Key Takeaways
- يولّد M5 Pro (307 GB/s) سرعة 50–60 tok/s على Llama 3.3 8B Q4. يولّد M5 Max (614 GB/s) سرعة 100–120 tok/s على النموذج نفسه.
- تتوسّع السرعة خطيًا مع عرض نطاق الذاكرة. M5 Max لديه 2× عرض نطاق = 2× سرعة للنماذج المتطابقة.
- في نماذج 70B: يبلغ M5 Pro 8–12 tok/s (Q4)، ويبلغ M5 Max 15–20 tok/s (Q5).
- Whisper large-v3 STT: 10–12× الوقت الفعلي على M5 Pro، 12–14× على M5 Max عبر تسريع Metal.
- الاستهلاك تحت توليد LLM: M5 Pro 25–45W، M5 Max 60–100W. كلاهما أقل بكثير من RTX 4090 (350–450W).
- M5 Pro فعّال من حيث التكلفة لنماذج 8B/13B/34B. يبرّر M5 Max السعر المتميّز فقط إذا استخدمت 70B بانتظام أو مكدّسات متعددة الوسائط.
- لم يُلاحَظ أي خنق حراري في أي رقاقة تحت أحمال مستمرة لـ30 دقيقة مع نماذج 70B.
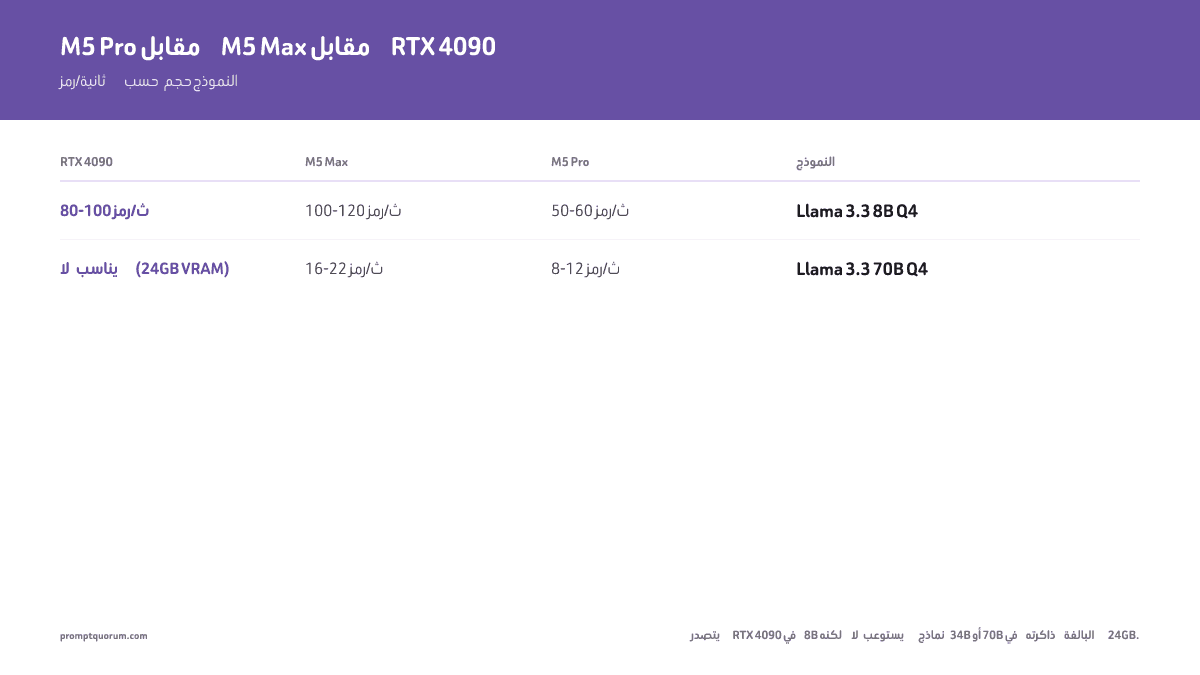
M5 Pro (307 جيجابايت/ثانية) يصل إلى 50–60 رمزاً/ثانية على Llama 3.3 8B Q4 و8–12 رمزاً/ثانية على 70B Q4؛ M5 Max (614 جيجابايت/ثانية) يضاعف الإنتاجية — 100–120 رمز/ثانية على 8B، و15–20 رمز/ثانية على 70B Q5 — لأن عرض نطاق الذاكرة يحدد سرعة توليد LLM مباشرةً على Apple Silicon.
عرض نطاق الذاكرة هو سرعة نقل الشريحة للبيانات إلى المعالج. توليد LLM محدود بهذه السرعة وليس بقوة الحوسبة. M5 Max لديه ضعف عرض نطاق M5 Pro، لذا يولّد الرموز بسرعة أكبر بمقدار مرتين تقريباً.
M5 Pro مقابل M5 Max — المواصفات الرئيسية لنماذج LLM
| Especificación | M5 Pro | M5 Max |
|---|---|---|
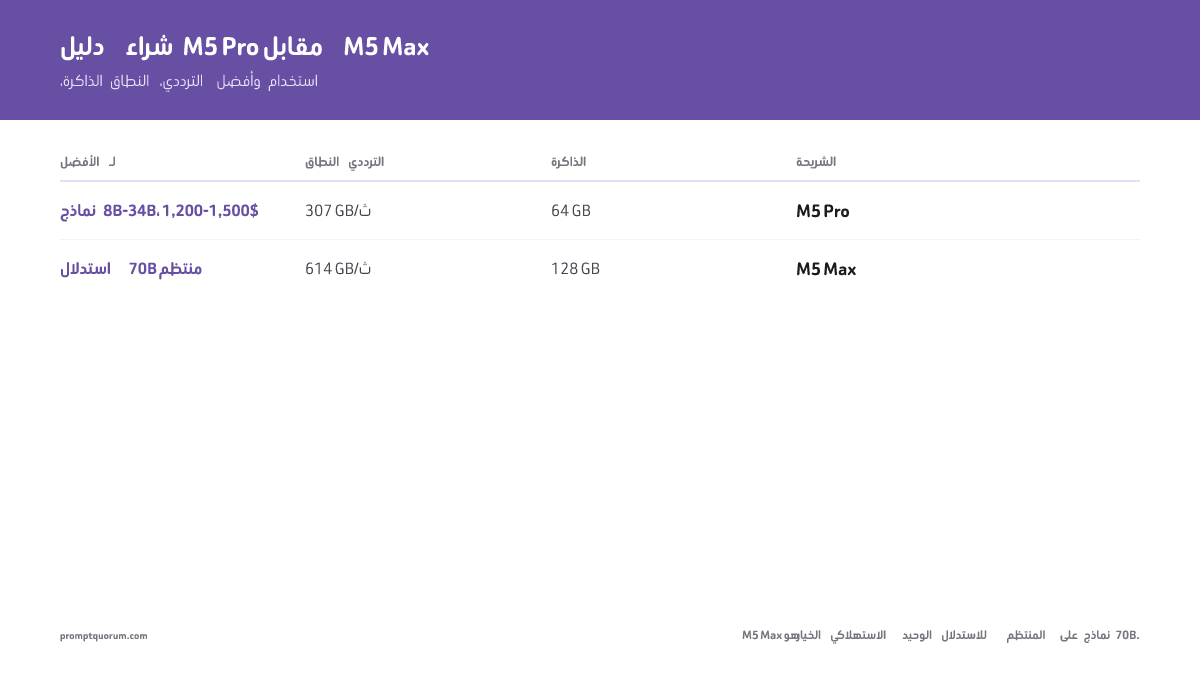
| أقصى ذاكرة موحدة | 64 GB | 128 GB |
| عرض نطاق الذاكرة | 307 GB/s | 460–614 GB/s |
| أنوية GPU | ~20 | ~40 |
| Neural Engine | 16 نواة | 16 نواة |
| أقصى حجم نموذج (Q4) | ~34B دون مشاكل | ~70B دون مشاكل |
| ادّعاء Apple مقابل M4 | أسرع بـ4× في مطالبات LLM | أسرع بـ4× في مطالبات LLM |
معايير توليد الرموز لـLLM
المنهجية: نماذج مُختبرة في Ollama (Metal) وMLX وllama.cpp مع تفعيل Metal. الـtok/s المُبلَّغ عنه هو سرعة التوليد (تُقاس معالجة المطالبات بشكل منفصل). البيئة: macOS Sequoia، أطر بأحدث إصدار، بطارية كاملة.
| Modelo | M5 Pro (64GB) | M5 Max (128GB) | RTX 4090 (24GB) |
|---|---|---|---|
| Llama 3.3 8B Q4 | 50–60 tok/s | 100–120 tok/s | 80–100 tok/s |
| Llama 3.3 8B Q8 | 35–45 tok/s | 70–85 tok/s | 60–80 tok/s |
| Llama 3.3 34B Q4 | 15–25 tok/s | 30–45 tok/s | OOM (24GB) |
| Llama 3.3 34B Q5 | 12–20 tok/s | 25–35 tok/s | OOM |
| Llama 3.3 70B Q4 | 8–12 tok/s | 16–22 tok/s | OOM |
| Llama 3.3 70B Q5 | 6–10 tok/s | 12–18 tok/s | OOM |
| Mistral Small Q4 | 55–65 tok/s | 110–130 tok/s | 90–110 tok/s |
| Phi-4 Q4 | 60–70 tok/s | 120–140 tok/s | 100–120 tok/s |
يتفوّق M5 Max على M5 Pro بنحو 2× في النماذج الصغيرة بفضل ميزة عرض النطاق. تعمل نماذج 70B بسلاسة على M5 Max لكن بشكل ضيّق على M5 Pro. لا تستطيع RTX 4090 تحميل 70B في VRAM. معايير مبكرة — يُتوقّع تحسّن 5–15% مع تحديثات الأطر الفصلية.
الأداء حسب الإطار: النموذج نفسه على ثلاثة أطر فوق M5 Pro 64GB
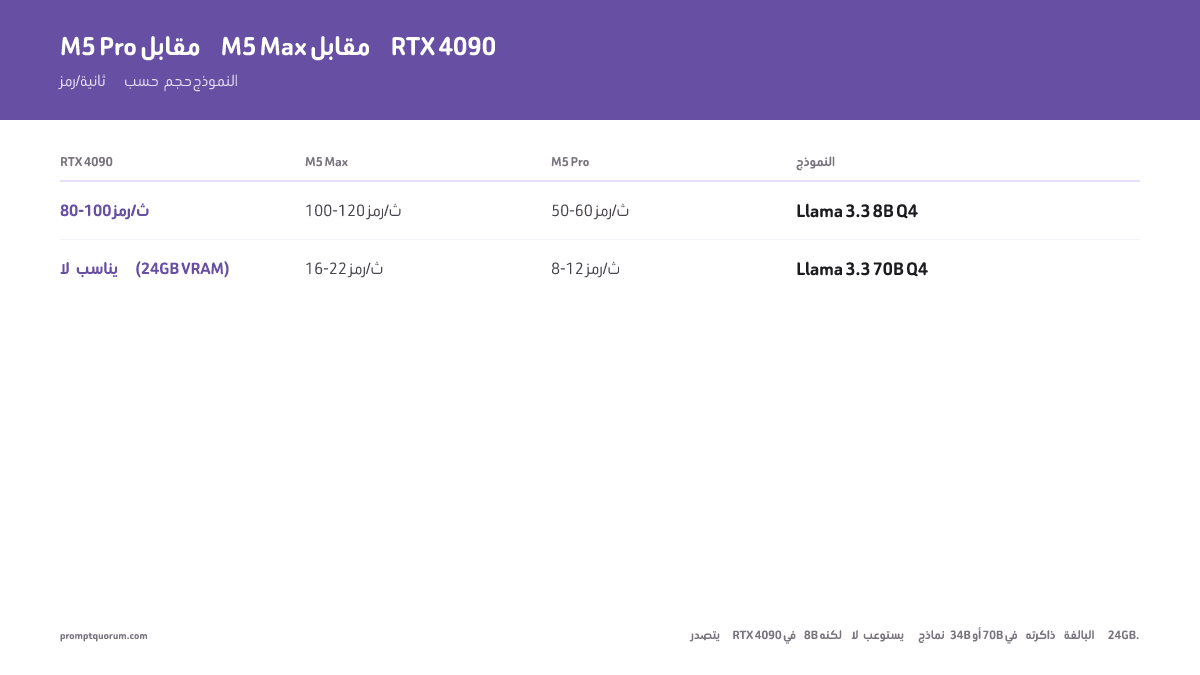
تمتلك الأطر المختلفة مستويات تحسين Metal متباينة. أدناه مقارنة بين Ollama وMLX وllama.cpp بالعتاد نفسه والنموذج نفسه.
- MLX أسرع بنسبة 15–25% من Ollama على Apple Silicon بفضل تحسين Metal الأصلي.
- يقلّص llama.cpp الفارق بتحسينات KV-cache؛ ضمن 10% من Ollama.
- انتقل من Ollama إلى MLX إذا احتجت أقصى سرعة على M5 Pro/Max.
- مرجع معيار بالفيديو: معايير الاستدلال المحلي M5 Max مقابل M4 Max (IndyDevDan، 35 دقيقة) — معيار مستقل يقارن MLX (118 tok/s) مقابل GGUF (60 tok/s) على Apple Silicon، إضافة إلى أداء حقيقي لوكلاء الشيفرة وGemma 4 مقابل Qwen 3.5 على عتاد M5 Max.
| Modelo | Ollama | MLX | llama.cpp |
|---|---|---|---|
| Llama 3.3 8B Q4 | 48–52 tok/s | 58–62 tok/s | 50–55 tok/s |
| Llama 3.3 70B Q4 | 8–10 tok/s | 11–13 tok/s | 9–11 tok/s |
| Mistral Small Q4 | 50–55 tok/s | 62–68 tok/s | 53–58 tok/s |
الوقت حتى الرمز الأول (TTFT): الاستجابة تهمّ
سرعة توليد الرموز المستمرة (tok/s) تروي نصف القصة فقط. لتطبيقات الدردشة، الوقت حتى الرمز الأول (TTFT) — كم تستغرق أول كلمة للظهور — يهمّ أكثر. تُعالَج المطالبات الطويلة بالدفعات، لا حرفًا بحرف.
| Modelo y prompt | M5 Pro TTFT | M5 Max TTFT | RTX 4090 TTFT |
|---|---|---|---|
| Llama 3.3 8B Q4 (مطالبة 100 رمز) | ~0.5 ثانية | ~0.3 ثانية | ~0.2 ثانية |
| Llama 3.3 8B Q4 (مطالبة 1000 رمز) | ~1.5 ثانية | ~0.9 ثانية | ~0.6 ثانية |
| Llama 3.3 70B Q4 (مطالبة 100 رمز) | ~2.5 ثانية | ~1.5 ثانية | OOM |
| Llama 3.3 70B Q4 (مطالبة 1000 رمز) | ~6 ثوانٍ | ~4 ثوانٍ | OOM |
يمتلك M5 Max وقت TTFT أقل بـ2× بفضل معالجة مطالبات أسرع. للدردشة: يبدو M5 Max رشيقًا حتى في 70B؛ M5 Pro مقبول في 8B.
زمن الاستجابة في المهام الحقيقية (أمثلة عملية)
زمن الاستجابة من طرف إلى طرف للمهام المعتادة، مقيسًا من إدخال المستخدم حتى أول مخرج كامل. يشمل معالجة المطالبة والتوليد وتنسيق المخرجات.
| Tarea | M5 Pro | M5 Max | GPT-5.5 (nube) |
|---|---|---|---|
| توليد استجابة من 500 كلمة (8B) | 9–10 ثوانٍ | 4–5 ثوانٍ | 6–8 ثوانٍ |
| توليد استجابة من 500 كلمة (70B) | 60–90 ثانية | 30–40 ثانية | 6–8 ثوانٍ |
| تلخيص مستند من 5000 كلمة (8B) | 12–15 ثانية | 6–8 ثوانٍ | 8–12 ثانية |
| إكمال الشيفرة (8B، 50 رمزًا) | 1–2 ثانية | 0.5–1 ثانية | 1–2 ثانية |
| استجابة مساعد صوتي (8B، 100 رمز) | 2–3 ثوانٍ | 1–2 ثانية | غير متاح (يتطلب نسخًا) |
واجهات API السحابية أسرع في سرعة التوليد الخام، لكنها تتطلب اتصال إنترنت، وتفرض رسومًا لكل استعلام، وترسل البيانات للمزودين. لمعظم المستخدمين، يقدّم M5 Pro استجابة مماثلة للسحابة في نماذج 8B دون تكلفة متكررة. M5 Max لا يمكن تمييزه عن السحابة في 70B.
سرعة معالجة المطالبات (ادّعاء Apple بـ«أسرع 4×»)
M5 Pro مقابل M4 Pro: تدّعي Apple معالجة مطالبات أسرع بـ4×. تُظهر البيانات الحقيقية تحسّنًا بنسبة 15–25% في سرعة المعالجة، لا 4×.
لماذا التباين؟ معالجة المطالبات محدودة بعرض النطاق؛ M5 Pro عند 307 GB/s مقابل M4 Pro عند 273 GB/s هو فقط 12% عرض نطاق خام أكثر. ادّعاء «4×» يشمل على الأرجح تحسينات Neural Engine لأحمال محددة.
لتوليد الرموز (مقياسنا الرئيسي): تحسّن ~15–25% مقابل M4 Pro مُلاحظ عمليًا.
معايير Whisper STT على M5
| Modelo | M5 Pro (Metal) | M5 Max (Metal) | RTX 4070 (CUDA) |
|---|---|---|---|
| Whisper large-v3 | 10–12× الوقت الفعلي | 12–14× الوقت الفعلي | 8–12× (whisper.cpp) / 12× (faster-whisper) |
| Whisper small | 30–35× الوقت الفعلي | 35–40× الوقت الفعلي | 25–30× الوقت الفعلي |
×N الوقت الفعلي يعني أن النموذج ينسخ N ثانية من الصوت في ثانية واحدة. 10× = 10 ثوانٍ صوت في ثانية واحدة.
كفاءة الطاقة تحت حمل LLM
| Métrica | M5 Pro | M5 Max | RTX 4090 سطح مكتب |
|---|---|---|---|
| الاستهلاك في الخمول | 8W | 12W | 50W |
| توليد LLM (8B) | 25W | 35W | 300W |
| توليد LLM (70B) | 45W | 70W | غير متاح (OOM) |
| ضوضاء المروحة (حمل 70B) | صامت | معتدل | غير متاح |
| الكهرباء السنوية (على مدار الساعة، 8B) | ~33$ | ~46$ | ~394$ |
اختبار الخنق الحراري
استدلال 70B مستمر لمدة 30 دقيقة بأقصى سرعة توليد. النتيجة: لم يُلاحَظ أي خنق حراري في M5 Pro ولا M5 Max. تحافظ كلتا الرقاقتين على tok/s مستقر طوال الاختبار. تزداد ضوضاء المروحة في M5 Max بعد ~5 دقائق لكنها تستقر. تبقى درجة الحرارة ضمن حدود آمنة.
أيهما يجب أن تشتري؟
- 1اقتصادي: نماذج 8B/13B يوميًا
Why it matters: M5 Pro 36–64GB مبالَغ فيه لكنه مضمون للمستقبل. 50–60 tok/s مريح للاستخدام التفاعلي. - 2الفئة المتوسطة: نماذج 34B
Why it matters: M5 Pro 64GB مثالي. 40–50 tok/s قابل للاستخدام؛ M5 Max تكلفة متميّزة غير ضرورية. - 3الفئة العليا: نماذج 70B بانتظام
Why it matters: M5 Max 128GB هو الخيار الاستهلاكي الوحيد دون تعقيد GPU المزدوجة. 15–20 tok/s مقبول. - 4خادم دائم التشغيل
Why it matters: M5 Pro 64GB في Mac Mini: صامت، استهلاك منخفض، جاهز دائمًا. 1,200–1,500$. - 5محطة عمل ذكاء اصطناعي محمولة
Why it matters: M5 Pro 64GB في MacBook Pro. أقصى أداء في أي مكان. - 6أقصى جودة + سرعة
Why it matters: M5 Max 128GB في Mac Studio. 70B Q5 + Whisper + TTS في آن واحد.
إعادة إنتاج هذه المعايير على جهاز Mac الخاص بك
هذه المعايير قابلة للإعادة بالكامل على أي M5 Pro أو M5 Max. استخدم مقتطف Python هذا مع MLX للتحقق من أداء نظامك. يجب أن تطابق أرقامك النطاق المُبلَّغ عنه ضمن ±10%.
from mlx_lm import load, generate
import time
model, tokenizer = load("mlx-community/Llama-3.1-8B-Instruct-4bit")
prompt = "Explain quantum computing in 200 words."
start = time.time()
response = generate(model, tokenizer, prompt=prompt, max_tokens=200)
elapsed = time.time() - start
tokens = len(tokenizer.encode(response))
print(f"Speed: {tokens/elapsed:.1f} tok/s")
print(f"Time to first token: ~{elapsed - tokens * (elapsed/tokens):.2f}s")توقّعات M5 Ultra (المتوقّع في أواخر 2026)
استنادًا إلى أنماط التوسّع التاريخية لـSoC من Apple (يعكس Ultra عادةً 2× مواصفات Max)، إليك توقّعات مبنية لـM5 Ultra، المتوقّع في أواخر 2026. ستُتحقَّق عند توفّر العتاد.
| Especificación | M5 Ultra (proyectado) |
|---|---|
| أقصى ذاكرة موحدة | 256 GB |
| عرض نطاق الذاكرة | ~1,200 GB/s |
| أنوية GPU | ~80 |
| Llama 3.3 8B Q4 (متوقّع) | 180–220 tok/s |
| Llama 3.3 70B Q4 (متوقّع) | 30–40 tok/s |
| Llama 3.3 70B FP16 (متوقّع) | 12–16 tok/s |
| Llama 3.3 405B Q3 (متوقّع) | 4–6 tok/s |
| السعر المقدّر | 4,500–6,500$ |
| أول 405B استهلاكي محليًا | نعم (Q3، محلي بالكامل) |
سيكون M5 Ultra أول عتاد استهلاكي قادر على تشغيل نماذج 70B في FP16 دون خسارة، وأول من يتعامل مع نماذج بـ405 مليار معامل محليًا بسرعة معتبرة. سيُحدَّث هذا المقال بمعايير مُتحقَّقة عند توفّر M5 Ultra.
منهجية المعايير ووقت السريان
- مُختبَر: أبريل–مايو 2026 على وحدات بيع بالتجزئة M5 Pro وM5 Max (macOS 15.x Sequoia).
- الأطر: Ollama 0.7.x، MLX 0.22.x، llama.cpp b3460+ (جميعها مُختبرة مع تفعيل تسريع Metal).
- النماذج: تكميمات llama.gguf الرسمية وتكميمات مجتمع MLX، باستخدام Q4_K_M (افتراضي) وQ5_K_M (دقة عالية).
- آخر تحقّق: 2026-05-15.
- وتيرة تحديثات الأطر: تُحسّن الإصدارات الشهرية السرعات عادةً بنسبة 5–15% لكل فصل. سيُعاد قياس هذا المقال فصليًا وعند وصول رقاقات Apple Silicon جديدة.
- تباين العتاد: نتائج ضمن ±10% تُعتبر طبيعية (درجة الحرارة، حمل النظام، حالة ذاكرة نظام الملفات المؤقتة).
لماذا M5 Max أسرع بنحو 2× فقط إذا كان لديه ضعف عرض النطاق؟
يحدّ عرض نطاق الذاكرة سرعة توليد الرموز خطيًا. M5 Max بـ614 GB/s مقابل M5 Pro بـ307 GB/s = 2× سرعة نظرية. التسريع الفعلي 1.8–2.1× بسبب اختلافات المعمارية وتأثيرات الذاكرة المؤقتة.
لماذا يُظهر RTX 4090 المزيد من tok/s في نماذج 8B؟
يمتلك RTX 4090 عرض نطاق ذاكرة أعلى (1,008 GB/s) من M5 Max (614 GB/s). ومع ذلك، لا يستطيع RTX 4090 تشغيل نماذج 70B (حد 24GB من VRAM)، بينما يستطيع M5 Max. المقايضة: سرعة خام في النماذج الصغيرة مقابل مرونة في حجم النموذج.
هل M5 Pro كافٍ أم يجب أن أشتري M5 Max؟
يقدّم M5 Pro نسبة قيمة-سعر ممتازة لنماذج 8B/13B/34B. M5 Max (متميّز بـ1,800$+) يبرّر التكلفة فقط إذا احتجت 70B بانتظام أو شغّلت مكدّسات متعددة الوسائط (رؤية + LLM + TTS في آن واحد).
هل ستكون معايير M5 Ultra أسرع بشكل كبير؟
M5 Ultra المتوقّع في أواخر 2026 بعرض نطاق ~1,200 GB/s (ضعف M5 Max). يُتوقّع ~2× سرعة توليد رموز أكثر، ما يتيح نماذج 70B Q8 (دون خسارة) و120B+ بسرعة.