핵심 요점
- M5 Max 128GB: Llama 3 8B Q4_K_M ~75 tok/s; Llama 3 70B Q4_K_M ~18 tok/s (메모리에 탑재 가능)
- RTX 4090 24GB: Llama 3 8B ~150 tok/s; Llama 3 70B는 탑재 불가 (~38GB VRAM 필요)
- 70B 용량 비용: Mac Studio M4 Max 64GB ~$3,199 vs 2× RTX 4090 시스템 ~$7,000
- 전력: Apple 25–35W; RTX 4090 시스템 ~450W — 약 10× 차이
- 소프트웨어: NVIDIA 우세 (CUDA, PyTorch, vLLM, TensorRT-LLM); Apple 성장 중 (MLX, mlx-lm)
- 학습/파인튜닝: NVIDIA가 본격적인 작업에 유일하게 실용적인 옵션
- 휴대성: MacBook Pro M5는 배터리로 14B 모델 실행 가능; 비교할 만한 NVIDIA 노트북 없음
📍 한 문장으로
Apple MLX는 70B 이상 모델 추론 및 에너지 효율성에서 우세하며, NVIDIA CUDA는 7–14B 모델의 순수 추론 속도 및 학습 생태계에서 우세합니다.
💬 쉽게 말하면
Apple Silicon은 큰 트렁크를 가진 하이브리드 전기차와 같습니다 — 에너지를 적게 소비하면서 거대한 모델을 탑재합니다. NVIDIA는 스포츠카와 같습니다 — 매우 빠르지만 소형 모델에만 적합하며 전력 소비가 많습니다.
📌Note: 벤치마크 수치는 커뮤니티 테스트(2026년 5월) 기반이며 ±10–15% 오차가 있습니다. 결과는 양자화, 컨텍스트 길이, 시스템 부하에 따라 달라집니다.
2026년에 이 비교가 중요한 이유
Apple Silicon M5는 최대 128GB 통합 메모리와 함께 출시되었습니다 — 소비자 가격에서 처음으로 Mac에서 대형 모델 추론이 실용적으로 가능해졌습니다. NVIDIA RTX 5090은 32GB GDDR7 VRAM을 $3,949에 출시했습니다. 완전히 다른 두 아키텍처가 이제 동일한 오픈소스 모델 실행을 두고 경쟁하고 있습니다.
📍 한 문장으로
2026년 현재, Apple Silicon과 NVIDIA 이산 GPU는 로컬에서 대규모 언어 모델을 실행하기 위한 두 가지 완전히 다른 하드웨어 철학을 나타냅니다.
💬 쉽게 말하면
Apple에서는 CPU, GPU, RAM이 동일한 메모리 풀을 공유합니다 — 128GB Mac Studio는 70B 모델을 한 번에 로드할 수 있습니다. NVIDIA는 별도의 VRAM을 사용합니다; 단일 RTX 4090(24GB)은 70B 모델을 전혀 로드할 수 없습니다.
- Apple M5 Max: CPU와 GPU 간 공유된 통합 메모리 최대 128GB
- NVIDIA RTX 5090: $3,949에 32GB GDDR7 — 가장 빠른 소비자용 이산 GPU
- Llama 3 70B Q4_K_M 양자화는 ~38GB 메모리 필요
- Apple에서: 하나의 장치로 처리 가능. NVIDIA에서: 2× RTX 4090 또는 CPU 오프로딩 필요
💡Tip: 목표 모델이 40B 이상 파라미터라면 Apple MLX를 선택하십시오. 7–14B 모델에서 최대 토큰/초 성능이 필요하거나 파인튜닝이 필요하다면 NVIDIA CUDA를 선택하십시오.
모든 것을 바꾸는 아키텍처 차이점
Apple Silicon과 NVIDIA GPU는 근본적으로 다른 메모리 아키텍처를 기반으로 구축되었습니다. 이 단일한 차이점 — 공유 메모리 대 전용 메모리 — 이 어떤 모델을 실행할 수 있는지와 그 속도를 결정합니다.
📍 한 문장으로
Apple Silicon은 CPU, GPU, Neural Engine 간에 공유된 통합 메모리를 사용하며, NVIDIA는 PCIe 버스로 연결된 GPU 카드의 전용 GDDR7 VRAM을 사용합니다.
💬 쉽게 말하면
NVIDIA는 시스템 RAM과 GPU VRAM의 두 개의 분리된 뱅크를 가지고 있습니다. 데이터를 그 사이에서 이동하는 것은 느립니다. Apple은 모든 것이 공유하는 하나의 뱅크를 가지고 있습니다 — 복사 없음, 병목 없음.

💡Tip: NVIDIA는 달러당 순수 대역폭에서 우세하며, Apple은 총 메모리 용량에서 우세합니다. LLM의 경우 총 메모리가 탑재 가능한 모델을 결정하고, 대역폭이 해당 제약 내에서의 속도를 결정합니다.
Apple Silicon이 NVIDIA의 메모리 대역폭에 필적할 수 있습니까?
아니오 — RTX 4090은 1,008 GB/s인 반면 Apple M5 Max는 614 GB/s입니다. Apple은 훨씬 더 큰 메모리 용량(24GB 대비 128GB)으로 이를 보완합니다. VRAM으로 충분한 소형 모델의 경우 NVIDIA가 속도에서 우세합니다. VRAM을 초과하는 대형 모델의 경우 Apple이 용량에서 우세합니다.
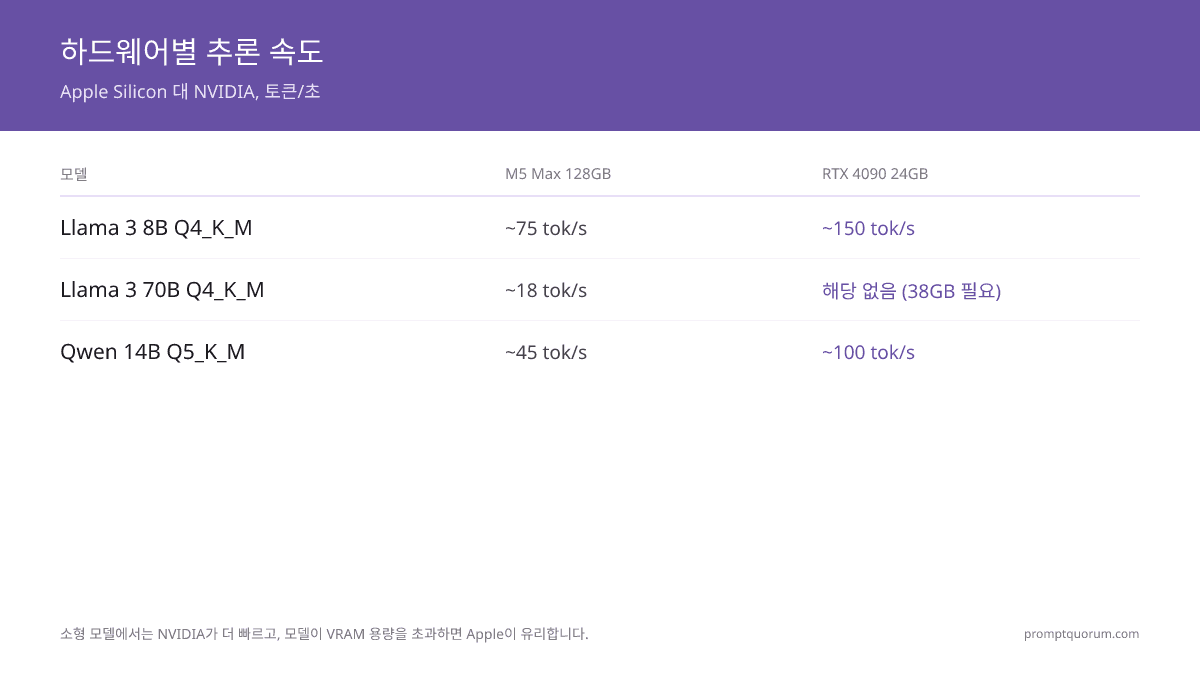
성능 벤치마크: 모델별 토큰/초
추론 속도는 토큰/초(tok/s)로 측정됩니다 — 높을수록 대화형 사용에 좋습니다. NVIDIA는 소형 모델에서 속도가 우세하며, Apple은 모델이 VRAM 용량을 초과할 때 우세합니다.
📍 한 문장으로
RTX 4090은 Llama 3 8B Q4_K_M에서 ~150 tok/s에 달하며, Apple M5 Max 128GB는 동일 모델에서 ~75 tok/s를 실행하지만 RTX 4090이 탑재할 수 없는 Llama 3 70B도 ~18 tok/s로 실행합니다.
💬 쉽게 말하면
RTX 4090은 7B 모델에서 두 배 빠르지만 70B 모델을 물리적으로 탑재할 수 없습니다. M5 Max는 소형 모델에서 더 느리지만 어떤 단일 NVIDIA 카드도 처리할 수 없는 대형 모델을 실행할 수 있습니다.
| 모델 | M5 Max 128GB | M5 Pro 48GB | RTX 5090 32GB | RTX 4090 24GB | RTX 4070 Ti S. 16GB | RTX 3060 12GB |
|---|---|---|---|---|---|---|
| Llama 3 8B Q4_K_M | ~75 tok/s | ~65 tok/s | ~145 tok/s | ~150 tok/s | ~95 tok/s | ~55 tok/s |
| Llama 3 70B Q4_K_M | ~18 tok/s ✓ | 탑재 불가 (38GB 필요) | 탑재 불가 (32GB < 38GB 필요) | 탑재 불가 (38GB 필요) | 탑재 불가 | 탑재 불가 |
| Qwen 14B Q5_K_M | ~45 tok/s | ~38 tok/s | ~130 tok/s | ~100 tok/s | ~58 tok/s | 탑재 불가 (12GB 한계) |
| Mixtral 8×7B Q4_K_M | ~22 tok/s | ~15 tok/s | ~95 tok/s ✓ | ~65 tok/s | 탑재 불가 (~26GB 필요) | 탑재 불가 |
| Llama 3 8B Q8_0 | ~55 tok/s | ~45 tok/s | ~165 tok/s | ~110 tok/s | ~65 tok/s | 탑재 불가 (~9GB 필요) |

📌Note: 벤치마크는 mlx-community 및 llama.cpp 커뮤니티 테스트(2026년 5월)에서 수집되었습니다. 값은 ±10–15% 근사치입니다. 정확한 수치는 자신의 하드웨어에서 llama-bench를 실행하여 확인하십시오.
💡Tip: Llama 3 8B Q4_K_M을 기준 벤치마크로 사용하십시오 — 가장 많이 테스트된 모델이며 플랫폼 간 신뢰할 수 있는 비교를 제공합니다.
Llama 3 70B에서 18 tok/s는 대화형 사용에 충분합니까?
대부분의 작업에서 그렇습니다. 18 tok/s는 500단어 응답을 약 20–25초에 생성합니다. 이전에 $40,000 이상의 서버가 필요했던 70B 품질의 대화형 사용이 이제 Mac Studio M4 Max ~$3,199에서 가능합니다.
NVIDIA가 소형 모델에서 더 빠른 이유는 무엇입니까?
NVIDIA의 GDDR7/GDDR6X 대역폭(1,008–1,792 GB/s)이 Apple M5 Max(614 GB/s)를 능가합니다. LLM 추론은 메모리 대역폭에 제한을 받습니다 — 대역폭이 높을수록 소형 모델이 더 빠릅니다. Apple의 강점은 용량에 있고 대역폭에 있지 않습니다.
비용 비교: 모델 크기별 총 시스템 비용
총 시스템 비용에는 NVIDIA의 경우 GPU 카드 플러스 PC가 포함되며, Apple의 경우 Mac만 포함됩니다. Apple이 더 저렴해지는 교차점은 70B 모델 수준입니다.
📍 한 문장으로
NVIDIA는 7–14B 모델에서 더 저렴하며 (RTX 3060 12GB + PC ~$800), Apple은 70B 모델에서 더 저렴합니다 (Mac Studio M4 Max 64GB ~$3,199 vs 2× RTX 4090 시스템 ~$7,000).
💬 쉽게 말하면
소형 모델은 NVIDIA에 유리합니다 (GPU를 구매해서 연결하면 됩니다). 대형 모델은 Apple에 유리합니다 (전체 커스텀 PC에 두 개의 그래픽 카드 대신 하나의 장치).
| 목표 모델 | Apple 옵션 | Apple 가격 | NVIDIA 옵션 | NVIDIA 가격 | 더 저렴 |
|---|---|---|---|---|---|
| 7B 모델 | Mac Mini M4 24GB | $1,599 | RTX 3060 12GB + PC | ~$800 | NVIDIA (2×) |
| 14B 모델 | Mac Mini M4 Pro 48GB | $2,199 | RTX 4060 Ti 16GB + PC | ~$1,200 | NVIDIA (1.8×) |
| 32B 모델 | Mac Mini M4 Pro 48GB | $2,199 | RTX 5090 32GB + PC | ~$5,500 | Apple (2.5×) |
| 70B 모델 | Mac Studio M4 Max 64GB | ~$3,199 | 2× RTX 4090 + PC | ~$7,000 | Apple (2.2×) |
| 120B+ 모델 | Mac Studio M5 Ultra 192GB | $8,999 | 4× A100 40GB 서버 | ~$40,000+ | Apple (4.4×) |

💡Tip: 32B 수준의 변곡점이 중요합니다: RTX 5090 32GB는 카드만 ~$3,949에 시스템 비용 $1,500+ 추가입니다. Mac Mini M4 Pro 48GB는 $2,199 전체 비용으로 32B를 처리합니다. 예산형 빌드에 대해서는 로컬 LLM을 위한 최고의 저예산 GPU를 참조하십시오.
📌Note: 2026년 5월 기준 근사 가격입니다. NVIDIA GPU 가격은 재고에 따라 변동됩니다. Apple 가격은 고정되어 있습니다.
소프트웨어 생태계: NVIDIA가 여전히 우세
NVIDIA의 CUDA 생태계는 15년간 성숙해 왔습니다. 모든 관련 ML 프레임워크, 추론 서버, 파인튜닝 도구가 CUDA에서 기본적으로 실행됩니다. Apple MLX는 빠르게 성장하고 있지만 아직 추론에만 초점을 맞추고 있습니다.
📍 한 문장으로
NVIDIA CUDA는 PyTorch, vLLM, TensorRT-LLM, llama.cpp, Ollama를 기본 지원하며, Apple MLX는 mlx-lm, LM Studio, MLX 백엔드를 통한 Ollama를 지원합니다 — macOS 전용입니다.
💬 쉽게 말하면
CUDA는 ML의 Windows와 같습니다 — 모든 것이 그 위에서 실행됩니다. MLX는 macOS와 같습니다 — 세련되고 효율적이지만 모든 도구가 사용 가능하지 않으며 생태계를 벗어날 수 없습니다.
⚠️Warning: 모델 파인튜닝이나 학습을 계획하고 있다면 NVIDIA CUDA가 유일한 실용적인 옵션입니다. Apple MLX는 mlx-lm을 통한 LoRA 파인튜닝을 지원하지만 전체 파라미터 파인튜닝, RLHF, DPO는 아직 Apple Silicon에서 성숙하지 않았습니다.
💡Tip: Hugging Face의 대부분 모델에는 이미 GGUF(크로스 플랫폼) 및 MLX 형식 변형이 모두 있습니다. mlx-community 조직은 사전 양자화된 모델을 제공하므로 수동 변환이 필요하지 않습니다.
Ollama를 Apple과 NVIDIA 모두에서 사용할 수 있습니까?
그렇습니다. Ollama는 Apple Silicon(Metal 백엔드)과 NVIDIA(CUDA) 모두에서 실행됩니다. 동일한 명령이 두 플랫폼에서 작동합니다. 모델 파일은 플랫폼 간 호환됩니다.
llama.cpp가 Apple Silicon에서 작동합니까?
그렇습니다 — llama.cpp는 Apple Silicon에서 기본 Metal GPU 가속을 사용합니다. MLX 특화 최적화를 위해서는 mlx-lm을 직접 사용하거나 MLX 백엔드를 활성화한 LM Studio를 사용하십시오.
전력 소비 및 소음: Apple이 명확하게 우세
전력 소비는 Apple Silicon의 가장 명확한 장점 중 하나입니다. $0.15/kWh에서 하루 8시간 실행 시 M4 Max와 RTX 4090 시스템의 차이는 연간 $220 이상입니다.
📍 한 문장으로
Mac Studio M4 Max는 로컬 LLM 실행 시 25–35W를 사용하며, RTX 4090 시스템은 ~450W를 사용합니다 — 하루 8시간, $0.15/kWh 기준 연간 ~$22 대 ~$248의 전기 비용입니다.
💬 쉽게 말하면
RTX 4090 시스템은 많은 스트리밍 구독을 합친 것보다 연간 전기 요금이 더 많이 듭니다. Mac Studio는 매월 $2 미만으로 운영됩니다.
| 시스템 | 부하 시 최대 전력 | 연간 비용 (8시간/일, $0.15/kWh) | 소음 |
|---|---|---|---|
| Mac Studio M4 Max | 25–35W | ~$22/년 | 무음 |
| MacBook Pro M5 Max | 30–40W | ~$26/년 | 거의 무음 |
| RTX 3060 시스템 | ~200W | ~$110/년 | 보통 수준의 팬 소음 |
| RTX 4090 시스템 | ~450W | ~$248/년 | 부하 시 소음 큼 |
| RTX 5090 시스템 | ~600W | ~$329/년 | 매우 소음 큼 |
💡Tip: 홈 오피스나 방에서 작업하는 경우 소음은 비용만큼 중요합니다. Mac Studio는 완전 무음으로 LLM을 실행합니다. RTX 4090 시스템은 수 미터 떨어진 곳에서도 들리는 능동 냉각이 필요합니다.
Apple MLX가 NVIDIA보다 10배 더 에너지 효율적입니까?
지속적인 추론 시 대략 그렇습니다. Mac Studio M4 Max는 25–35W를 소비하는 반면 RTX 4090 시스템은 400–500W를 소비합니다. 효율성 비율은 작업 부하에 따라 8–15×입니다. 유휴 상태에서는 NVIDIA 시스템이 전력을 줄여 차이가 좁아집니다.
사용 사례별 권장 사항: 어떤 시스템을 선택할까
적합한 하드웨어는 전적으로 목표 모델 크기와 워크플로우에 달려 있습니다. 다음은 명확한 직접적인 권장 사항입니다.
📍 한 문장으로
70B+ 모델, 조용한 작동, 또는 휴대용 추론에는 Apple Silicon을 선택하고, 7–14B에서의 최대 성능, 학습, 멀티 GPU 확장, 또는 $1,000 미만 예산에는 NVIDIA CUDA를 선택하십시오.
💬 쉽게 말하면
Llama 3 70B를 비공개로 저렴하게 실행하고 싶다면 오늘날 Apple이 유일한 실용적 선택입니다. $1,500 미만 예산으로 가장 빠른 7B 어시스턴트를 원한다면 NVIDIA가 우세합니다.
💡Tip: 가장 중요한 질문: 대화형 속도로 필요한 가장 큰 모델은 무엇입니까? 70B 이상이라면 Apple이 자동으로 우세합니다. 7–30B라면 예산에 따라 가격을 비교하십시오.
하이브리드 방식: 두 가지 모두 사용
많은 고급 사용자가 두 가지를 모두 사용합니다: 휴대용 추론을 위한 MacBook와 학습을 위한 NVIDIA 데스크탑. Ollama의 크로스 플랫폼 지원 덕분에 이것이 실용적입니다 — 두 시스템에서 동일한 명령과 동일한 모델 파일을 사용합니다.
📍 한 문장으로
고급 사용자의 일반적인 구성은 휴대용 14B 추론을 위한 MacBook Pro M5와 LoRA 파인튜닝 및 고성능 배치 작업을 위한 RTX 4090 Linux 워크스테이션입니다.
💬 쉽게 말하면
이동 중에는 Mac을 사용하십시오. 야간 파인튜닝 실행 및 대량 서비스에는 데스크탑 GPU를 사용하십시오.
- Ollama는 Apple과 NVIDIA 모두에서 동일한 명령을 실행합니다 —
ollama run llama3.2가 두 곳에서 작동 - LM Studio는 동일한 인터페이스에서 MLX (macOS) 및 CUDA 백엔드를 모두 지원
- GGUF 모델 파일 (llama.cpp 형식)은 크로스 플랫폼; MLX 모델은 Apple 전용
- 일반적인 워크플로우 분리: 비공개 추론은 Mac, 학습 및 배치 처리는 NVIDIA
- LAN 서버: NVIDIA 서버에서 Ollama를 실행하고 로컬 네트워크를 통해 Mac에서 접근
💡Tip: 하나의 시스템만 구입할 수 있다면: 7B 작업을 위해 NVIDIA로 시작하고 (더 저렴), 70B가 필요할 때 Mac Studio로 업그레이드하십시오. 두 결정 모두 해당 수준에서 비용 효율적입니다.
미래 전망: 2026–2027
두 플랫폼 모두 빠르게 개선되고 있습니다. 2027년의 핵심 질문은 NVIDIA가 소비자 카드에 70B 모델을 탑재할 만큼 충분한 VRAM을 넣을 것인지, 아니면 Apple의 통합 메모리 이점이 유지될 것인지입니다.
📍 한 문장으로
Apple M6는 통합 메모리 용량을 더욱 확장할 것으로 예상되며, 차세대 NVIDIA는 소비자용으로 48GB VRAM을 초과할 수 있어 대형 모델 이점을 크게 재조정할 수 있습니다.
💬 쉽게 말하면
2027년에 NVIDIA가 $3,000에 64GB VRAM GPU를 출시한다면 Apple의 70B 수준 비용 논거는 무너집니다. Apple이 256GB 통합 메모리를 갖춘 M6를 출시한다면 이점이 더욱 확대됩니다.
💡Tip: NVIDIA가 $3,000 미만에 소비자용 48GB+ 카드를 출시한다면 이 비교를 재확인하십시오. 70B+ 모델에 대한 현재 Apple의 이점은 현재 32GB VRAM 상한에 달려 있습니다.
최종 판정 표: Apple vs NVIDIA 요소별 비교
이 표를 사용하여 워크플로우에 가장 중요한 것을 기반으로 직접적인 결정을 내리십시오.
📍 한 문장으로
Apple이 11가지 요소 중 5가지에서 우세(대형 모델, 70B 수준 비용, 에너지 효율, 소음, 휴대성); NVIDIA가 5가지에서 우세(소형 모델 속도, $1K 미만 비용, 소프트웨어, 학습, 크로스 플랫폼); 미래 준비성에서 동점.
| 요소 | 우세 | 이유 |
|---|---|---|
| 대형 모델 추론 (70B+) | Apple | Mac Studio M4 Max 64GB ~$3,199 vs 2 GPU 시스템 $7,000+ |
| 소형 모델 속도 (7–14B) | NVIDIA | RTX 4090: ~150 tok/s vs M5 Max: ~75 tok/s |
| $1,000 미만 비용 | NVIDIA | RTX 3060 + PC ~$800 vs 가장 저렴한 Mac $1,599 |
| 70B 모델 비용 | Apple | Mac Studio M4 Max 64GB ~$3,199 vs 2× RTX 4090 + PC ~$7,000 |
| 에너지 효율성 | Apple | 25–35W vs 450W — 8–15배 더 효율적 |
| 소음 | Apple | 무음 vs 필요한 소음 큰 능동 냉각 |
| 소프트웨어 생태계 | NVIDIA | CUDA가 PyTorch, vLLM, TensorRT-LLM, 모든 주요 도구 구동 |
| 학습 / 파인튜닝 | NVIDIA | PyTorch CUDA가 표준; MLX LoRA는 제한적 |
| 휴대성 | Apple | MacBook Pro M5는 배터리로 14B 실행; 비교할 NVIDIA 노트북 없음 |
| 크로스 플랫폼 | NVIDIA | Linux/Windows에서 CUDA; MLX는 macOS 전용 |
| 미래 준비성 | 동점 | Apple M6가 메모리 확장; NVIDIA가 VRAM 증가 — 둘 다 개선 |
💡Tip: 결정 규칙: 주요 모델이 70B 이상 → Apple 선택. 주요 모델이 7–30B이고 예산이 $3,000 미만 → NVIDIA 선택.
구매 가이드: 사용 사례별 권장 하드웨어
2026년 5월 현재 가격으로 권장하는 특정 하드웨어 옵션입니다.
📌Note: PromptQuorum은 이 링크에서 수수료를 받지 않습니다. Apple Store 및 Amazon 링크는 가격 참조용으로 제공됩니다. 구매 전 항상 현재 가격을 확인하십시오.
자주 묻는 질문
Apple MLX 모델을 Windows나 Linux에서 실행할 수 있습니까?
아니오. MLX는 macOS 전용이며 Apple Silicon이 필요합니다. llama.cpp를 통한 GGUF 모델은 모든 플랫폼에서 작동합니다. 크로스 플랫폼 사용을 위해서는 GGUF 형식의 Ollama가 Mac과 NVIDIA 시스템 모두에서 작동합니다.
Ollama는 Apple Silicon에서 MLX를 사용합니까?
Apple Silicon의 Ollama는 기본적으로 MLX가 아닌 Metal GPU 가속을 사용합니다. MLX 특화 최적화(특정 모델에서 더 빠른 경우가 많음)를 위해서는 mlx-lm을 직접 사용하거나 MLX 백엔드를 활성화한 LM Studio를 사용하십시오.
Mac에서 NVIDIA CUDA를 위해 eGPU를 사용할 수 있습니까?
아니오. macOS는 2019년에 eGPU CUDA 지원을 제거했습니다. 외부 NVIDIA GPU는 CUDA 컴퓨팅에서 macOS와 호환되지 않습니다. 실용적인 대안은 NVIDIA GPU가 있는 별도의 Linux 시스템입니다.
Mistral Small을 실행하는 데 어느 것이 더 좋습니까?
NVIDIA RTX 4090 ~150 tok/s vs Apple M5 Max ~75 tok/s — NVIDIA가 2배 빠릅니다. RTX 3060 12GB (~$280 중고)조차 순수 추론 속도에서 7B 기준으로 Mac Mini M4 ($1,599)를 능가합니다.
70B 모델 실행을 위한 최소 Mac은 무엇입니까?
64GB 통합 메모리를 갖춘 Mac Studio M4 Max (~$3,199). Llama 3 70B Q4_K_M은 ~38GB가 필요하며 64GB 구성은 가중치와 컨텍스트를 위한 충분한 여유 공간을 제공합니다.
Apple M5 Max가 로컬 LLM에서 RTX 4090보다 낫습니까?
모델 크기에 따라 다릅니다. 7B의 경우: RTX 4090 우세 (150 tok/s vs 75 tok/s). 70B의 경우: M5 Max 128GB가 기본적으로 우세 — RTX 4090은 70B를 전혀 탑재할 수 없습니다. 학습의 경우: NVIDIA가 큰 차이로 우세합니다.