـLlama أو Qwen تحديثات للمعرفة؟
لا. معرفة نماذج LLM المحلية تتجمّد بصفة دائمة عند تاريخ انقطاع التدريب. للحصول على معلومات حالية، ابنِ خط أنابيب RAG.
ما هو GEO وعلاقته بتواريخ الانقطاع؟
GEO (تحسين محرك التوليد) هو ممارسة جعل علامتك التجارية أو محتواك يظهر في إجابات الذكاء الاصطناعي. لذكاء اصطناعي السحابة، GEO يتداخل مع SEO. لنماذج LLM المحلية، هذا مستحيل هيكليًا لأن النموذج لا يبحث.
أي نموذج ذكاء اصطناعي لديه أحدث تاريخ انقطاع موثّق؟
Claude Opus 4.8 لديه أحدث تاريخ انقطاع موثوق في يناير 2026. GPT-5.5: أغسطس 2025. Gemini 3.1 Pro: يناير 2025. Grok 4.3: نوفمبر 2024. Phi-4: يونيو 2024. GPT-4o القديم: أكتوبر 2023.
هل يمكنني استخدام SEO للظهور في إجابات Llama أو Qwen؟
لا. SEO لا يستطيع التأثير في نماذج LLM المنشورة محليًا لأن النموذج لا يبحث في الويب.
كيف أتحقق من صحة إجابات الذكاء الاصطناعي المتأثرة بتواريخ الانقطاع؟
ثلاثة مؤشرات: (1) الموضوع يتضمن إصدارات أو أسعارًا محددة؛ (2) قطاع يتغير بسرعة؛ (3) لا استشهادات في الإجابة. تحقق دائمًا من المصادر الأولية.
كيف أعرف إذا كانت إجابة الذكاء الاصطناعي استخدمت البحث المباشر؟
Perplexity دائمًا يعرض استشهادات. Gemini يعرض أيقونة Google Search. Grok يشير إلى نتائج X. ChatGPT يعرض أيقونة كرة أرضية. Claude لا يبحث افتراضيًا. نماذج LLM المحلية لا تبحث أبدًا.
قراءة ذات صلة
- RAG موضّح: التوليد المعزّز بالاسترجاع — RAG هو الحل الرئيسي لحدود قطع معرفة LLM المحلي
- هلوسة الذكاء الاصطناعي: لماذا يخترع الذكاء الاصطناعي معلومات — قِدَم انقطاع المعرفة هو سبب رئيسي للهلوسة
- قيود الذكاء الاصطناعي: ما لا تستطيع نماذج LLM فعله — القيود الهيكلية بما فيها المعرفة المجمّدة وغياب البحث المباشر
- تواريخ انقطاع معرفة نماذج الذكاء الاصطناعي 2026: ورقة مرجعية — جدول مرجعي قابل للمسح لجميع النماذج الرئيسية السحابية والمحلية
- تحديثات نماذج LLM المحلية 2026 — تتبع كل إصدار رئيسي مفتوح الأوزان وتأثيره على مشهد الانقطاع