Key Takeaways
- نماذج 7B: 8 GB كحد أدنى (Q4)، مريحة بـ 10 GB (Q5)، 14 GB لـ Q8 بدقة كاملة.
- نماذج 13B: 10 GB كحد أدنى (Q4)، مريحة بـ 12-14 GB (Q5)، 16 GB لـ Q8.
- نماذج 70B: 24 GB كحد أدنى (Q4)، 32 GB+ لـ Q5/Q8 أو إعداد متعدد المستخدمين.
- يقلّل التكميم (Q4, Q5, Q8) من VRAM بنسبة 50-75% مقارنة بالدقة الكاملة (FP32).
- احتسب دائمًا 1-2 GB إضافية للعبء (ذاكرة KV، حالة المُحسّن، نظام التشغيل).
- batch size ≠ VRAM لكل استدلال. يستخدم الاستدلال الفردي VRAM نفسها بغض النظر عن الـ batch (تُعالَج الدفعة تسلسليًا).
- مزيد من VRAM لا يسرّع استدلال prompt واحد. يساعد فقط في الإعدادات متعددة المستخدمين/الطلبات.
قاعدة عامة لـ VRAM — مرجع سريع
لا وقت للصيغة؟ استخدم هذه القواعد البسيطة:
بمجرد معرفة ميزانية VRAM لديك، راجع أي GPU تناسب كل مستوى ←
- نماذج 3B (Phi, StableLM): 4 GB من VRAM كحد أدنى
- نماذج 7B (Llama, Mistral, Qwen): 8 GB من VRAM (Q4)، 10 GB (Q5)
- نماذج 13B (Llama 3.3, Mistral): 12 GB من VRAM كحد أدنى (Q4)
- نماذج 22B (Qwen3, Gemma): 16 GB من VRAM (Q4)
- نماذج 70B (Llama 3.3, Qwen 3.6): 24–32 GB من VRAM (Q4–Q5)
- نماذج MoE: تتوسّع VRAM مع الأوزان التي يجب إبقاؤها في الذاكرة. مثال: Qwen 3.6 35B-A3B (3B نشطة) يتسع في بصمة ضئيلة ~2 GB، بينما لا يزال Llama 4 Scout (17B نشطة / 109B إجمالي) يحتاج ~55 GB بـ Q4 لأن كل الخبراء يبقون مقيمين
# Quick VRAM formula (memorize this)
VRAM (GB) ≈ Model Size (B) ÷ 8 # at Q4 quantization
# Examples:
7B ÷ 8 = 0.875 GB per billion ≈ 8 GB total
70B ÷ 8 = 8.75 GB per billion ≈ 48 GB total
# For other quantizations:
Q8 (8-bit): Model Size ÷ 4
Q5 (5-bit): Model Size ÷ 5
FP32 (full): Model Size × 4ما صيغة VRAM لنماذج LLM؟
VRAM (GB) = (حجم النموذج بالمليار × 4 بايت × عامل التكميم)
- حجم النموذج: عدد المعاملات (7B, 13B, 70B, إلخ)
- 4 بايت: دقة FP32 (1 بايت = 8 بت)
- عامل التكميم: 1.0 (FP32)، 0.5 (Q8)، 0.25 (Q4)
مثال: Llama 3 70B، FP32، دون تكميم:
70 مليار × 4 بايت = 280 GB. غير عملي.
Llama 3 70B، تكميم Q4 (4 بت):
70 مليار × 4 بايت × 0.25 = 70 GB مخصصة، ~24 GB مستخدمة بعد الضغط.
نماذج MoE (المتفرقة): تحدد المعاملات النشطة الحوسبة، لكن يجب أن يبقى كل الخبراء محمّلين في VRAM. مثال: Llama 4 Scout لديه 109B معامل إجمالي مع 17B نشطة لكل token. بـ Q4 لا يزال يحتاج ~55 GB من VRAM لإبقاء كل الخبراء — يتسع في GPU بسعة 24 GB فقط بتكميم عدواني 1.78 بت (~20 tok/s). الحوسبة رخيصة؛ الذاكرة هي القيد.
كم تحتاج كل حجم نموذج من VRAM؟
| حجم النموذج | FP32 (دون تكميم) | Q8 (8 بت) | Q5 (5 بت) | Q4 (4 بت) | GPU الموصى بها |
|---|---|---|---|---|---|
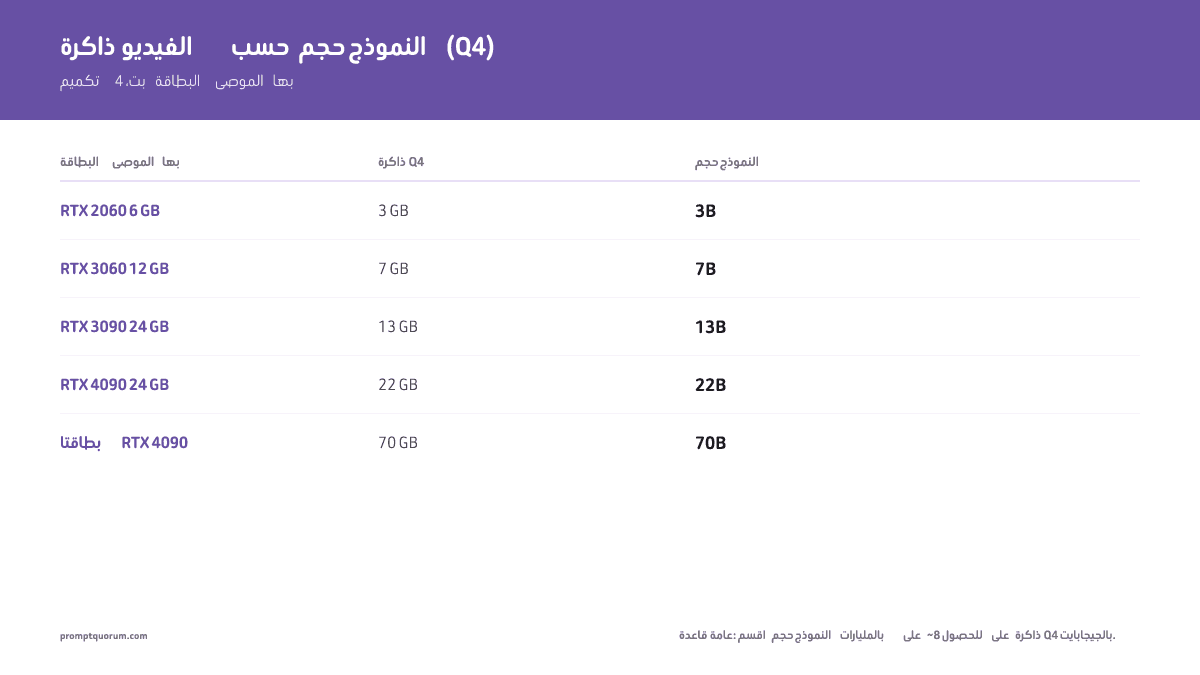
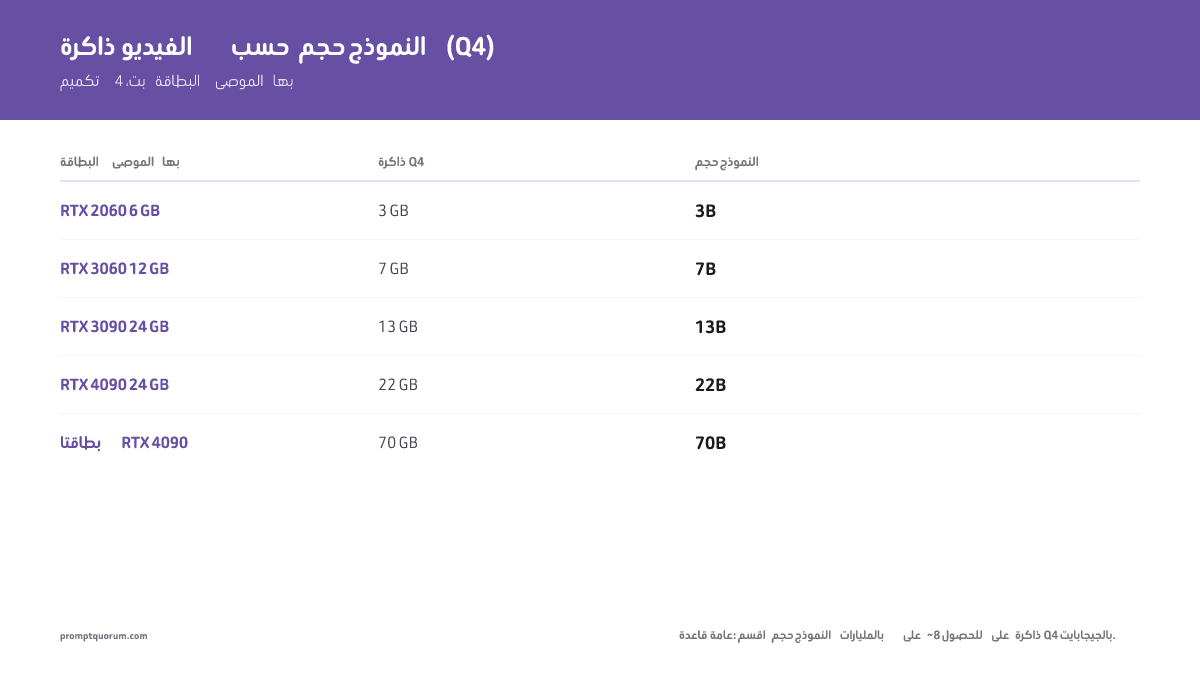
| 3B (Phi, StableLM) | 12 GB | 6 GB | 4 GB | 3 GB | RTX 2060 6 GB أو RTX 5070 12 GB |
| 7B (Llama 3.3, Mistral) | 28 GB | 14 GB | 9 GB | 7 GB | RTX 3060 12 GB أو RTX 5070 12 GB |
| 13B (Llama 3.3, Mistral) | 52 GB | 26 GB | 17 GB | 13 GB | RTX 3090 24 GB أو RTX 5080 16 GB |
| 22B (Qwen, Gemma) | 88 GB | 44 GB | 28 GB | 22 GB | RTX 4090 24 GB (Q4) أو RTX 5090 32 GB |
| 70B (Llama 3, Qwen) | 280 GB | 140 GB | 88 GB | 70 GB | 2× RTX 4090 (24 GB لكل منها)، أو 1× H100 80 GB |
| Qwen 3.6 35B-A3B (3B نشطة، MoE)* | 12 GB | 3 GB | 2 GB | 2 GB | RTX 2060 6 GB أو RTX 5070 12 GB |
| DeepSeek V4-Flash (13B نشطة / 284B إجمالي، MoE)* | 52 GB | 13 GB | 8 GB | 7 GB | RTX 3060 12 GB أو RTX 5070 12 GB |
| Llama 4 Scout (17B نشطة / 109B إجمالي، MoE)† | 436 GB | 109 GB | 68 GB | 55 GB | 2× RTX 4090 (48 GB) — يتسع في 24 GB فقط بـ 1.78 بت (~20 tok/s) |
| gpt-oss:20b (3.6B نشطة / 21B إجمالي، MoE)* | 84 GB | 21 GB | 13 GB | 12 GB | RTX 5070 12 GB أو أي GPU بسعة 16 GB |
| Kimi K2.6 (32B نشطة / 1T إجمالي، MoE)* | 128 GB | 32 GB | 20 GB | 16 GB | 2× RTX 4090 أو RTX 5090 32 GB (Q4 فقط) |
* نماذج MoE: تُحسب VRAM من المعاملات النشطة فقط، لا من حجم النموذج الإجمالي. † يُبقي Llama 4 Scout كل الـ 109B معامل مقيمة، لذا يحتاج ~55 GB بـ Q4 رغم وجود 17B نشطة فقط لكل token.
تحتاج نماذج MoE إلى VRAM أقل بكثير مما يوحي به حجمها
توزّع نماذج Mixture-of-Experts (MoE) معاملاتها بين شبكات فرعية "خبيرة" عديدة وتفعّل جزءًا منها فقط لكل token. تقلّل المعاملات النشطة الحوسبة وتسرّع الاستدلال، لكن في معظم نماذج MoE يجب أن يبقى كل الخبراء محمّلين في VRAM — لذا يتبع استخدام الذاكرة إجمالي المعاملات لا النشطة.
القاعدة للنماذج الكثيفة: VRAM = المعاملات_الإجمالية × بايت_لكل_معامل
القاعدة لنماذج MoE (الحوسبة): تحدد المعاملات_النشطة الـ tokens/ثانية — لكن VRAM لا تزال تتوسّع مع الأوزان الإجمالية المقيمة.
مثال: Llama 4 Scout لديه 109B معامل إجمالي مع 17B نشطة فقط لكل token. سريع لحجمه، لكنه بـ Q4 لا يزال يحتاج ~55 GB من VRAM لإبقاء كل الخبراء — خارج متناول GPU واحدة بسعة 24 GB إلا بتكميم عدواني 1.78 بت (~20 tok/s على RTX 4090).
تستطيع بعض بيئات التشغيل بثّ الخبراء غير النشطين أو إنزالهم إلى RAM النظام، مضحّيةً بالسرعة مقابل بصمة VRAM أقل. الخلاصة الأساسية: لا تفترض أن نموذج MoE يتسع في VRAM بحجم معاملاته النشطة — تحقّق من الحجم الفعلي على القرص لمستوى التكميم لديك.
كيف يقلّل التكميم متطلبات VRAM؟
يقلّل التكميم عدد البتات اللازمة لتمثيل كل معامل في النموذج.
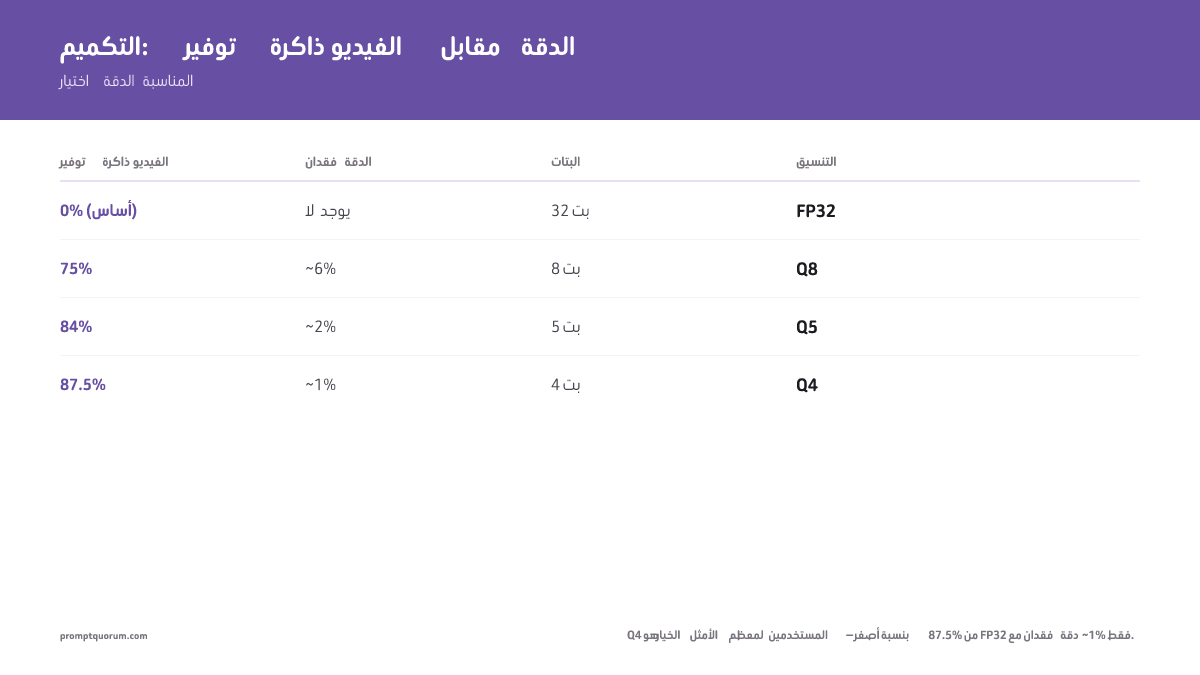
- FP32 (عدد عشري 32 بت): دقة كاملة. 1 معامل = 4 بايت. دون فقدان. الأبطأ.
- Q8 (8 بت): 1 معامل = 1 بايت. ~6% فقدان دقة. 75% توفير في VRAM.
- Q5 (5 بت): 1 معامل = 0.625 بايت. ~2% فقدان دقة. 84% توفير في VRAM.
- Q4 (4 بت): 1 معامل = 0.5 بايت. ~1% فقدان دقة. 87.5% توفير في VRAM.
لمعظم المستخدمين، Q4 هي النقطة المثالية: فقدان دقة غير محسوس، وبصمة VRAM أقل بنسبة 87%.
اعتبارًا من أبريل 2026، Q4 هي المعيار. وتتوفر Q5 و Q8 إذا كان لديك VRAM فائضة وتريد مكاسب جودة هامشية.
تحدد VRAM حجم النموذج، لكن تصميم الـ prompt يحدد جودة المخرجات. تستطيع تقنيات مثل chain-of-thought و few-shot prompting سد فجوة الجودة بين النماذج الأصغر والأكبر. استكشف مجموعة أدوات هندسة الـ prompt الكاملة للاستفادة أكثر من النماذج التي يدعمها جهازك. وإذا كان لديك 12–16 GB من VRAM وتريد حمل برمجة محددًا لتجربة تلك المجموعة، فإن استبدال GitHub Copilot بنموذج LLM محلي يربط حزمة Continue.dev + Ollama + Qwen3-Coder بدقة بمستويات VRAM تلك.
ماذا عن batch size والاستدلال متعدد المستخدمين؟
يؤثر batch size في الإنتاجية (tokens في الثانية)، لا في زمن استجابة استدلال فردي.
مستخدم واحد يسأل "كم 2+2؟" يستخدم VRAM نفسها بغض النظر عمّا إذا كان batch size 1 أو 32.
batch size = 32 يعني معالجة 32 prompt على التوازي. يستخدم هذا ~32× أكثر من VRAM، لكنه يولّد 32 إجابة أسرع.
لمستخدم واحد (الاستخدام النموذجي لـ LLM محلي): batch size = 1. تكون VRAM هي حجم النموذج + 1-2 GB عبء.
لخادم متعدد المستخدمين: خصّص batch size × VRAM النموذج. يحتاج نموذج 70B بـ batch=4 إلى ~96 GB (24 GB × 4).
هل تحتاج VRAM أكثر من حجم النموذج؟
نعم. إضافةً إلى أوزان النموذج، أضف:
- ذاكرة KV (ذاكرة المفتاح-القيمة للسياق): ~5-10% VRAM إضافية.
- حالة المُحسّن (عند الـ fine-tuning): 2-4× حجم النموذج (متعلقة بالتدريب فقط، لا بالاستدلال).
- عبء النظام (نظام التشغيل، التعريفات، بيئة تشغيل Ollama/LM Studio): ~1-2 GB.
القاعدة: نموذج 70B Q4 (20 GB) + ذاكرة KV (2 GB) + نظام (2 GB) = ~24 GB مخصصة.
اشترِ دائمًا GPU بهامش 1-2 GB على الأقل فوق الحد الأدنى النظري.
أخطاء شائعة حول VRAM
- مزيد من VRAM = استدلال أسرع. خطأ. لا يؤثر حجم VRAM في السرعة. أما عرض نطاق الذاكرة (GB/ثانية) فيؤثر، وهو ثابت لكل GPU.
- batch size = حد tokens تسلسلي. خطأ. batch size = طلبات على التوازي. يستخدم الاستدلال الفردي batch=1 بغض النظر عن حجم VRAM.
- تحتاج 24 GB لأي نموذج 70B. خطأ. Q4 يحتاج 24 GB. Q8 يحتاج 48 GB. يعتمد على التكميم.
حاسبة VRAM
اختر حجم نموذجك والتكميم لتقدير متطلبات VRAM.
Popular Models
Base Model
6.50 GB
Context OH
1.50 GB
Batch OH
0.00 GB
System OH
1.00 GB
Total Minimum
9.00 GB
Recommended (with 25% safety margin)
11.25 GB
👉 Look for a GPU with at least 11.25 GB VRAM
Compatible GPUs
RTX 3060 (12 GB)
0.8 GB headroom
RTX 4070 (12 GB)
0.8 GB headroom
RTX 4070 Ti (12 GB)
0.8 GB headroom
RTX 4080 (16 GB)
4.8 GB headroom
RTX 4090 (24 GB)
12.8 GB headroom
Mac mini M5 (16 GB) (16 GB)
4.8 GB headroom
Mac mini M4 (16 GB) (16 GB)
4.8 GB headroom
MacBook Pro (24 GB) (24 GB)
12.8 GB headroom
M3 Max (36 GB) (36 GB)
24.8 GB headroom
💡 Pro Tips:
- Always use the "with safety margin" figure when buying a GPU
- Q4 gives 90-95% quality with 25% size reduction. Q5 is better if you have room
- Context overhead grows with conversation length. Budget 1-3 GB for typical usage
- Batch size matters for multi-user APIs. Single-user chat can ignore batch overhead
📋 Share this configuration:
الأسئلة الشائعة
هل يمكنني تشغيل Mistral Small على GPU بسعة 6 GB؟
بصعوبة، بـ Q4 مع عبء ضيّق. عمليًا، لا. اشترِ 8 GB على الأقل. ستواجه أخطاء OOM بـ 6 GB.
كم أحتاج من VRAM لعمل fine-tuning لنموذج 7B؟
لـ LoRA: 12-16 GB. fine-tuning كامل: 28 GB+. يتطلب الـ fine-tuning حالة المُحسّن (2-4× VRAM النموذج)، لا مجرد الاستدلال.
هل 12 GB كافية لـ Llama 3 13B؟
بـ Q4، بالكاد. بـ Q5 أو Q8، لا. 12 GB ضيّقة جدًا. 16 GB مريحة.
هل أحتاج 24 GB لنموذج 70B؟
بـ Q4، نعم. بـ Q5+، لا. التكميم الأعلى (Q5, Q8) يحتاج 32 GB+ لـ 70B.
هل تقليل batch size يقلّل VRAM للاستدلال الفردي؟
لا. يستخدم الاستدلال الفردي دائمًا VRAM لـ batch=1. يساعد batch size في الإنتاجية فقط (سيناريوهات متعددة المستخدمين).
ما أفضل تكميم للدقة؟
Q8 فقدانه غير محسوس تقريبًا. Q5 فقدانه ~2%. Q4 فقدانه ~1%. للأغلب، Q4 هي النقطة المثالية.
هل يمكنني إنزال جزء من VRAM إلى RAM الخاصة بـ CPU؟
نعم، عبر تقسيم الطبقات (NVLink). يدعمه Llama.cpp و Ollama. تنخفض الإنتاجية بنسبة 30-50% لكنه يعمل. أقل من 8 GB من VRAM؟ راجع **أي النماذج تعمل أسرع على مستوى جهازك الدقيق** — معايير بأرقام tok/ثانية حقيقية لـ CPU فقط و4 GB و6 GB و8 GB من VRAM.
المصادر
- توثيق بنية ذاكرة CUDA ونموذج الذاكرة المشتركة من NVIDIA
- التوثيق الرسمي لـ Ollama و LM Studio: متطلبات VRAM للنماذج ومواصفات التكميم
- مشروع llama.cpp على GitHub: مستويات التكميم (Q4, Q5, Q8) وحسابات الذاكرة