Key Takeaways
- Ollama: 가장 간편한 설치, 초보자에게 최적
- MLX: Apple Silicon에서 가장 빠름(15~25% 빠름)
- llama.cpp: 가장 많은 모델 포맷, 크로스 플랫폼
- 대부분의 사용자: Ollama로 시작하고, 속도가 필요하면 MLX로 전환하십시오
Ollama가 가장 쉬움(자동 Metal, REST API, 2분 설치); MLX는 15–25% 빠르고 Python + 파인튜닝 지원; llama.cpp는 가장 크로스플랫폼이며 GGUF 모델 지원이 가장 넓음 — 대부분의 Mac 사용자는 Ollama로 시작해 속도가 필요할 때 MLX로 전환합니다.
이것들은 Mac에서 AI 모델을 로컬로 실행할 수 있는 3개의 오픈소스 프로그램입니다. "Metal"은 Mac의 GPU(그래픽 칩)를 빠른 AI 처리에 사용한다는 의미입니다. GGUF는 다운로드 가능한 AI 모델의 가장 일반적인 파일 형식입니다. LoRA 파인튜닝은 처음부터 재학습하지 않고 자체 데이터로 모델을 학습시킬 수 있습니다.
1:1 비교
| 기능 | Ollama | MLX | llama.cpp |
|---|---|---|---|
| 설치 시간 | 2분 | 5분 | 10분 |
| Metal GPU | 자동 | 네이티브 | 지원됨 |
| 모델 포맷 | GGUF | MLX 포맷 | GGUF |
| API | REST (localhost:11434) | Python 네이티브 | CLI + HTTP |
| 속도 (8B Q4) | 45~50 tok/s | 55~65 tok/s | 45~55 tok/s |
| 속도 (70B Q4) | 12~16 tok/s | 18~22 tok/s | 14~18 tok/s |
| 파인튜닝 | 없음 | 있음 (LoRA) | 없음 |
| 최적 용도 | 초보자, API | ML 개발자 | 크로스 플랫폼 |
Apple Silicon에서 Ollama
- 단일 명령 설치: `brew install ollama`
- Metal GPU 자동 활성화 — 별도 설정 불필요
- 통합을 위한 REST API (모든 언어에서 사용 가능)
- 모델 관리: `ollama pull`, `ollama list`, `ollama rm`
- 제한사항: 파인튜닝 불가, 사용자 정의 양자화 불가
- 제한사항: GGUF 오버헤드로 인해 MLX보다 약간 느림
- 최적 용도: 초보자, API 사용자, Whisper 통합
Ollama 지원 모델 (100개 이상 큐레이션)
- Llama 3.3 (1B, 3B, 8B, 70B, 405B)
- Mistral Small, Mixtral 8x22B/22B
- Qwen3 (0.5B~72B)
- Phi-3, Phi-4
- Gemma 3 (4B, 12B, 27B)
- DeepSeek Coder V2
- 비전: Llama 3.2 Vision, LLaVA
- 임베딩: nomic-embed-text, mxbai-embed-large
MLX — Apple 네이티브 프레임워크
- Apple Silicon을 위해 Apple이 직접 개발
- NumPy 유사 Python API: `import mlx.core as mx`
- 지연 평가(Lazy evaluation) + 통합 메모리 = 최적 활용률
- MLX-LM: LLM 추론 및 파인튜닝 전용 패키지
- Apple Silicon에서 가장 빠른 추론 (Ollama보다 10~25% 빠름)
- Mac에서 직접 LoRA 및 QLoRA 파인튜닝 지원
- 제한사항: MLX 포맷 모델만 지원(라이브러리 지속 확장 중)
- 제한사항: macOS 전용 — 코드 이식 불가
- 최적 용도: ML 개발자, 최고 속도, 파인튜닝
MLX 지원 모델 (HuggingFace의 mlx-community)
- 모든 주요 LLM (Llama, Mistral, Qwen, Gemma, Phi)
- 양자화 버전 (Q3, Q4, Q5, Q6, Q8)
- 비전 모델: Llama 3.2 Vision, LLaVA, Qwen2-VL
- 참고: MLX 포맷으로 변환 필요(커뮤니티에서 대부분 변환 제공)
Apple Silicon에서 llama.cpp
- 크로스 플랫폼 C/C++ — Mac, Linux, Windows에서 동일한 바이너리 실행
- 빌드 플래그로 Metal 지원: `make LLAMA_METAL=1`
- GGUF 포맷: 가장 큰 모델 라이브러리
- 서버 모드: `./llama-server -m model.gguf` — REST API 제공
- 동일 작성자의 Whisper.cpp — Metal STT 지원
- 제한사항: 소스에서 빌드 필요(원클릭 설치 없음)
- 제한사항: MLX보다 느리고, Ollama와 비슷한 속도
- 최적 용도: 크로스 플랫폼 프로젝트, 최대 모델 포맷 지원
llama.cpp 지원 모델 (모든 GGUF)
- HuggingFace의 모든 GGUF 파일 사용 가능 (10,000개 이상)
- 파인튜닝 및 커스텀 모델의 가장 큰 생태계
- 오리지널/실험적 모델이 가장 먼저 등장
- 주류 모델(Llama, Mistral, Qwen)은 세 프레임워크 모두 지원합니다. 희귀하거나 실험적인 모델은 생태계 규모에서 llama.cpp가 우세합니다.
설치 비교: Llama 3.3 8B 실행을 위한 코드 5줄
Ollama (명령어 2개):
```bash
brew install ollama
ollama run llama3.3:8b "Hello, world"
```
MLX (Python 4줄):
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/Llama-3.1-8B-Instruct-4bit")
response = generate(model, tokenizer, prompt="Hello, world", max_tokens=100)
print(response)
```
llama.cpp (명령어 5개):
```bash
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make LLAMA_METAL=1
wget https://huggingface.co/ggml-org/models/resolve/main/llama-3.1-8b-q4.gguf
./main -m llama-3.1-8b-q4.gguf -p "Hello, world"
```
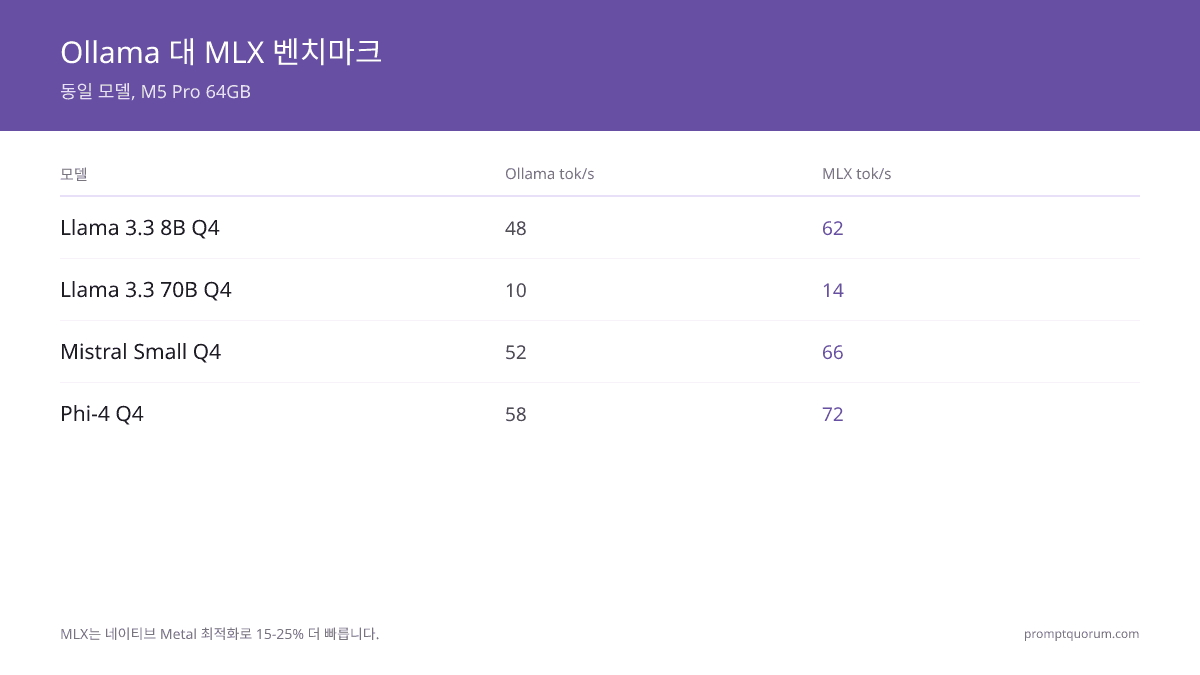
벤치마크: 동일 모델, 세 프레임워크, M5 Pro 64GB
| 모델 | Ollama tok/s | MLX tok/s | llama.cpp tok/s |
|---|---|---|---|
| Llama 3.3 8B Q4 | 48 | 62 | 52 |
| Llama 3.3 8B Q8 | 38 | 48 | 40 |
| Llama 3.3 70B Q4 | 10 | 14 | 11 |
| Mistral Small Q4 | 52 | 66 | 55 |
| Phi-4 Q4 | 58 | 72 | 60 |
MLX는 네이티브 Metal 최적화로 인해 15~25% 빠릅니다. 초기 벤치마크이며 프레임워크 개선이 예상됩니다.
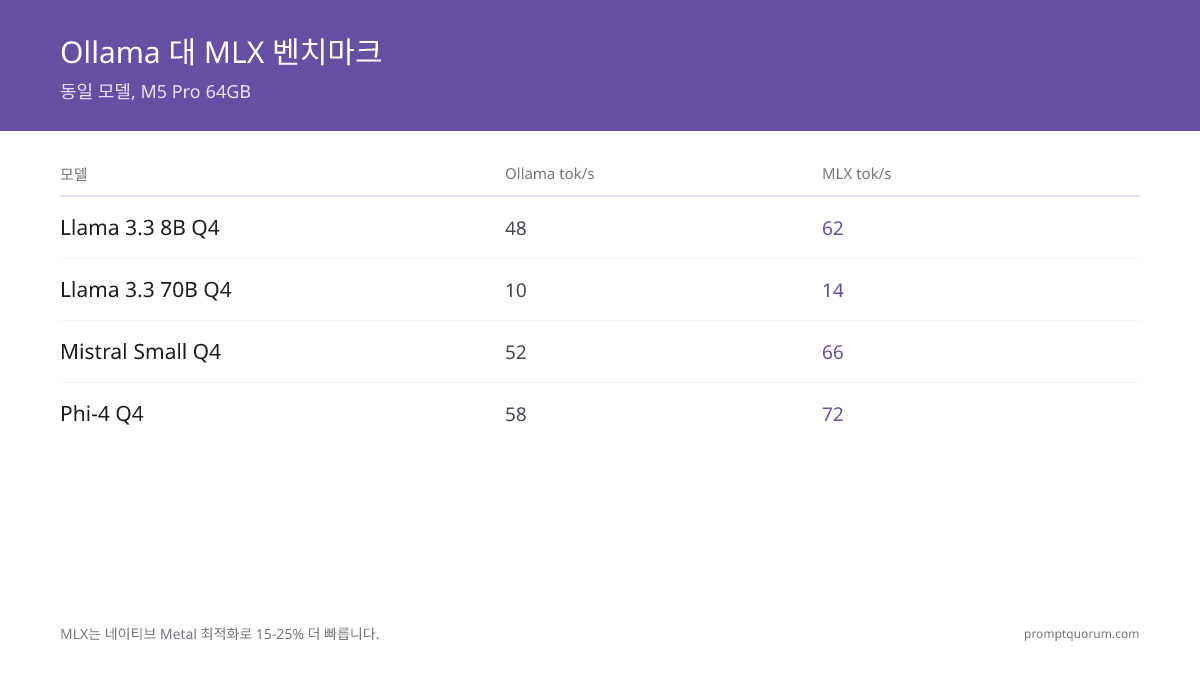
메모리 사용량: 동일 모델, 세 프레임워크 (M5 Pro 64GB)
| 모델 | Ollama RAM | MLX RAM | llama.cpp RAM |
|---|---|---|---|
| Llama 3.3 8B Q4 | 5.2 GB | 4.8 GB | 5.0 GB |
| Llama 3.3 70B Q4 | 43 GB | 41 GB | 42 GB |
| Mistral Small Q4 | 4.6 GB | 4.3 GB | 4.4 GB |
MLX는 통합 메모리 최적화로 인해 동일 모델에서 Ollama보다 5~10% 적은 메모리를 사용합니다. 메모리가 빠듯한 환경(16GB, 36GB)에서는 이 차이가 모델이 메모리에 올라가는지 스왑으로 넘어가는지를 결정할 수 있습니다.
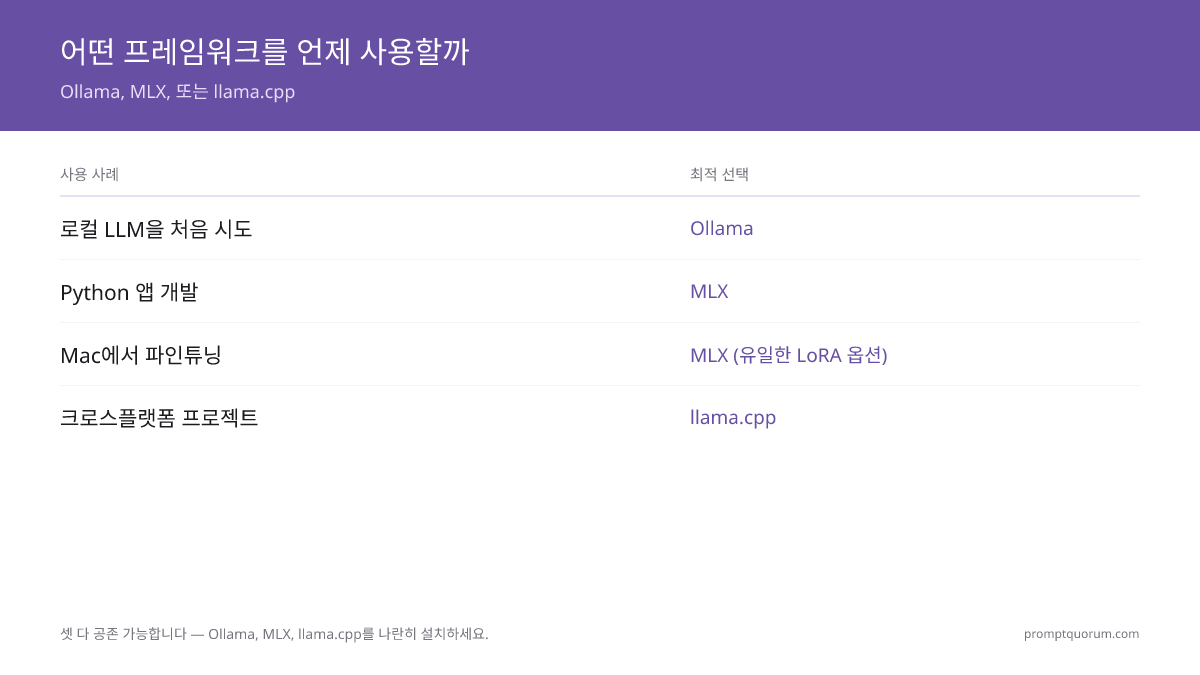
의사결정 매트릭스: 언제 무엇을 사용할까
- 1막 시작하는 경우
Why it matters: Ollama — 2분 설치, 즉시 작동합니다. - 2Python 앱 개발 시
Why it matters: MLX — 네이티브 Python, 최고 속도. - 3REST API가 필요한 경우
Why it matters: Ollama — 내장 API 서버 제공. - 4Mac에서 파인튜닝 시
Why it matters: MLX — LoRA 지원이 있는 유일한 옵션. - 5크로스 플랫폼 프로젝트
Why it matters: llama.cpp — Mac + Linux + Windows에서 동일한 코드 실행. - 6
- 7최고 속도가 필요한 경우
Why it matters: MLX — 대안보다 15~25% 빠름. - 8희귀 모델 사용 시
Why it matters: llama.cpp — 가장 큰 GGUF 모델 라이브러리.
각 프레임워크를 사용하지 말아야 할 때
Ollama를 사용하지 말아야 할 경우:
• 파인튜닝이 필요한 경우 (미지원)
• 마지막 한 방울의 속도까지 필요한 경우 (MLX보다 15~25% 느림)
• 완전한 사용자 정의 양자화가 필요한 경우 (제한된 제어)
MLX를 사용하지 말아야 할 경우:
• 크로스 플랫폼 배포가 필요한 경우 (macOS 전용)
• Python에 익숙하지 않은 경우
• 기본 REST API가 필요한 경우 (별도 래핑 필요)
• 프로덕션에서 비전 모델이 필요한 경우 (더 적은 선택지)
llama.cpp를 사용하지 말아야 할 경우:
• 원클릭 경험을 원하는 경우 (빌드 필요)
• 파인튜닝이 필요한 경우 (미지원)
• 직접 모델 다운로드를 관리하고 싶지 않은 경우
여러 프레임워크를 동시에 사용할 수 있습니까?
예 — 충돌하지 않습니다. 세 가지 모두 설치하십시오. 일반적인 패턴: 일상 사용에는 Ollama, 속도가 중요한 작업에는 MLX, Ollama/MLX에 없는 모델에는 llama.cpp. 세 가지 모두 동일한 기반 모델을 공유합니다(포맷만 다름).
어느 프레임워크가 가장 빠릅니까?
MLX이며, Apple Silicon에서 Ollama보다 15~25% 빠릅니다. llama.cpp는 Ollama와 비슷한 수준입니다. 속도 차이는 대형 모델(70B 이상)에서만 체감되며, 8B 모델에서는 세 가지 모두 충분히 빠릅니다.
나중에 프레임워크를 바꿀 수 있습니까?
예. 오늘 Ollama를 설치하고 내일 MLX로 전환할 수 있습니다. 모델은 호환됩니다(포맷만 다름). 종속성이 없습니다.
MLX는 Python 전용입니까?
MLX는 Python 네이티브 API를 갖고 있지만, subprocess나 HTTP 서버 래퍼를 통해 다른 언어에서도 호출할 수 있습니다. Python에서 사용하는 것이 가장 좋습니다.
Ollama에 GUI가 있습니까?
Ollama 자체는 CLI 전용입니다. 채팅 인터페이스를 위해 Open-WebUI 같은 오픈소스 프론트엔드를 사용하십시오.
Ollama와 MLX를 동시에 실행할 수 있습니까?
예. 서로 별도의 모델 디렉터리를 사용하며 충돌하지 않습니다. 많은 개발자들이 API 접근을 위해 Ollama를 백그라운드 서비스로 실행하면서 Python 노트북 실험에는 MLX를 사용합니다. 충분한 통합 메모리가 있다면 두 프레임워크가 동시에 메모리에 동일한 모델을 올려둘 수도 있습니다.
MLX는 Intel Mac에서 작동합니까?
아닙니다. MLX는 Apple Silicon(M1 이상) 전용으로 제작되었습니다. Intel Mac 사용자는 Ollama 또는 llama.cpp를 사용해야 합니다. 두 가지 모두 Intel에서 작동하지만 Metal GPU 가속 없이는 Apple Silicon보다 훨씬 느립니다.
비전 모델 지원이 가장 좋은 프레임워크는 어느 것입니까?
Ollama가 `ollama run llama3.2-vision`을 통해 가장 깔끔한 비전 모델 통합을 제공합니다. MLX도 비전 모델을 지원하지만 설정이 더 필요합니다. llama.cpp는 비전을 지원하지만 별도의 llava 실행 파일을 사용합니다. 멀티모달 작업에는 Ollama로 시작하십시오.
프레임워크 버전 및 최신성
• Ollama: 버전 0.7.x로 테스트 (2026년 6월 기준 최신)
• MLX: mlx-lm 0.22로 테스트
• llama.cpp: 2026년 6월 빌드로 테스트
• 마지막 검증: 2026-05-15
• 프레임워크 성능은 매달 개선됩니다 — 최신 수치를 위해 분기별로 다시 벤치마크하십시오