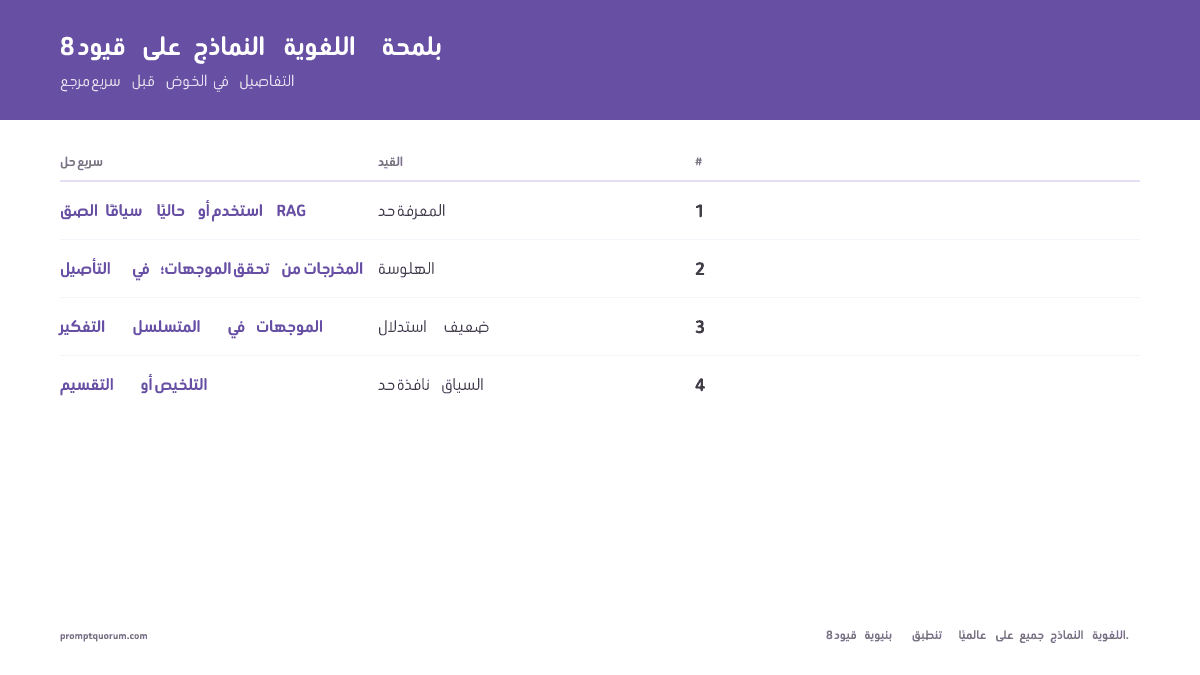
القيود الهيكلية الثمانية للنماذج اللغوية الكبيرة
للنماذج اللغوية الكبيرة ثمانية قيود صارمة تُطبَّق بصرف النظر عن حجم النموذج أو المزوِّد أو منهج التدريب. هذه ليست أخطاءً — بل هي خصائص هيكلية لكيفية تصميم النماذج اللغوية الكبيرة. كل حل مذكور أدناه هو حل إنتاجي مُجرَّب، لا نظرية.
تُطبَّق هذه القيود بشكل شامل: GPT-5.5 وClaude Opus 4.8 وGemini 3.1 Pro وLLaMA 3.1 وMistral Large وجميع النماذج مفتوحة المصدر متأثرة بالقدر ذاته. يمكن لهندسة التعليمات أن تُخفِّف من تأثير هذه القيود لكن لا تستطيع إزالتها.
القيد ١: قطع المعرفة
تُدرَّب النماذج اللغوية الكبيرة على بيانات ذات تاريخ نهائي محدد — المعروف بقطع المعرفة أو قطع التدريب. أي حدث أو تغيير في الأسعار أو إطلاق منتج جديد أو تحديث تنظيمي بعد ذلك التاريخ يكون غير مرئي للنموذج.
قطوع المعرفة في عام 2026: GPT-5.5 (OpenAI): أكتوبر 2024. Claude Opus 4.8 (Anthropic): مطلع 2025. Gemini 3.1 Pro (Google DeepMind): مطلع 2025.
- الحل الرئيسي: RAG (التوليد المعزَّز بالاسترجاع). قبل إرسال الطلب، استرجع الحقائق الحالية ذات الصلة من مصدر موثوق وأدرجها في سياق التعليمة. يُجيب النموذج بناءً على تلك المعلومات بدلًا من بيانات تدريبه القديمة.
- الحل الثانوي: لصق السياق المباشر. للمهام الفردية، الصق ببساطة النص المحدَّث ذا الصلة في التعليمة. "إليك الحالة الراهنة: الصق النص" يُلغي فعليًا المعرفة القديمة.
- إشارة تحذير. إذا كان تطبيقك يعتمد على حقائق حالية (أسعار، إحصاءات، أسماء أشخاص)، خطِّط لـ RAG من البداية. الصياغة بدون RAG ستُنتج معلومات قديمة بكل ثقة.
القيد ٢: الهلوسة
تتنبأ النماذج اللغوية الكبيرة بالرمز التالي بناءً على الاحتمالية الإحصائية — لا تتحقق من الحقائق مقابل أي قاعدة بيانات. هذا يُنتج هلوسات: ادعاءات كاذبة أو ملفقة تُقدَّم بثقة كاملة. الاستشهادات المخترعة وعناوين URL الوهمية والإحصاءات الخاطئة والتفاصيل السيرة الذاتية المغلوطة هي أشكال شائعة.
- الحل الرئيسي: التأسيس بالمواد المصدرية. قدِّم الحقائق المحددة في التعليمة باستخدام "وفقًا للبيانات أدناه: بيانات." هذا يُرسِّخ الإجابات في مواد محقَّقة بدلًا من معرفة النموذج.
- الحل الثانوي: القيود الصريحة. أضف تعليمات مثل "استخدم فقط المعلومات الواردة في السياق المقدَّم. لا تُضف معلومات من الخارج. إذا لم تكن متأكدًا، قل 'لا أملك هذه المعلومات.'". هذا يُعطِّل ميل النموذج لملء الفراغات.
- الحل الثالث: التوافق متعدد النماذج. أرسل التعليمة ذاتها إلى ٣ نماذج مستقلة أو أكثر. إذا أكَّد نموذج شيئًا لا تُؤكِّده النماذج الأخرى، فهذه إشارة للتحقق.
القيد ٣: لا استدلال موثوق متعدد الخطوات
لا تملك النماذج اللغوية الكبيرة ذاكرة عمل حقيقية — لا تستطيع الاحتفاظ بالنتائج الوسيطة بين تنبؤات الرموز. في مهام الحساب والمنطق والاستدلال، يُنتج هذا أخطاءً متراكمة: قد يحسب النموذج بشكل خاطئ في الخطوة ٣ ويبني على تلك الأساس الخاطئ للخطوات ٤-٨.
- الحل الرئيسي: صياغة تعليمات سلسلة التفكير. أضف "فكِّر خطوة بخطوة قبل تقديم إجابتك النهائية" أو عدِّد الخطوات صراحةً. هذا يُخرج الاستدلال إلى نافذة سياق النموذج، مما يجعل الخطوات الوسيطة مرئية وقابلة للتحقق.
- الحل الثانوي: التوجيه إلى مُفسِّر الكود. للحساب والإحصاءات أو المنطق الحتمي، أرشد النموذج لإنتاج كود Python، ثم شغِّل الكود. الكود لا يهلوس — يُنتج النتائج الرياضية الصحيحة.
القيد ٤: قيود نافذة السياق
كل نموذج لغوي كبير له حد أقصى من الرموز يستطيع معالجتها في استدعاء استنتاج واحد — يجمع التعليمة النظامية وتاريخ المحادثة والمستندات والرسالة الحالية. تجاوز هذا الحد يُقطِّع السياق السابق، مما يُدهور جودة المخرجات.
- الحل الرئيسي: RAG مع التقطيع. بدلًا من تمرير المستند كاملًا في التعليمة، قسِّم المستندات إلى أجزاء، وفهرس الأجزاء في قاعدة بيانات متجهة، واسترجع الأكثر صلة لكل طلب.
- الحل الثانوي: التلخيص التحادثي. في المحادثات متعددة الدورات، بعد كل ٥ دورات، اطلب من النموذج تلخيص تاريخ المحادثة واستبدل التاريخ الكامل بذلك الملخص. هذا يُقلِّل استخدام الرموز مع الاحتفاظ بالسياق الحرج.
القيد ٥: لا ذاكرة مستمرة
كل استدعاء لـ API النموذج اللغوي الكبير يبدأ من سياق فارغ. لا يتذكر النموذج المحادثات السابقة أو تفضيلات المستخدم أو المستندات السابقة أو أي نتائج من الجلسات الماضية. كل جلسة تبدأ من الصفر.
- الحل الرئيسي: حقن الذاكرة على مستوى التطبيق. استخدم قاعدة بيانات متجهة (Pinecone وWeaviate وpgvector) لتخزين ملخصات المحادثات السابقة والمعلومات ذات الصلة بالمستخدم. في بداية كل جلسة، استرجع السياق ذا الصلة وأدرجه في التعليمة النظامية.
- الحل الثانوي: ملخصات الجلسة. في نهاية كل جلسة، أرشد النموذج لتلخيص النقاط الرئيسية والقرارات. خزِّن هذا الملخص وابدأ الجلسة التالية بحقنه.
القيد ٦: لا قدرة على الإجراء في العالم الحقيقي
النماذج اللغوية الكبيرة افتراضيًا تُنتج نصًا فقط — لا تستطيع استدعاء APIs أو قراءة قواعد البيانات أو إرسال بريد إلكتروني أو التفاعل مع صفحات الويب أو تنفيذ أي إجراء حقيقي بمفردها. "فعل شيء ما" بالنسبة للنموذج اللغوي الكبير يعني إنتاج نص يصف كيفية القيام به.
- الحل: استدعاء الأدوات/الدوال. تدعم واجهات API الحديثة للنماذج اللغوية الكبيرة (GPT-5.5 وClaude Opus 4.8 وGemini 3.1 Pro) استخدام الأدوات، حيث يستطيع النموذج طلب تنفيذ دوال يُعرِّفها المطوِّر. يولِّد النموذج استدعاء أداة منظَّمًا؛ يُنفِّذ كودك الإجراء الحقيقي ويُعيد النتيجة للنموذج.
القيد ٧: التحيز في بيانات التدريب
يتكون مجموعة التدريب لكل نموذج لغوي كبير للأغراض العامة أساسًا من محتوى إنترنت إنجليزي من قبل عام 2025. هذا يُفرز تحيزات منهجية في معرفة النموذج وأسلوب استدلاله وافتراضاته الثقافية.
- الحل الرئيسي: تقديم السياق صراحةً. للتعليمات الخاصة بالمجال، أدرج المصطلحات ذات الصلة واصطلاحات التسمية أو المعرفة المتخصصة مباشرةً في التعليمة. "في سياق اللوائح المصرفية الأوروبية حيث تشير 'DORA' إلى..." تتجاوز الارتباطات التدريبية العامة.
- الحل الثانوي: أمثلة باللغة الهدف. للتعليمات بلغات غير إنجليزية، أدرج أمثلة على المخرج المطلوب بتلك اللغة. تتبع النماذج الأمثلة بشكل أكثر موثوقية من التعليمات النثرية للسلوكيات الخاصة باللغة.
القيد ٨: لا يستطيع التحقق الذاتي من المخرجات
لا تملك النماذج اللغوية الكبيرة وصولًا إلى المصدر الأصلي. لا تستطيع التحقق مما تُنتجه هل هو دقيق واقعيًا — تستطيع فقط تقييم ما إذا كان متسقًا مع أنماط التدريب. يمكن أن يكون الادعاء الخاطئ متسقًا داخليًا تمامًا كالادعاء الصحيح.
- الحل الرئيسي: التحقق الخارجي. لا تنشر مخرجات النموذج اللغوي الكبير حول الادعاءات الواقعية دون التحقق من الأرقام والتواريخ والأسماء والاستشهادات الرئيسية مقابل المصادر الأولية الموثوقة.
- الحل الثانوي: صياغة النقد الذاتي. بعد المخرج الأولي، اطلب من النموذج مراجعة مخرجه بحثًا عن التناقضات: "راجع إجابتك. حدِّد أي ادعاء قد يكون خاطئًا أو لا تستطيع التحقق منه من السياق المقدَّم." كثيرًا ما تكتشف النماذج أخطاءها الخاصة حين يُطلب منها التأمل.
كيف تتفاوت قيود النماذج اللغوية الكبيرة حسب المنطقة
قيود النماذج اللغوية الكبيرة شاملة هيكليًا، لكنها تتفاوت في الخطورة حسب اللغة والمنطقة والبيئة التنظيمية. يجب على المنظمات الأوروبية العاملة بموجب قانون الذكاء الاصطناعي الأوروبي (2024) توثيق قيود الذكاء الاصطناعي في تقييمات المخاطر لحالات الاستخدام عالية الخطورة.
في الصين، يشترك Baidu ERNIE 4.0 وAlibaba Qwen 3 في القيود الهيكلية ذاتها لكنهما يملكان بيانات تدريب موجَّهة نحو المصادر الصينية.
في اليابان، يُظهر Fujitsu Takane وLine HyperCLOVA X أداءً أقوى في المهام اليابانية مقارنةً بالنماذج متعددة اللغات العامة، لكن جميع القيود الهيكلية تُطبَّق بالتساوي.
قراءات ذات صلة
- RAG موضَّح — الحل الرئيسي لقطوع المعرفة والهلوسات
- هلوسات الذكاء الاصطناعي — لماذا تخترع الذكاء الاصطناعي الأشياء — تحليل عميق للقيد الثاني
- نوافذ السياق موضَّحة — لماذا تنسى الذكاء الاصطناعي — شرح تفصيلي لقيود الرموز
- كيف تعمل النماذج اللغوية الكبيرة فعلًا — معمارية المحوِّل والترميز وRLHF التي تُولِّد هذه القيود
- أتمتة أذكى للمنزل مع نموذج LLM محلي — أي قيود LLM تهمّ أكثر عند أتمتة مهام التحكم المنزلي وكيفية تصميم prompts حولها
- تواريخ انقطاع معرفة الذكاء الاصطناعي والبحث المباشر و GEO: الدليل الكامل — القيود الهيكلية بما فيها المعرفة المجمدة وغياب البحث المباشر
أسئلة شائعة
ما هي الأشياء الرئيسية التي لا تستطيع النماذج اللغوية الكبيرة فعلها؟
لا تستطيع النماذج اللغوية الكبيرة الوصول إلى البيانات في الوقت الحقيقي، أو التحقق من مخرجاتها، أو الاحتفاظ بالذاكرة بين الجلسات، أو تنفيذ إجراءات في العالم الحقيقي دون أدوات scaffolding، أو الاستدلال بشكل موثوق عبر منطق متعدد الخطوات دون صياغة سلسلة التفكير. هذه قيود هيكلية تُطبَّق على جميع النماذج.
لماذا تهلوس النماذج اللغوية الكبيرة؟
الهلوسة هيكلية: تتنبأ النماذج اللغوية الكبيرة بالرمز التالي الأكثر احتمالية إحصائيًا بناءً على بيانات التدريب، لا الحقيقة المحققة. حين تكون إشارة التدريب لحقيقة محددة شحيحة، يولِّد النموذج اختراعًا يبدو معقولًا دون الإشارة إلى عدم اليقين. تأسيس التعليمات بمواد مصدرية صريحة يُقلِّل لكن لا يُزيل الهلوسة.
هل يستطيع GPT-5.5 الوصول إلى الإنترنت؟
GPT-5.5 في API القياسية لا يستطيع الوصول إلى الإنترنت. توفِّر واجهة ChatGPT أداة تصفح اختيارية، لكن API النموذج الأساسي له قطع تدريب في أكتوبر 2024 ولا استرجاع مباشر. تحقق دائمًا مما إذا كانت طبقة استخدام أدوات نشطة في تكاملك المحدد قبل افتراض أن النموذج يملك بيانات حالية.
كيف تختلف قطوع المعرفة بين GPT-5.5 وClaude وGemini؟
اعتبارًا من 2026: OpenAI GPT-5.5 له قطع تدريب في أكتوبر 2024؛ Anthropic Claude Opus 4.8 وGoogle Gemini 3.1 Pro لهما قطوع في مطلع 2025. قد تكون المعرفة لدى النماذج الثلاثة غير دقيقة حول الأحداث القريبة من قطوعها، إذ تكون تغطية التدريب للأشهر الأخيرة شحيحة.
هل يمكنني حل قيود النماذج اللغوية الكبيرة عبر صياغة أفضل للتعليمات؟
تُقلِّل الصياغة من تأثير القيود لكن لا تُزيلها. تُحسِّن صياغة سلسلة التفكير دقة الاستدلال. تقديم الحقائق في التعليمة يُخفِّف قطوع المعرفة. تعليمات عدم اليقين الصريحة تُقلِّل ثقة الهلوسة. لكن الصياغة لا تستطيع منح النموذج وصولًا للبيانات في الوقت الحقيقي أو ذاكرة حقيقية أو قدرة الإجراءات في العالم الحقيقي.
هل النماذج المضبوطة دقيقًا لها القيود ذاتها؟
نعم. الضبط الدقيق يُعدِّل الأسلوب وتركيز المجال أو سلوك اتباع التعليمات — لا يُضيف وصولًا للبيانات في الوقت الحقيقي أو استدلالًا حقيقيًا أو ذاكرة مستمرة. GPT-5.5 المضبوط دقيقًا يحتفظ بقطع المعرفة ذاته وخطر الهلوسة ذاته كالنموذج الأساسي.
ما الفرق بين قيد النموذج اللغوي الكبير والخطأ؟
الخطأ هو عيب غير مقصود يمكن تصحيحه بتحديث برنامجي. القيد هو خاصية هيكلية لكيفية عمل النموذج. الهلوسة وقطوع المعرفة وقيود نافذة السياق هي قيود — تنشأ من معمارية المحوِّل وعملية التدريب ولا يمكن تصحيحها بالتصحيحات البرمجية، بل يمكن فقط التحايل عليها عبر تصميم النظام.
ما النموذج اللغوي الكبير الذي يملك أقل القيود؟
لا نموذج يُزيل أيًا من القيود الهيكلية الثمانية — فهي شاملة لمعمارية المحوِّل. Gemini 3.1 Pro يملك أكبر نافذة سياق (٢ مليون رمز) ويُخفِّف القيد الرابع بشكل أفضل. Claude Opus 4.8 يُقِرُّ بقطوع المعرفة بشكل أكثر موثوقية، مما يُخفِّف بذلك خطر الهلوسة. GPT-5.5 يتفوق في استخدام الأدوات (الحل للقيد السادس). اختر بناءً على نقطة اختناقك المحددة، لا بناءً على أي نموذج "أقل قيودًا".
كيف تختلف القيود بين النماذج مفتوحة المصدر والخاصة في 2026؟
النماذج مفتوحة المصدر (LLaMA 3.1 وMistral Large وQwen 3) والخاصة (GPT-5.5 وClaude Opus 4.8 وGemini 3.1 Pro) تواجه قيودًا هيكلية متطابقة. الاختلافات في الخطورة والتكلفة: النماذج الخاصة عادةً لها سياقات أكبر واتباع تعليمات أفضل وتحديثات تدريب أكثر تكرارًا. لا فئة تُزيل أيًا من القيود الثمانية.
المصادر والقراءات الإضافية
- Ji, Z. et al. (2023). "Survey of Hallucination in Natural Language Generation." ACM Computing Surveys. — تصنيف شامل لأنواع هلوسات النماذج اللغوية الكبيرة واستراتيجيات التخفيف
- Bubeck, S. et al. (2023). "Sparks of Artificial General Intelligence: Early experiments with GPT-4." arXiv:2303.12528. — تقييم منهجي لقدرات GPT-4 وقيوده
- Liu, N. et al. (2023). "Lost in the Middle: How Language Models Use Long Contexts." arXiv:2307.03172. — دليل على تدهور الأداء في الاسترجاع من وسط السياق