Key Takeaways
- Qwen 3.6 27B هو الاختيار الرائد الجديد: كثيف، Apache 2.0، سياق 256K، ~17 GB من VRAM عند Q4_K_M عبر `ollama run qwen3.6:27b` (صدر في أبريل 2026).
- يعمل Qwen3 8B بـ 5.5 GB من VRAM — أمر واحد `ollama pull qwen2.5:7b` وينطلق بـ 57 token/ثانية على RTX 3060.
- أربع عائلات فرعية عملية: Qwen3 (استخدام عام، وضع استدلال)، Qwen2.5 (استخدام عام، الأكثر اختبارًا)، Qwen2.5-Coder (برمجة، 92.7% في HumanEval على 32B)، Qwen2-VL (رؤية، أفضل OCR محلي لـ CJK).
- بنية كثيفة = متوافقة مع الأجهزة الاستهلاكية: على عكس نموذج MoE بحجم 236B لـ DeepSeek (~130 GB من RAM)، يتسع Qwen2.5-72B في 46 GB من VRAM على بطاقتي RTX 3090.
- متعدد اللغات أصليًا: مدرَّب مسبقًا على الصينية واليابانية والكورية والعربية والألمانية والفرنسية و23 لغة أخرى — يتفوق Qwen3 باستمرار على Llama 3.3 في مهام CJK.
- Q4_K_M هو التكميم الصحيح لمعظم المستخدمين: تقليل VRAM بنحو 55%، أقل من 1% فقدان جودة في المعايير.
- قرار الأجهزة: 12 GB من VRAM ← نموذج 14B؛ 24 GB ← 32B؛ 48 GB+ (بطاقتا رسوم أو Apple Silicon 64 GB) ← 72B.
يغطي Qwen3 ثلاث عائلات فرعية للنشر المحلي — استخدام عام (7B–72B) وبرمجة (Coder 7B–32B) ورؤية (VL 7B–72B) — جميعها قابلة للتشغيل عبر Ollama أو LM Studio.
تشغيل نموذج محليًا يعني أن الذكاء الاصطناعي يعمل على حاسوبك بدلًا من خادم سحابي. لا تغادر أي بيانات جهازك ولا توجد تكلفة لكل token بعد اقتناء الأجهزة.
نظرة عامة على عائلة نماذج Qwen
تضم تشكيلة Qwen الآن خمسة خيارات عملية: الرائد Qwen 3.6 27B، وعائلة Qwen3 الأحدث، وQwen2.5 للاستدلال العام، وQwen2.5-Coder، وQwen2-VL للرؤية — لكل منها خيارات أحجام متعددة. جميعها نماذج ذات أوزان مفتوحة نشرها فريق Qwen التابع لـ Alibaba على Hugging Face بموجب ترخيص Apache 2.0.
اختر العائلة الفرعية أولًا ثم الحجم الذي يلائم VRAM لديك. من المعتاد دمج العائلات الفرعية: Qwen2.5-Coder 14B لإكمال الكود وQwen3 8B أو Qwen 3.6 27B لتلخيص المستندات.
| Subfamilia | Tamaños disponibles | Uso principal | Prefijo de etiqueta Ollama |
|---|---|---|---|
| Qwen3 | 0.6B، 1.7B، 4B، 8B، 14B، 32B | الاستدلال العام، وضع الاستدلال، متعدد اللغات، المهام الوكيلية | qwen3: |
| Qwen2.5 | 7B، 14B، 32B، 72B | الاستدلال العام، المهام بالصينية/متعددة اللغات، RAG | qwen2.5: |
| Qwen2.5-Coder | 7B، 14B، 32B | توليد الكود، التصحيح، HumanEval، SWE-bench | qwen2.5-coder: |
| Qwen2-VL | 2B، 7B، 72B | OCR للمستندات، الأسئلة عن الصور، استخراج نص CJK | qwen2-vl: |
Qwen 3.6 27B (صدر في أبريل 2026) هو الاختيار الرائد الجديد — نموذج كثيف بنافذة سياق 256K يعمل بـ ~17 GB من VRAM عند Q4_K_M عبر `ollama run qwen3.6:27b`. تظل Qwen2.5 العائلة الأكثر اختبارًا، بأوسع تغطية في Ollama وGGUF حتى منتصف 2026. راجع أفضل نماذج LLM المحلية 2026 لمقارنة أوسع.
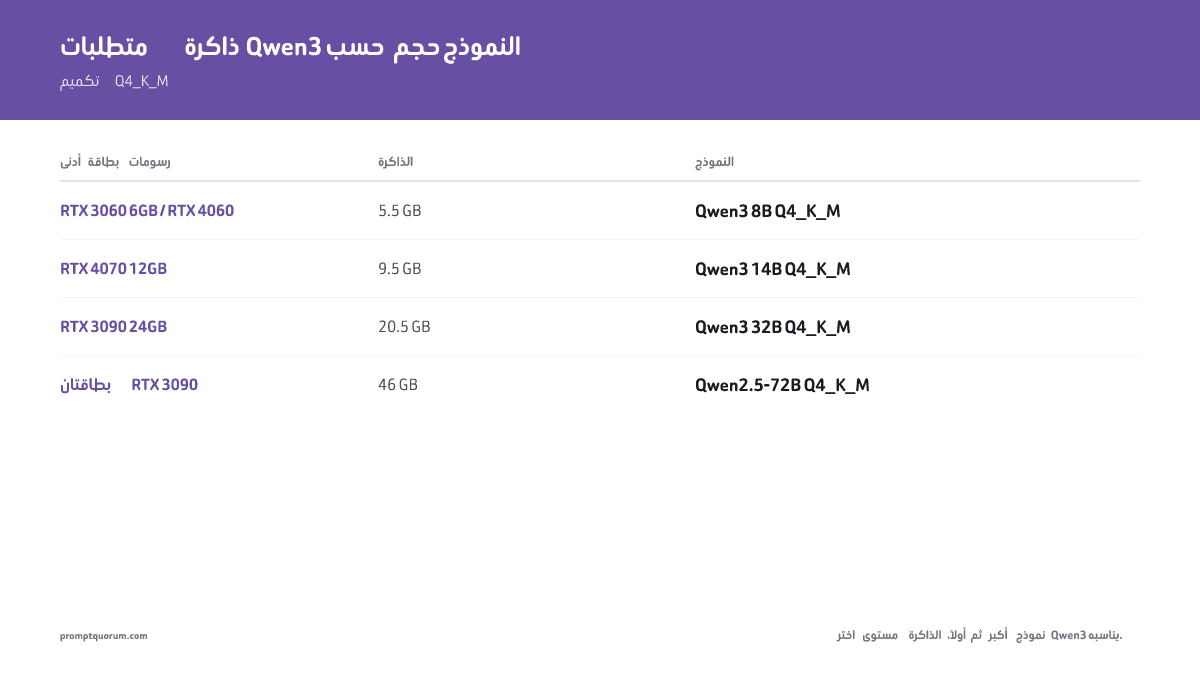
متطلبات الأجهزة حسب حجم النموذج
اختر مستوى VRAM لديك أولًا ثم أكبر نموذج Qwen3 يتسع. Q4_K_M هو التكميم القياسي المستخدم في جميع الأرقام أدناه — يقدّم أفضل نسبة حجم/جودة لـ Ollama وLM Studio.
| Modelo | VRAM | GPU mínima | Apple Silicon | Velocidad (RTX 3060) |
|---|---|---|---|---|
| Qwen3 8B Q4_K_M | 5.5 GB | RTX 3060 6 GB، RTX 4060 | M1/M2 8 GB | ~57 tok/s |
| Qwen3-Coder 7B Q4_K_M | 5.5 GB | RTX 3060 6 GB، RTX 4060 | M1/M2 8 GB | ~55 tok/s |
| Qwen2-VL 7B Q4_K_M | 6.2 GB | RTX 3060 8 GB، RTX 4060 | M1/M2 16 GB | — |
| Qwen3 14B Q4_K_M | 9.5 GB | RTX 4070 12 GB | M2 Pro 16 GB | — |
| Qwen3-Coder 14B Q4_K_M | 9.5 GB | RTX 4070 12 GB | M2 Pro 16 GB | — |
| Qwen3 32B Q4_K_M | 20.5 GB | RTX 3090 24 GB | M3 Max 48 GB | — |
| Qwen3-Coder 32B Q4_K_M | 20.5 GB | RTX 3090 24 GB | M3 Max 48 GB | — |
| Qwen 3.6 27B Q4_K_M | ~17 GB | RTX 4090 24 GB | M3 Max 36 GB | — |
| Qwen2.5-72B Q4_K_M | 46 GB | 2× RTX 3090 (48 GB) | M2 Ultra 64 GB | — |
أرقام VRAM تخصّ ملفات GGUF Q4_K_M من مكتبة Ollama. أضف 1–2 GB لذاكرة KV المؤقتة بسياق 4K. إذا كانت بطاقة الرسوم تملك VRAM أقل مما يحتاج النموذج، يفرّغ Ollama الطبقات تلقائيًا إلى RAM النظام — يعمل، لكنه يقلّل السرعة بشكل كبير.
الإعداد عبر Ollama
Ollama هو أسرع طريقة لتشغيل أي نموذج Qwen3 محليًا — يدير تنزيل النموذج وتكميم GGUF وواجهة API المحلية على `localhost:11434` دون أي إعداد. ثبّته من ollama.com. إذا لم تستخدم Ollama من قبل، اقرأ أولًا كيفية تثبيت Ollama.
- 1ثبّت Ollama
Why it matters: متاح لـ macOS وLinux (تثبيت بسطر واحد) وWindows. لا حاجة لإعداد تعريفات بطاقة الرسوم — يكتشف Ollama CUDA وROCm وMetal تلقائيًا. - 2نزّل النموذج بوسم حجم صريح
Why it matters: حدّد الحجم دائمًا: `qwen2.5:7b`، `qwen2.5:14b`، `qwen2.5:32b`. يُحل `qwen2.5` غير الموسوم إلى نموذج 7B، لكنه قد يتغير بين إصدارات Ollama. - 3شغّل النموذج
Why it matters: `ollama run qwen2.5:7b` يفتح دردشة تفاعلية. اكتب أمرك واضغط Enter. أغلق بـ `/bye`. - 4اضبط نافذة السياق عند الحاجة
Why it matters: يدعم Qwen3 افتراضيًا سياق 32K في Ollama. لاستخدام سياق 128K على نموذج 7B، نفّذ `ollama run qwen2.5:7b --num-ctx 131072`. يتطلب هذا مزيدًا من VRAM. - 5اختبر نقطة نهاية API
Why it matters: يكشف Ollama واجهة API متوافقة مع OpenAI. تتصل تطبيقات مثل PromptQuorum وContinue.dev وOpen WebUI مباشرة بـ `http://localhost:11434/v1`.
# Instalar Ollama (Linux)
curl -fsSL https://ollama.com/install.sh | sh
# macOS: descarga el .dmg desde ollama.com o:
brew install ollama
# Descargar modelos — usa etiquetas explícitas
ollama pull qwen3.6:27b # insignia, contexto 256K (~17 GB)
ollama pull qwen3:8b # Qwen3 uso general 8B (~5,5 GB)
ollama pull qwen2.5:7b # Qwen2.5 uso general 7B (~5,5 GB)
ollama pull qwen2.5:14b # Qwen2.5 uso general 14B (~9,5 GB)
ollama pull qwen2.5:32b # Qwen2.5 uso general 32B (~20,5 GB)
ollama pull qwen2.5-coder:32b # Qwen2.5-Coder 32B (~20,5 GB)
ollama pull qwen2-vl:7b # visión 7B (~6,2 GB)
# Ejecutar en modo interactivo
ollama run qwen2.5:7b
# Probar la API compatible con OpenAI
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"qwen2.5:7b","messages":[{"role":"user","content":"Hola"}]}'الإعداد عبر LM Studio
يقدّم LM Studio واجهة رسومية لـ Qwen3 دون الحاجة إلى أوامر طرفية. نزّله من lmstudio.ai أو راجع كيفية تثبيت LM Studio. يعمل على macOS وWindows وLinux.
- 1افتح متصفح النماذج
Why it matters: ابحث عن "Qwen3" أو "Qwen Coder" لاستكشاف جميع بناءات GGUF المتاحة. رشّح حسب Q4_K_M للحصول على نسبة الجودة/الحجم الموصى بها. - 2نزّل بناء GGUF
Why it matters: اختر متغير Q4_K_M. يعرض LM Studio حجم الملف قبل التنزيل — تأكد من أنه يتسع في VRAM المتاح. - 3حمّل النموذج وابدأ الدردشة
Why it matters: انقر على النموذج في الشريط الجانبي الأيسر لتحميله في الذاكرة. توزيع الطبقات على بطاقة الرسوم تلقائي حسب VRAM المكتشف. - 4ابدأ الخادم المحلي
Why it matters: "بدء الخادم" يكشف نقطة نهاية متوافقة مع OpenAI على `localhost:1234`. تتصل به تطبيقاتك ونصوصك كما لو كان API الخاص بـ OpenAI.
التكميم: أي تنسيق تختار
Q4_K_M هو القيمة الافتراضية الصحيحة لـ Qwen3 على الأجهزة الاستهلاكية. يقلّل VRAM بين 55–60% مقارنةً بـ FP16 مع أقل من 1% تدهور في MMLU وHumanEval. للتنسيقات الأخرى حالات استخدام محددة:
Q4_K_M هو أفضل تكميم لـ Qwen3 لمعظم المستخدمين: يقلّل VRAM بنسبة 55% مع أقل من 1% فقدان جودة مقارنةً بـ FP16.
يضغط التكميم أرقام النموذج من 16 بت إلى 4 بت، فيقلّل حجم الملف وVRAM المطلوب إلى النصف تقريبًا. الأمر أشبه بالانتقال من TIFF إلى JPEG عالي الجودة — ملف أصغر، ونتيجة شبه متطابقة لمعظم الاستخدامات.
- Q4_K_M (موصى به): ~5.5 GB لـ 7B. أفضل نسبة جودة لكل GB. ابدأ بهذا.
- Q8_0: ~8.5 GB لـ 7B. جودة قريبة من FP16؛ استخدمه إذا كان لديك فائض VRAM وتريد أقصى دقة.
- Q5_K_M: ~6.5 GB لـ 7B. تحسّن هامشي على Q4_K_M — اخترْه فقط إذا كانت جودة مخرجات Q4_K_M ضعيفة بوضوح لمهمتك.
- Q2_K: ~3 GB لـ 7B. أصغر ملف، لكن جودة المخرجات بالصينية تتدهور بشكل ملحوظ — تجنّبه مع Qwen3 إذا كانت الصينية جزءًا من حالة استخدامك.
- IQ4_XS: ~4.8 GB لـ 7B. تكميم imatrix أحدث يتفوق على جودة Q4_K_M بحجم أصغر قليلًا — متاح في إصدارات حديثة من llama.cpp وLM Studio 0.3+.
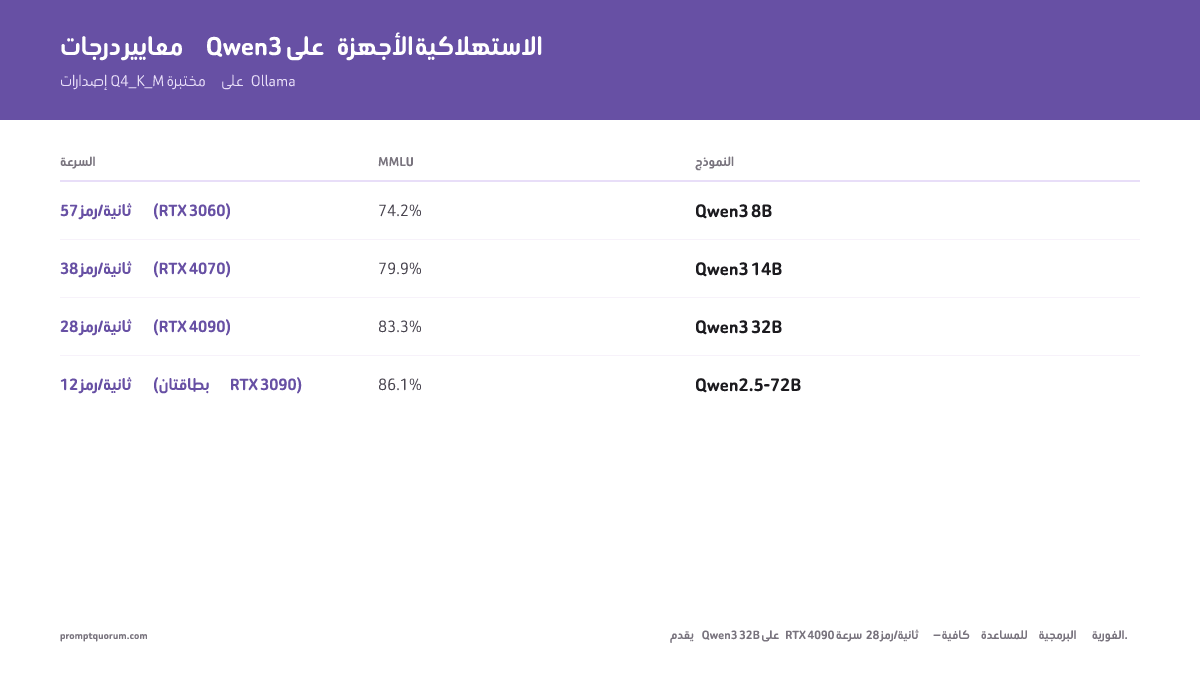
أداء المعايير على الأجهزة الاستهلاكية
يقدّم Qwen3 32B Q4_K_M على RTX 4090 سرعة 28 token/ثانية — سرعة كافية للمساعدة البرمجية في الوقت الفعلي. الدرجات أدناه تخصّ بناءات GGUF Q4_K_M المختبرة في Ollama. درجات FP16 أعلى بـ 1–2%.
| Modelo (Q4_K_M) | MMLU | Math | HumanEval | Velocidad (RTX 3060 12 GB) |
|---|---|---|---|---|
| Qwen3 8B | 74.2% | 58.8% | 57.3% | 57 tok/s |
| Qwen3 14B | 79.9% | 69.8% | 64.6% | — |
| Qwen3 32B | 83.3% | 79.5% | 71.3% | — |
| Qwen2.5-72B | 86.1% | 83.1% | 73.2% | — |
| Qwen3-Coder 7B | — | — | 75.6% | 55 tok/s |
| Qwen3-Coder 14B | — | — | 85.2% | — |
| Qwen3-Coder 32B | — | — | 92.7% | — |
Qwen مقابل DeepSeek مقابل Llama: ماذا تشغّل محليًا
يفوز Qwen3 في المهام بالصينية وكفاءة VRAM؛ ويفوز DeepSeek-V2.5 في الاستدلال واسع النطاق لكنه غير عملي على الأجهزة الاستهلاكية؛ وLlama 3.3 70B هو الخيار الأفضل على بطاقة رسوم واحدة إذا كنت تفضّل النموذج المفتوح من Meta. يقارن الجدول أدناه الخيارات العملية في كل مستوى VRAM.
| Nivel de VRAM | Mejor Qwen | Mejor competidor | Veredicto |
|---|---|---|---|
| 6 GB | Qwen3 8B | Llama 3.2 3B (يتسع، لكنه 3B فقط) | يفوز Qwen3 8B — نفس VRAM، نموذج أكبر بكثير |
| 12 GB | Qwen3-Coder 14B | Llama 3.3 8B Instruct | Qwen3-Coder 14B للكود؛ Llama 3.3 8B للدردشة العامة |
| 24 GB | Qwen3-Coder 32B | Llama 3.3 70B (مع تفريغ) | Qwen3-Coder 32B للكود؛ Llama 3.3 70B إذا كانت الجودة > السرعة |
| 48 GB+ | Qwen2.5-72B | DeepSeek-V2.5 236B MoE | يحتاج DeepSeek إلى ~130 GB من RAM؛ Qwen2.5-72B هو الخيار العملي لـ 48 GB |
المستخدمون الناطقون بالعربية: سيادة البيانات والنشر المحلي
تشغيل Qwen3 محليًا يعني أن أي بيانات لا تغادر جهازك — لا نقل إلى خوادم سحابية، ولا تعرّض بموجب GDPR أو قوانين حماية البيانات في الخليج. تتطلب واجهات API لنماذج LLM السحابية إرسال الأوامر إلى خوادم خارجية، مما يُفعّل متطلبات معالجة البيانات وعمليات النقل الدولية المحتملة.
دُرّب Qwen3 على يد فريق Qwen التابع لـ Alibaba على مجموعة نصية صينية ومتعددة اللغات في الغالب. وهو أقوى نموذج بنشر محلي للمستندات بالصينية المبسّطة والتقليدية والنصوص المختلطة (صينية/عربية/إنجليزية).
لعمليات النشر في الشركات الناطقة بالعربية: إعداد Qwen3 دون اتصال بالإنترنت أثناء الاستدلال متوافق تمامًا مع الأطر التنظيمية في السعودية (PDPL) والإمارات (قانون حماية البيانات) ودول الخليج الأخرى. يعمل النموذج بالكامل على أجهزة محلية — لا يصل أي طرف ثالث إلى بيانات الإدخال أو الإخراج. كما تتوفر بدائل عربية سيادية مثل Jais وALLaM للمؤسسات التي تفضّل نماذج عربية المنشأ. راجع تشغيل الذكاء الاصطناعي دون اتصال بالكامل للحصول على دليل كامل للإعداد المعزول.
يعمل Qwen3 دون اتصال بالكامل بعد التنزيل — لا تغادر أي بيانات جهازك، مما يلغي مخاطر نقل البيانات عبر الحدود بموجب GDPR وقوانين الخليج.
عندما تشغّل Qwen3 محليًا، لا تغادر أوامرك ومستنداتك حاسوبك أبدًا. لا استدعاءات إلى API سحابي، ولا خادم خارجي، ولا بيانات يمكن للجهات التنظيمية أو الأطراف الثالثة الوصول إليها.
توصيات الأجهزة حسب الميزانية
RTX 3060 12 GB هي أفضل نقطة دخول لـ Qwen3 8B وQwen3-Coder 7B بأقل من 1200 ريال سعودي. لنماذج 14B، تضيف RTX 4070 12 GB سرعة 35% بنحو 1800–2000 ريال سعودي جديدة.
- اقتصادي (Qwen3 8B): NVIDIA RTX 4060 8 GB أو RTX 3060 12 GB. كلاهما يتعامل مع نماذج 7B بـ 50–57 token/ثانية. غالبًا ما تكون RTX 3060 12 GB أرخص مستعملة وتملك هامش VRAM أكبر.
- متوسط (Qwen3 14B): RTX 4070 12 GB أو RTX 4070 Super 12 GB. تشغّل 4070 Super نموذج Qwen3-Coder 14B بـ 38–42 token/ثانية وتترك 2–3 GB من VRAM حرة للسياق.
- فئة عليا (Qwen3 32B): RTX 4090 24 GB أو RTX 3090 24 GB. تقدّم 4090 سرعة 27–28 token/ثانية على Qwen3-Coder 32B — سرعة مساعدة برمجية في الوقت الفعلي. وRTX 3090 أرخص بكثير مستعملة وتؤدي ضمن 15% من 4090 في الاستدلال.
- Apple Silicon (جميع الأحجام): يقدّم Mac mini M4 Pro 48 GB أفضل نسبة جودة/سعر لتشغيل Qwen3 32B (~22 token/ثانية) بضجيج واستهلاك منخفضين.
- حاسوب صغير للاستخدام المتواصل: MINISFORUM UM890 Pro أو حاسوب AMD Ryzen AI مماثل. يشغّل Qwen3 8B على CPU+iGPU بـ ~8–12 token/ثانية — بطيء لكنه قادر على العمل على مدار الساعة باستهلاك أقل من 35 واط.
الأخطاء الشائعة عند تشغيل Qwen3 محليًا
- استخدام الأمر `ollama pull qwen2.5` دون وسم حجم. بدون وسم حجم صريح (`:7b`، `:14b`، إلخ)، قد يُحل Ollama إلى الحجم الافتراضي، الذي قد يتغير بين تحديثات المكتبة. استخدم دائمًا وسومًا صريحة: `ollama pull qwen2.5:14b`.
- تجاهل حجم نافذة السياق. يدعم Qwen3 سياق 128K، لكن Ollama يستخدم 2K افتراضيًا لـ `num_ctx`. إذا كنت تعالج مستندات طويلة، أضف `--num-ctx 8192` (أو أكثر) إلى أمر التشغيل — وإلا يقتطع النموذج الإدخال بصمت.
- اختيار تكميم Q2_K للاستخدام بالصينية. بدقة 2 بت، تتدهور مخرجات Qwen3 بالصينية بشكل ملحوظ. استخدم Q4_K_M كحد أدنى لأي عمل بالصينية.
- تشغيل نموذج 32B بـ VRAM قليل. إذا كانت بطاقة الرسوم تملك 16 GB والنموذج يحتاج إلى 20.5 GB، يفرّغ Ollama الطبقات إلى RAM النظام. يعمل النموذج لكن بـ 3–5 token/ثانية — غير قابل للاستخدام التفاعلي. راجع جدول الأجهزة واختر نموذجًا يتسع في VRAM لديك.
- استخدام العائلة الفرعية الخاطئة للبرمجة. يسجّل Qwen3 8B (استخدام عام) 57.3% في HumanEval. ويسجّل Qwen3-Coder 7B نسبة 75.6% في المعيار نفسه — تحسّن نسبي بنسبة 32%. إذا كانت حالة استخدامك هي الكود، استخدم دائمًا متغير Coder بالحجم نفسه.
الخطوات التالية
- أفضل نماذج LLM للمعالج فقط — ليس لديك GPU؟ اكتشف أحجام Qwen3 التي تعمل على المعالج فقط →
- شرح تحديد دقة LLM — تبحث عن الفرق بين Q4_K_M وQ8؟ شرح التحديد الدقي →
الأسئلة الشائعة
كم من VRAM أحتاج لتشغيل Qwen3 8B محليًا؟
يتطلب Qwen3 8B Q4_K_M 5.5 GB من VRAM. تكفي RTX 3060 6 GB أو RTX 4060 أو شريحة Apple M بذاكرة موحدة 8 GB.
ما أفضل نموذج Qwen للبرمجة محليًا؟
Qwen3-Coder 32B — 92.7% في HumanEval، يحتاج إلى بطاقة رسوم بسعة 24 GB. بـ 12 GB من VRAM أو أقل: Qwen3-Coder 14B (85.2%، 9.5 GB من VRAM).
كيف يقارن Qwen بـ DeepSeek للنشر المحلي؟
يستخدم Qwen3 بنية كثيفة متوافقة مع الأجهزة الاستهلاكية. DeepSeek-V2.5 نموذج MoE بحجم 236B يحتاج إلى ~130 GB من RAM — غير عملي دون بطاقة رسوم خوادم.
هل يمكنني تشغيل Qwen على جهاز Mac؟
نعم. يشغّل M2 Pro 32 GB نموذج Qwen3 14B بـ ~32 token/ثانية. ويتعامل M3 Max 64 GB مع Qwen3 32B بـ ~22 token/ثانية.
ما أمر Ollama الذي أستخدمه لـ Qwen؟
للنموذج الرائد، `ollama run qwen3.6:27b` (~17 GB من VRAM). لـ Qwen3، `ollama pull qwen3:8b`. لـ Qwen2.5، `ollama pull qwen2.5:7b` لـ 7B، و`:14b` لـ 14B، و`:32b` لـ 32B، أو `qwen2.5-coder:32b` لمتغير البرمجة. استخدم دائمًا وسوم حجم صريحة.
هل Qwen مناسب للمهام باللغة الصينية؟
نعم. دُرّب Qwen3 مسبقًا على مجموعة نصية صينية ضخمة ويدعم أصليًا الصينية المبسّطة والتقليدية واليابانية والكورية و24 لغة أخرى.
أي تكميم ينبغي أن أستخدم لـ Qwen3؟
Q4_K_M افتراضيًا — يقلّل VRAM بنحو 55% مقارنةً بـ FP16 مع أقل من 1% فقدان جودة. تجنّب Q2_K للاستخدام بالصينية.
هل يعمل Qwen2-VL لـ OCR للمستندات الصينية؟
نعم — `ollama pull qwen2-vl:7b`، ~6 GB من VRAM، يقرأ نص CJK بدقات تصل إلى 4096×4096 بكسل.