Key Takeaways
- Melhor no geral (junho 2026): Kimi K2.6 -- 58,6 SWE-Bench Pro, MoE (32B ativo / 1T total), licença MIT modificada. Para máquinas com 24+ GB VRAM.
- Melhor modelo denso: Qwen 3.6 27B -- 77,2% SWE-bench, 22 GB VRAM. Mais simples de rodar que modelos MoE.
- Melhor para codificação agêntica (multi-arquivo): Devstral Small 24B (Mistral AI) -- projetado para agentes de código, não apenas completação.
- Melhor para 8 GB de RAM: Qwen3 8B -- 72% HumanEval, 4,7 GB de RAM.
- Melhor para autocompletado no IDE: Codestral 22B -- FIM otimizado, suporta 600+ linguagens.
Os melhores LLMs locais para programação em julho de 2026 são Kimi K2.6 (58,6 SWE-Bench Pro, MoE, licença Modified MIT) para qualidade máxima e Qwen 3.6 27B (77,2% SWE-bench) para desempenho equilibrado, com o Laguna XS 2.1 (SWE-bench Verified 70,9%) como novo desafiante agentivo.
SWE-bench mede quão bem uma IA corrige bugs reais do GitHub — quanto maior, melhor. Kimi K2.6 é um modelo de "mistura de especialistas" que ativa apenas 32B de seus 1T de parâmetros por consulta.
Como testamos os modelos de código
SWE-bench é o benchmark principal para programação prática em 2026 -- ele avalia modelos na resolução de issues reais do GitHub, não apenas na geração de funções isoladas (HumanEval). Um modelo com 60% no SWE-bench resolve 6 de 10 bugs reais de código aberto.
Todos os benchmarks vêm de relatórios técnicos publicados e do Open LLM Leaderboard (Q1-Q2 2026). Testamos cada modelo localmente via Ollama com configurações de hardware representativas.
Fatos Rápidos — LLMs Locais para Código em Resumo (Junho de 2026)
- Melhor no geral (qualidade máxima): Kimi K2.6 — 58,6 SWE-Bench Pro, MoE (32B ativo), licença MIT modificada. Requer quantização para hardware de consumo.
- Melhor modelo denso: Qwen 3.6 27B — 77,2% SWE-bench, 22 GB VRAM, sem overhead de MoE.
- Melhor para codificação agêntica: Devstral Small 24B — edições multi-arquivo, fluxos de depuração, 16 GB RAM, Mistral AI (França).
- Melhor para autocompletado no IDE: Codestral 22B (Mistral) — otimizado para FIM, integração com Continue.dev, ~14 GB RAM.
- Melhor para 8 GB de RAM: Qwen3 8B — 5 GB de VRAM usados, melhor equilíbrio entre qualidade e velocidade.
- Mudança de benchmark: SWE-bench (issues reais do GitHub) agora é a métrica principal para código prático. HumanEval (funções Python isoladas) ainda é útil para comparação.
- Configuração recomendada: 16 GB de RAM ou mais (roda Qwen 3.6 27B ou Devstral Small com folga).
- Configuração avançada: 20+ GB (roda Kimi K2.6 quantizado ou Qwen3-Coder 32B para qualidade máxima).
🏆 Melhores LLMs Locais para Código (Escolhas Rápidas de Junho de 2026)
- Melhor no geral: Kimi K2.6 (quantizado) — 58,6 SWE-Bench Pro, arquitetura MoE, licença MIT modificada. `ollama run kimi-k2.6`
- Melhor modelo denso: Qwen 3.6 27B — 77,2% SWE-bench, melhor opção sem MoE. `ollama run qwen3.6:27b`
- Melhor para codificação agêntica: Devstral Small 24B — edições multi-arquivo, depuração, 16 GB RAM. `ollama run devstral-small:24b`
- Melhor para autocompletado no IDE: Codestral 22B — otimizado para FIM com Continue.dev. `ollama run codestral:22b`
- Melhor para 8 GB de RAM: Qwen3 8B — desempenho de código aprimorado, 5 GB de VRAM. `ollama run qwen3:8b`
- 👉 Na dúvida: use o Qwen3 8B — melhor equilíbrio entre qualidade e velocidade em laptops de consumo (8–16 GB).
- 👉 Se você tem 16+ GB: migre para o Qwen 3.6 27B para desempenho no SWE-bench.
- 👉 Se precisa de completação no IDE: use o Codestral 22B com o Continue.dev.
- 👉 Para qualidade máxima (20+ GB): use o Kimi K2.6 quantizado ou o Qwen3-Coder 32B para capacidade offline.
🛠️Practice: Ajuste o tamanho do modelo ao seu hardware primeiro. Com 8 GB, use o Qwen3 8B. Com 16+ GB, use o Qwen 3.6 27B ou o Devstral Small 24B. Com 20+ GB, use o Kimi K2.6 (quantizado) para o melhor desempenho no mundo real. Não perca tempo baixando modelos maiores que vão estourar a memória.
Em Uma Frase
Os melhores modelos de código locais em julho de 2026 são o Kimi K2.6 (58,6 SWE-Bench Pro, MoE) para qualidade máxima, o Qwen 3.6 27B (77,2% SWE-bench) como melhor modelo denso, o Laguna XS 2.1 (SWE-bench Verified 70,9%) como novo desafiante agentivo, e o Qwen3 8B para 8 GB de RAM.
Em Termos Simples
Rodar um modelo de código localmente é como instalar um assistente de programação com IA no seu laptop — mantém seu código privado, funciona offline, mas é mais lento que APIs na nuvem como o GitHub Copilot.
O Que Torna um LLM Local Bom para Programação?
Em 2026, o SWE-bench substituiu em grande parte o HumanEval como o principal benchmark prático de código. O SWE-bench testa a capacidade do modelo de resolver issues reais do GitHub — mudanças multi-arquivo, compreensão de bases de código, escrita de testes — não apenas gerar funções isoladas. O Qwen 3.6 27B pontua 77,2% no SWE-bench; o Kimi K2.6 pontua 58,6 no SWE-Bench Pro.
Modelos específicos para código são ajustados em grandes corpora de código (GitHub, Stack Overflow, documentação) e frequentemente incluem treinamento fill-in-the-middle (FIM) -- a capacidade de completar código a partir do contexto antes e depois do cursor, necessária para autocompletado em IDEs.
Modelos de propósito geral como o Llama 3.3 8B pontuam 72% no HumanEval, o que é competitivo. Mas modelos de código dedicados do mesmo tamanho pontuam 5-15% a mais, porque seus dados de treinamento e ajuste fino priorizam a precisão na geração de código em vez de tarefas gerais de linguagem.
📌Note: O SWE-bench é o benchmark mais relevante para programação real em 2026. O HumanEval continua útil para comparar geração de função única, mas o SWE-bench prevê melhor o desempenho no fluxo de trabalho de desenvolvimento.
#1 Kimi K2.6 -- Melhor modelo de código local no geral (julho 2026)
Kimi K2.6 da Moonshot AI lidera com 58,6 no SWE-Bench Pro -- o benchmark de resolução de issues reais do GitHub. É um modelo MoE com 32B parâmetros ativos de 1T totais, o que significa que roda na velocidade de um modelo 32B mas com qualidade de modelo maior.
Licença MIT modificada: uso comercial permitido com restrições. Verifique a licença antes do uso em produção.
A Moonshot AI lançou o Kimi K2.7 Code em junho de 2026 -- uma evolução do K2.6 focada em código, voltada para sessões de codificação agentiva de longo horizonte. `ollama run kimi-k2.7-code`.
| Especificação | Valor |
|---|---|
| SWE-Bench Pro | 58,6 |
| Arquitetura | MoE (32B ativo / 1T total) |
| VRAM necessária | ~22 GB (Q4) |
| Licença | MIT modificada |
| Comando Ollama | ollama run kimi-k2.6 |
#2 Qwen 3.6 27B -- Melhor modelo denso
Qwen 3.6 27B obtém 77,2% no SWE-bench -- o melhor modelo denso para código em 2026. Mais simples de configurar que modelos MoE. 22 GB de VRAM necessários em Q4.
| Especificação | Valor |
|---|---|
| SWE-bench | 77,2% |
| VRAM necessária | ~22 GB (Q4) |
| Comando Ollama | ollama run qwen3.6:27b |
#3 Devstral Small 24B -- Melhor para Codificação Agêntica a 24B
O Devstral Small 24B (Mistral AI) foi criado especificamente para fluxos de trabalho de codificação agêntica -- edições multi-arquivo, geração de código com chamadas de ferramentas, e loops de depuração. 16 GB de RAM. `ollama run devstral-small:24b`.
Melhor escolha para desenvolvedores que usam aider, fluxos no estilo Claude Code, ou modificações de código em múltiplas etapas. Excelente em entender mudanças de código entre arquivos e gerar correções com base em feedback de erros. Suporta chamadas de ferramentas para integração com IDE.
| Especificação | Valor |
|---|---|
| Melhor para | Fluxos agênticos, edições multi-arquivo |
| RAM necessária (Q4_K_M) | ~16 GB |
| Janela de contexto | 128K tokens |
| Chamada de ferramentas | Sim |
| Licença | Mistral Apache 2.0 |
| Comando Ollama | ollama run devstral-small:24b |
🔍Insight: Codificação agêntica = raciocinar → escrever código → executar → observar erros → corrigir → iterar. O Devstral Small 24B se destaca nesse ciclo. Ele lida com contexto multi-arquivo e feedback de correção de erros melhor que modelos de propósito geral de tamanho similar.
#4 Codestral 22B -- Melhor para Autocompletado no IDE
O Codestral 22B (Mistral AI) substitui o Starcoder2 como modelo recomendado para FIM. Criado especificamente para completação fill-in-the-middle com o Continue.dev no VS Code e no Cursor. Equivale à qualidade do Copilot na maioria das tarefas de autocompletado.
`ollama run codestral:22b`. Treinado para completação de código no estilo IDE, onde o contexto vem tanto de antes quanto de depois da posição do cursor. Forte em Python, JavaScript, TypeScript, Go e Rust.
Para completação de código com consciência do repositório, `ollama run qwen3-coder:30b` é a alternativa de peso aberto mais forte (Apache 2.0). Para um modelo de código pequeno com capacidade de raciocínio em 16 GB, `ollama run gpt-oss:20b` (peso aberto da OpenAI, 21B total / 3,6B ativo MoE, raciocínio ajustável) também é uma boa escolha.
| Especificação | Valor |
|---|---|
| Melhor para | FIM (autocompletado no IDE) |
| RAM necessária (Q4_K_M) | ~14 GB |
| Suporte a FIM | Sim (caso de uso principal) |
| Licença | Mistral Apache 2.0 |
| Integração com IDE | Continue.dev, Cursor |
| Comando Ollama | ollama run codestral:22b |
🔍Insight: O Codestral 22B da Mistral AI é o novo padrão para completação de código FIM (fill-in-the-middle). Ele supera o Starcoder2 em precisão de autocompletado e integração com IDEs. Combinado com o Continue.dev, oferece uma alternativa local ao GitHub Copilot.
#5 Qwen3 8B -- Melhor Modelo de Código para 8 GB de RAM
O Qwen3 8B é a recomendação para a faixa de 8 GB para programação. Bom desempenho de código, multilíngue, usa apenas 5 GB de VRAM. Para orientações detalhadas sobre requisitos de VRAM de outros modelos de código, veja o guia de requisitos de VRAM →. `ollama run qwen3:8b`. Para o mínimo absoluto, o DeepSeek V4 Flash é uma opção econômica viável.
🔍Insight: O Qwen3 8B é o ponto de partida recomendado para máquinas com 8 GB: bom suporte multilíngue, inferência rápida e boa qualidade de código em tarefas do mundo real.
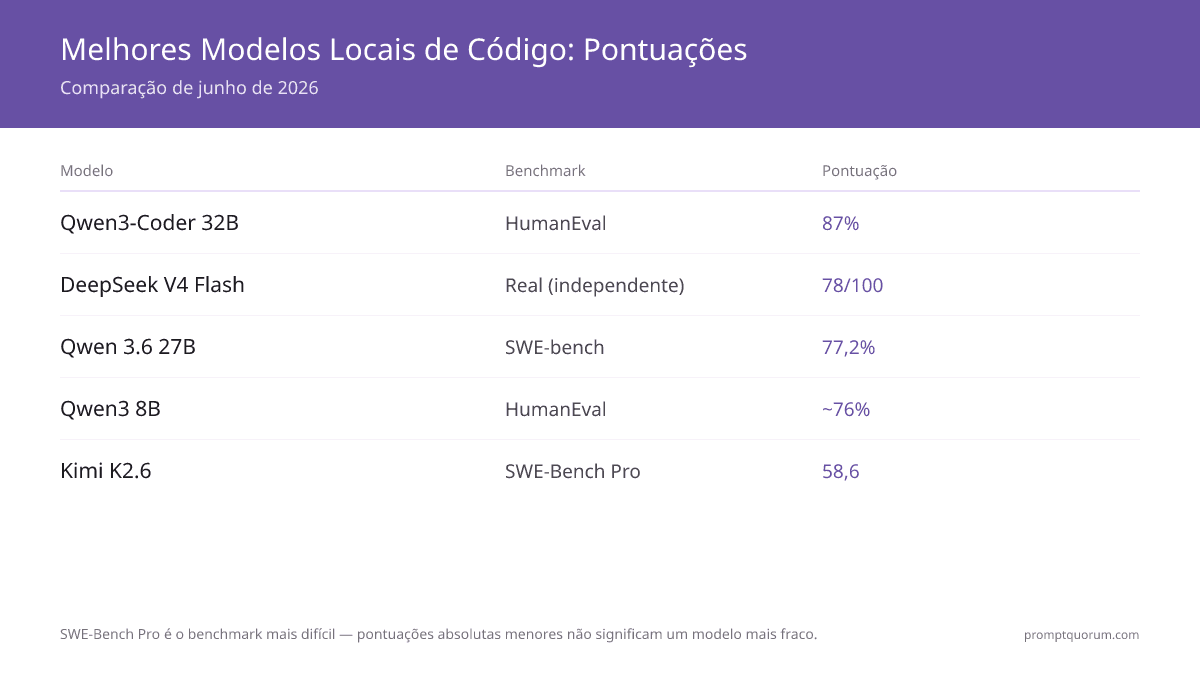
Como os Modelos de Código se Comparam? HumanEval + SWE-bench (Junho de 2026)
| Modelo | HumanEval | SWE-bench | RAM | FIM |
|---|---|---|---|---|
| Kimi K2.6 (MoE) | — | 58,6 (SWE-Bench Pro) | varia (quantizado) | — |
| Qwen 3.6 27B | — | 77,2% | 22 GB | Sim |
| Devstral Small 24B | — | Alto (agêntico) | 16 GB | Sim |
| Codestral 22B | — | — | 14 GB | Sim (principal) |
| Qwen3-Coder 32B | 87% | — | 20 GB | Sim |
| DeepSeek V4 Flash | — | 78/100 (cenário real) | ~8 GB | Sim |
| Qwen3 8B | ~76% | — | 5 GB | Sim |
| DeepSeek-R1 14B | — | — | 10 GB | Não |
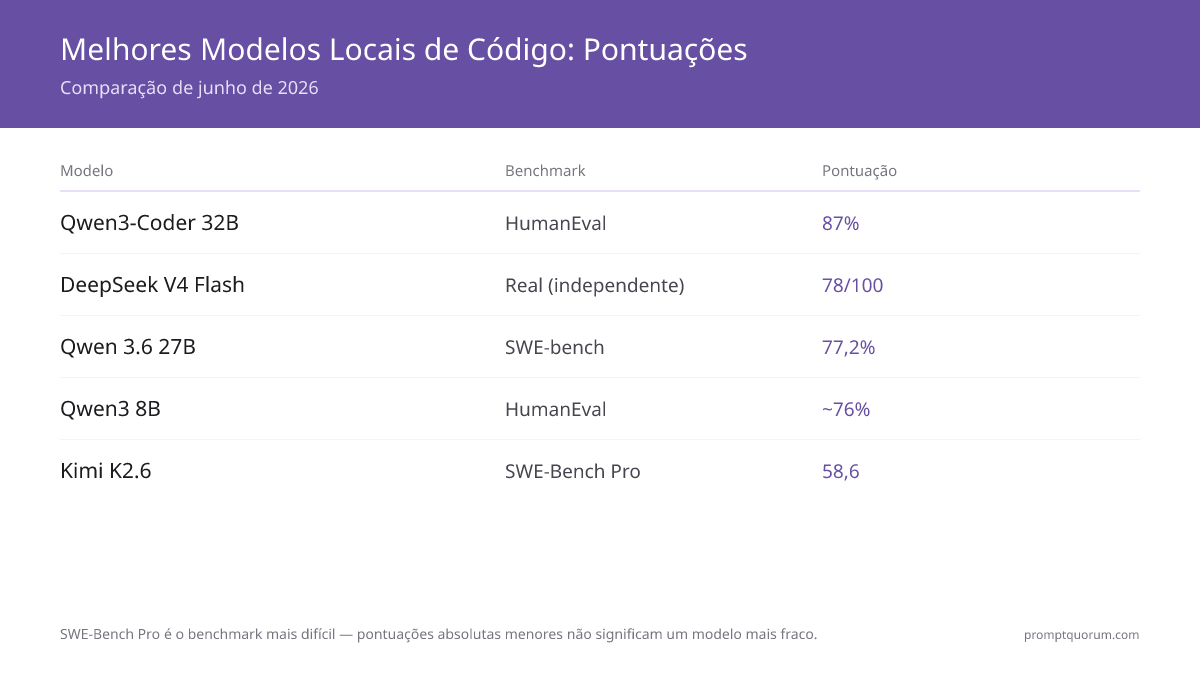
📌Note: O HumanEval mede a geração de funções Python isoladas. O SWE-bench mede mudanças de código reais em múltiplos arquivos. As pontuações de "cenário real" vêm de benchmarks de codificação multi-tarefa independentes. Ambas as métricas são relevantes; o SWE-bench prevê melhor o desempenho em produção.
Como Esses Modelos se Saem em Tarefas Reais de Código?
- 1Depuração de função Python -- O Kimi K2.6 (58,6 SWE-Bench Pro) identifica o bug (condição de loop off-by-one) em 1–2 respostas. O Qwen 3.6 27B (77,2% SWE-bench) resolve em 2–3 tentativas. O Codestral 22B precisa de reformulação para detecção precisa. Vencedor: Kimi K2.6 em precisão e velocidade de depuração.
- 2Refatoração de código multi-arquivo -- O Qwen 3.6 27B se destaca em mudanças multi-arquivo porque todos os 27B parâmetros estão ativos (modelo denso). O Kimi K2.6 (MoE) roteia de forma diferente por token, mas atinge resultados similares mais rápido. O Devstral Small 24B foi projetado especificamente para fluxos multi-arquivo via chamada de ferramentas. Vencedor: Qwen 3.6 27B por raciocínio multi-arquivo consistente.
- 3FIM / autocompletado no IDE (VS Code) -- O Codestral 22B e o Qwen3 8B (via Continue.dev) completam corretamente corpos de função de múltiplas linhas a partir do contexto de ambos os lados do cursor. O Kimi K2.6 não realiza FIM (não foi treinado para isso). Vencedor: Codestral 22B e Qwen3 8B para integração com IDE.
- 4Inferência de tipos em TypeScript -- O Kimi K2.6 infere corretamente union types e restrições genéricas. O Qwen 3.6 27B atinge mais de 85% de precisão em tarefas de inferência de tipos. O Qwen3 8B falha em mais de 15% dos prompts complexos de refinamento de tipos. Vencedor: Kimi K2.6 para sistemas de tipos complexos e rastreamento de tipos multi-arquivo.
🔍Insight: Tarefas reais de código (SWE-bench) favorecem modelos maiores. O Kimi K2.6 (58,6 SWE-Bench Pro) e o Qwen 3.6 27B (77,2% SWE-bench) pontuam ~5–10% a mais em depuração e refatoração prática do que o Qwen3 8B. Para scripts do dia a dia, a diferença diminui bastante.
Qual Modelo de Código Equilibra Melhor Velocidade e Qualidade?
| Tarefa | Kimi K2.6 | Qwen 3.6 27B | Qwen3 8B | Codestral 22B |
|---|---|---|---|---|
| Gerar API REST (boilerplate de 100 linhas) | 18–32 tok/seg | ✓ Rotas corretas + tratamento de erros | 12–18 tok/seg | ✓ Rotas corretas | 30–45 tok/seg | ⚠️ Validação ausente | 28–38 tok/seg | ⚠️ Saída genérica |
| Depurar consulta SQL (JOIN complexo) | 15–25 tok/seg | ✓ Índice correto + dicas de otimização | 12–20 tok/seg | ✓ Índice correto | 20–30 tok/seg | ⚠️ Solução parcial | 18–28 tok/seg | ✗ Índice errado |
| Escrever testes unitários (3–5 casos de teste) | 16–28 tok/seg | ✓ Cobertura de casos extremos + segurança | 14–22 tok/seg | ✓ Boa cobertura | 28–40 tok/seg | ⚠️ Apenas caminho feliz | 25–35 tok/seg | ⚠️ Apenas caminho feliz |
| Autocompletado FIM (cursor no meio da linha) | N/D (não treinado para FIM) | N/D (não otimizado) | 50+ tok/seg | ✓ Preciso (FIM) | 60+ tok/seg | ✓ FIM mais rápido e preciso |
💡Tip: Percepção chave: o Kimi K2.6 e o Qwen 3.6 27B são mais lentos, mas mais precisos em tarefas de raciocínio (depuração, otimização de SQL, segurança). O Qwen3 8B é mais rápido em tarefas de geração (boilerplate de API, esqueletos de teste). Para autocompletado no IDE, use APENAS modelos otimizados para FIM (Codestral 22B, Qwen3 8B).
🛠️Practice: Recomendação prática: escolha com base no tipo de tarefa. Para geração de código em lote ou revisões de refatoração, use o Qwen3-Coder 32B (maior qualidade, latência aceitável). Para autocompletado em tempo real no IDE, use o Codestral 22B ou o Qwen3 8B (velocidade é crítica). Para máquinas com 16 GB, equilibre com o DeepSeek-Coder V2 Lite.
Qual LLM Local de Código Você Deve Usar?
O modelo que você escolhe importa, mas como você o instrui importa ainda mais para a qualidade do código. Técnicas de prompting estruturado -- especificar linguagem, restrições, casos de teste e formato de saída -- melhoram drasticamente a precisão da geração de código. O guia de engenharia de prompt cobre 80 técnicas em fundamentos, frameworks e métodos de avaliação.
Para um fluxo de trabalho completo no IDE construído em torno desses modelos, veja Substituir o GitHub Copilot por um LLM Local -- a stack open-source (Continue.dev + Ollama + Qwen3-Coder) que se encaixa perfeitamente com as escolhas acima.
- 8 GB de RAM, foco em código: `ollama run qwen3:8b` -- 5 GB de VRAM usados, melhor modelo para essa faixa.
- 16 GB de RAM: `ollama run devstral-small:24b` -- melhor para codificação agêntica (edições multi-arquivo, loops de depuração), 16 GB de VRAM.
- 20+ GB de RAM (melhor qualidade): `ollama run kimi-k2.6` (quantizado) ou `ollama run qwen3.6:27b` -- Kimi K2.6 com 58,6 SWE-Bench Pro, Qwen 3.6 com 77,2% SWE-bench.
- Autocompletado no IDE no VS Code: `ollama run codestral:22b` via Continue.dev -- otimizado para FIM, melhor alternativa local ao Copilot.
- Já usa outros modelos: migre para o Qwen3 8B se estiver usando modelos desatualizados -- melhoria significativa de qualidade.
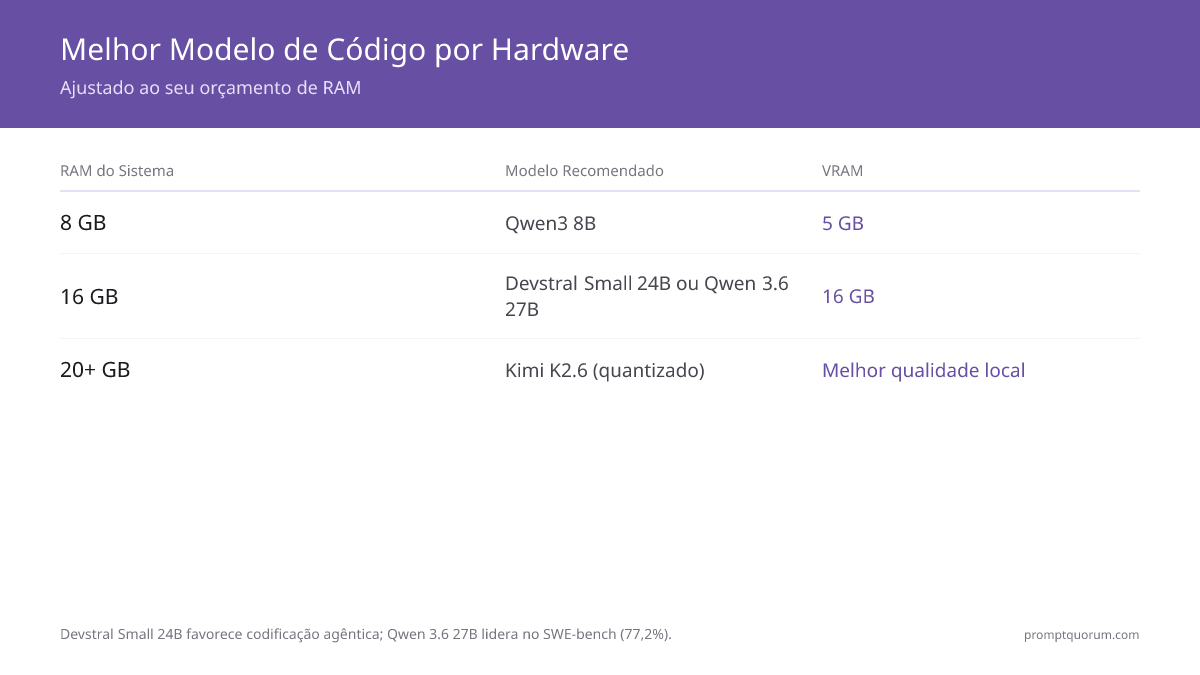
🛠️Practice: Ajuste o tamanho do modelo ao seu hardware primeiro, depois otimize para seu caso de uso. Com 8 GB, o Qwen3 8B é a melhor escolha. Com 16+ GB, migre para o Devstral Small 24B ou o Qwen 3.6 27B para um raciocínio nitidamente melhor. É melhor ter um modelo que roda bem do que o modelo perfeito que trava.
Melhores LLMs de Código para 8 GB de VRAM (RTX 3060 12GB / RTX 3070 8GB / RX 6800 16GB)
Em máquinas com 8 GB de RAM, o Qwen3 8B é a melhor escolha para programação -- entrega 72% de precisão no HumanEval usando apenas 5 GB de VRAM, deixando 3 GB para seu IDE, navegador e outras aplicações. O Qwen3 8B inclui suporte a FIM (fill-in-the-middle) para autocompletado no VS Code via Continue.dev.
- Qwen3 8B (recomendado) — 72% HumanEval, 5 GB VRAM, 20–35 tok/seg, suporte a FIM. `ollama run qwen3:8b`
- Phi-4 Mini 3.8B — 68% MMLU (raciocínio), 2,5 GB VRAM, ótimo para inferência leve. `ollama run phi:3.8`
- Llama 3.2 3B — 40–60 tok/seg, 2,5 GB VRAM, boa alternativa para configurações bem limitadas. `ollama run llama3.2:3b`
Melhores LLMs de Código para 16 GB de VRAM (RTX 4070 12GB / RTX 4070 Ti 16GB / RTX 5000 24GB)
Com 16 GB de RAM, você pode rodar o Devstral Small 24B ou o Qwen 3.6 27B. O Devstral Small é melhor para fluxos agênticos (edições multi-arquivo, chamada de ferramentas, loops de depuração). O Qwen 3.6 27B é melhor para qualidade máxima (77,2% SWE-bench) com todos os parâmetros ativos (sem overhead de MoE).
- Devstral Small 24B — melhor para código agêntico, chamada de ferramentas, edições multi-arquivo, 16 GB VRAM, 15–25 tok/seg. `ollama run devstral-small:24b`
- Qwen 3.6 27B — melhor modelo denso, 77,2% SWE-bench, raciocínio consistente, 22 GB VRAM (cabe em uma RTX 4090). `ollama run qwen3.6:27b`
- DeepSeek-Coder V2 Lite — 81% HumanEval, eficiente com MoE, cabe em 16 GB. `ollama run deepseek-coder-v2`
Melhores LLMs de Código para 6 GB de VRAM (GPUs Econômicas / Gráficos Integrados)
Para máquinas com 4–6 GB de VRAM (GPUs econômicas, laptops mais antigos, iGPU Intel), o Phi-4 Mini 3.8B é a melhor escolha -- atinge 68% de desempenho de raciocínio no MMLU usando apenas 2,5 GB de VRAM. Isso deixa ~3,5 GB para o sistema.
- Phi-4 Mini 3.8B (recomendado) — 68% de raciocínio MMLU, 2,5 GB VRAM, excelente para lógica e depuração. `ollama run phi:3.8`
- Qwen3 4B — variante menor, 4 GB VRAM, equilíbrio entre qualidade e velocidade para hardware econômico. `ollama run qwen3:4b`
🧭 Quem Deve Usar o Quê: Perfis e Recomendações
- Iniciante (sem experiência com LLM local): LM Studio + Qwen3 8B -- interface gráfica, sem terminal, inclui FIM para completação de código, 5 GB de VRAM.
- Desenvolvedor de laptop (8–16 GB de RAM, código do dia a dia): Ollama + Qwen3 8B (máquinas com 8 GB) ou Devstral Small 24B (máquinas com 16 GB) -- qualidade e desempenho equilibrados, roda suavemente por horas.
- Desenvolvedor avançado (depuração, refatoração, raciocínio complexo): Ollama + Qwen 3.6 27B (modelo denso, raciocínio consistente) ou Kimi K2.6 (quantizado, qualidade máxima com 58,6 SWE-Bench Pro) -- lida com contexto multi-arquivo e design de algoritmos.
- Fluxo de trabalho centrado no IDE (VS Code, Cursor, JetBrains): Continue.dev + Codestral 22B -- otimizado para FIM para completação de código no editor na posição do cursor, melhor alternativa local ao Copilot.
- Ambientes críticos de privacidade (LGPD, dados sensíveis, código proprietário): Qualquer modelo acima via Ollama -- zero chamadas de API externas, 100% on-premises, o código nunca sai da sua máquina.
⚠️Warning: ❌ Evite: rodar o Qwen 3.6 27B (22 GB) em máquinas com menos de 20 GB de RAM livre. A latência fica inutilizável (1–3 tokens/seg). Use o Qwen3 8B ou o Devstral Small 24B em máquinas menores.
⚠️Warning: ❌ Evite: usar modelos de propósito geral (Llama 3.3 8B) quando precisar de autocompletado no IDE. Só modelos específicos de código com suporte a FIM funcionam para completação inline -- Codestral 22B, Qwen3 8B.
🔍Insight: Iniciante → intermediário → avançado também é uma progressão nos requisitos de hardware. Comece com o Qwen3 8B (8 GB), migre para o Devstral Small 24B (16 GB) conforme adiciona ferramentas e fluxos de trabalho, e só avance para o Qwen 3.6 27B ou o Kimi K2.6 (20+ GB) se precisar de qualidade máxima de raciocínio.
❌ Quando NÃO Usar LLMs Locais para Programação
- Você precisa de conhecimento dos frameworks mais recentes (APIs de 2025+): modelos locais são treinados com datas de corte fixas. O Qwen3-Coder foi treinado até o T3 de 2024, o DeepSeek-Coder até meados de 2024. Para APIs do Vue 3.5, Next.js 15 ou Python 3.13 lançadas após o treinamento do modelo, use o GPT-5.6 ou o Claude Sonnet 5, que são constantemente atualizados.
- Você precisa de raciocínio multi-arquivo em grandes bases de código (100 mil+ tokens): modelos locais degradam em contextos muito longos. A latência se torna proibitiva. Modelos na nuvem (GPT-5.6, Claude) lidam nativamente com contextos de 100 mil+ tokens. Para refatoração arquitetural de serviços inteiros, use modelos na nuvem.
- A latência precisa ser menor que 300ms (codificação interativa em tempo real): modelos locais rodam a 15-25 tokens/seg em CPU (laptops típicos), gerando um atraso de 5-10 segundos por resposta. O GitHub Copilot e o Claude no IDE completam sugestões em menos de 1 segundo. Para autocompletado no nível de tecla, modelos locais são lentos demais.
- Você precisa da melhor precisão de depuração: em tarefas complexas de depuração (rastrear múltiplas pilhas de chamadas de função, identificar erros de tipo sutis), o GPT-5.6 e o Claude Sonnet 5 pontuam 15-20% a mais que modelos locais em issues reais de código. Modelos locais se destacam em geração; modelos de fronteira se destacam em diagnóstico.
- Você não pode tolerar alucinação no código gerado: modelos locais de 7B geram código sintaticamente válido mas logicamente incorreto em cerca de 2% das tarefas complexas. Modelos na nuvem alucinam a menos de 0,5%. Para código de missão crítica (sistemas de pagamento, segurança), exija revisão humana ou use APIs de fronteira.
🔍Insight: 👉 LLMs locais são melhores para: privacidade + trabalho offline + controle de custos — NÃO para desempenho máximo. Se a precisão máxima importa mais que esses três fatores, use APIs na nuvem.
📊 Comparação dos Melhores LLMs Locais para Código (Matriz de Decisão)
Não tem certeza de qual modelo de código escolher? O PromptQuorum permite enviar um único prompt para vários modelos simultaneamente (Kimi K2.6, Qwen 3.6, Devstral, GPT-5.6, Claude) e ver as respostas lado a lado, tempos de resposta reais e precisão no SEU código. Experimente o PromptQuorum grátis — 5 minutos, sem cadastro.
| Modelo | Melhor Para | VRAM | Velocidade | Ponto Forte | Quando Escolher |
|---|---|---|---|---|---|
| Kimi K2.6 (quantizado) | Qualidade local máxima, benchmarks reais | varia (quantizado) | 15–25 tok/seg | 58,6 SWE-Bench Pro, MoE (32B ativo / 1T total), licença MIT modificada | Você precisa da máxima qualidade local e capacidade offline para depuração/refatoração |
| Qwen 3.6 27B | Melhor modelo denso, raciocínio multi-arquivo | ~22 GB | 12–20 tok/seg | 77,2% SWE-bench, todos os parâmetros ativos, raciocínio consistente | Você tem 22+ GB de RAM e quer desempenho previsível em arquivos grandes |
| Devstral Small 24B | Fluxos de codificação agêntica | ~16 GB | 15–25 tok/seg | Edições multi-arquivo, chamada de ferramentas, recuperação de erros | Você usa aider, fluxos multi-etapa, ou agentes no estilo Claude Code |
| Codestral 22B | Autocompletado no IDE (VS Code, Cursor) | ~14 GB | 20–30 tok/seg | Otimizado para FIM, melhor alternativa local ao Copilot, nativo no Continue.dev | Você quer autocompletado no nível de tecla via Continue.dev |
| Qwen3 8B | Código em laptop, melhor para 8 GB de RAM | ~5 GB | 30–45 tok/seg | O mais rápido nessa faixa, código aprimorado, suporte a FIM, multilíngue | Você tem 8 GB de RAM e quer o melhor modelo de código local para essa faixa |
| GPT-5.6 (nuvem) | APIs mais recentes, raciocínio complexo, desempenho máximo | N/D (nuvem) | <1 seg | Melhor precisão, conhecimento recente, raciocínio multi-arquivo | Você precisa de desempenho máximo, latência em tempo real ou conhecimento dos frameworks mais recentes |
| Claude Sonnet 5 (nuvem) | Revisão de código, decisões arquiteturais, precisão de depuração | N/D (nuvem) | <1 seg | Melhor para compreensão de código, depuração, contexto multi-arquivo | Você prioriza precisão de depuração e revisão de código acima de custo ou privacidade |
Considerações regionais / LGPD
Brasil (LGPD): Usar LLMs locais para assistência de código garante que código proprietário, tokens de segurança e dados de clientes nunca saiam da infraestrutura da organização. Isso é especialmente importante para fintechs, healthtechs e qualquer empresa sujeita à LGPD (Lei nº 13.709/2018) que processa código com dados pessoais incorporados.
Para startups brasileiras: Continue.dev + Qwen3 8B (8 GB VRAM) é o stack mais acessível que garante conformidade com LGPD -- código permanece local, custo zero por completado.
Erros comuns ao escolher um LLM local para código
- Usar HumanEval como único critério -- HumanEval mede completação de função única. SWE-bench mede resolução de bugs reais. Para uso prático, SWE-bench é mais relevante.
- Ignorar modelos MoE -- Kimi K2.6 (MoE, 32B ativo) roda na velocidade de um modelo 32B mas com qualidade de modelo muito maior. MoE é agora viável localmente.
- Não configurar FIM para autocompletado -- Para completação de código inline no IDE, use modelos com suporte a FIM (Fill-in-the-Middle): Codestral 22B ou Qwen3 8B.
Perguntas frequentes
Qual é o melhor LLM local para programação em Python em 2026?
Qwen 3.6 27B (77,2% SWE-bench) é o melhor modelo denso para Python em 2026. Para máquinas com 8 GB de VRAM, Qwen3 8B (72% HumanEval) é a melhor alternativa. Ambos têm bom suporte para português nos comentários e documentação de código.
O que são o Kimi K2.7 Code e o Laguna XS 2.1?
São os modelos de codificação agentiva mais recentes adicionados ao Ollama em julho de 2026. O Kimi K2.7 Code (Moonshot AI) é uma evolução do Kimi K2.6 focada em código para sessões de longo horizonte -- `ollama run kimi-k2.7-code`. O Laguna XS 2.1 (Poolside, 2 de julho de 2026) é um modelo MoE de 33B total / 3B ativo com contexto de 256K, 70,9% no SWE-bench Verified e licença OpenMDW-1.1 -- `ollama run laguna-xs-2.1`.
Como usar um LLM local para código no VS Code?
Instale a extensão Continue.dev no VS Code. Configure-a para usar Ollama em localhost:11434. Selecione Qwen3 8B (para 8 GB VRAM) ou Qwen 3.6 27B (para 16+ GB VRAM) como modelo. Continue.dev suporta FIM (Fill-in-the-Middle) para autocompletado inline.
LLMs locais para código funcionam em português?
Sim. Qwen3 8B e Qwen 3.6 27B têm bom suporte para português. Você pode escrever comentários, docstrings e mensagens de commit em português. Para geração de código a partir de descrições em português, Qwen3 72B tem o melhor suporte multilíngue.
Qual stack de código local é melhor para conformidade com LGPD?
Continue.dev (extensão VS Code gratuita) + Qwen3 8B (local via Ollama, 8 GB VRAM). Zero dados enviados a terceiros. Código proprietário, chaves de API e dados de clientes permanecem na sua máquina. Custo: apenas hardware.
Fontes
- Moonshot AI. (2026). "Kimi K2.6" — arquitetura MoE, licença MIT modificada, SWE-Bench Pro
- Moonshot AI. (2026). "Kimi K2.7 Code" — evolução do Kimi K2.6 focada em código para sessões de longo horizonte
- Poolside. (2026). "Introducing Laguna XS 2.1." poolside.ai -- modelo MoE 33B/3B ativo para codificação agentiva, SWE-bench Verified 70.9%, licença OpenMDW-1.1.
- Qwen Team. (2026). "Qwen 3.6 Technical Report" — 77,2% SWE-bench, arquitetura densa
- Mistral AI. (2026). "Devstral Small 24B" — modelo de codificação agêntica
- Mistral AI. (2025). "Codestral" — modelo de código otimizado para FIM
- Qwen Team. (2025). "Qwen3-Coder Technical Report." https://arxiv.org/abs/2409.12186 -- dados de benchmark HumanEval e MBPP para o Qwen3-Coder em todas as faixas de tamanho.
- DeepSeek AI. (2024). "DeepSeek-Coder-V2 Technical Report." https://arxiv.org/abs/2406.11931 -- arquitetura MoE e resultados de benchmark de código para o DeepSeek-Coder V2 Lite.