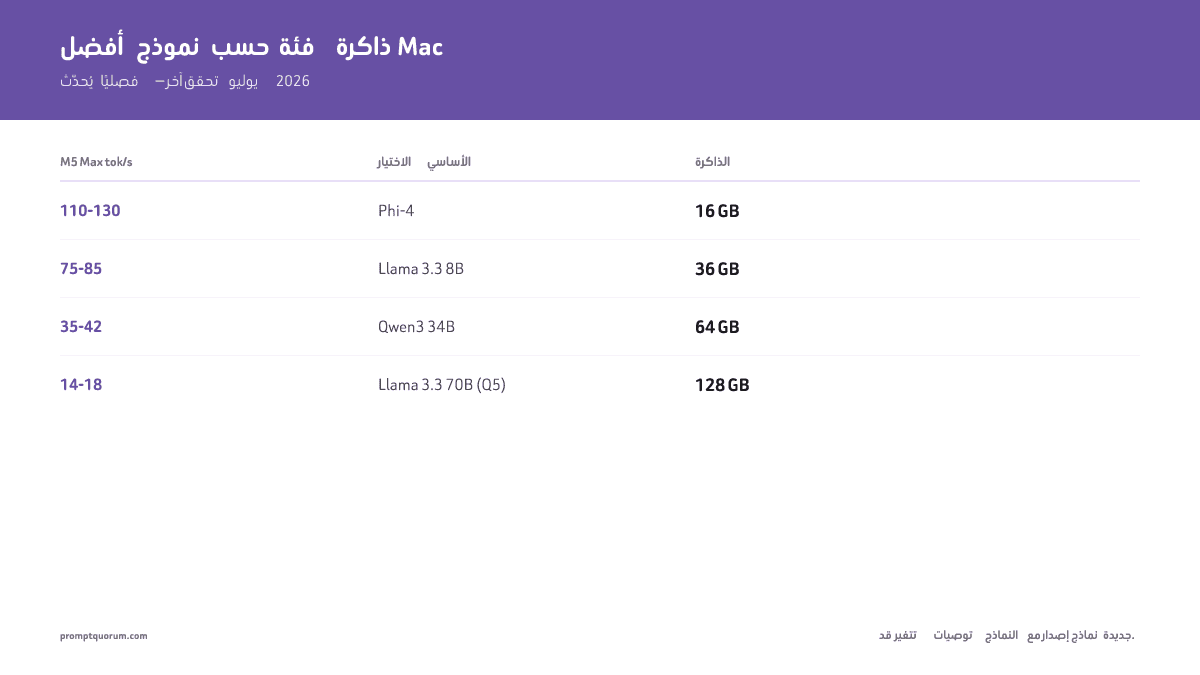
أفضل توصيات النماذج حسب ذاكرة Mac
آخر تحقق: 2026-07-14. قد تتغير التوصيات مع الإصدارات الجديدة. نحدّث هذه الصفحة فصلياً.
| الذاكرة | الاختيار الأول | التكميم | الحجم | M5 Pro tok/s | M5 Max tok/s | البديل |
|---|---|---|---|---|---|---|
| 16 GB | Phi-4 | Q4_K_M | 2.5 GB | 60–70 | 110–130 | Llama 3.3 8B Q4 (ضيق) |
| 36 GB | Llama 3.3 8B | Q8 | 8.5 GB | 38–45 | 75–85 | Qwen3 14B Q4 (8.5 GB) |
| 48 GB | Qwen3 14B | Q8 | 16 GB | 25–30 | 50–60 | Mixtral 8x22B Q4 (26 GB) |
| 64 GB | Qwen3 34B | Q5 | 24 GB | 18–22 | 35–42 | Mixtral 8x22B Q5 (32 GB) |
| 96 GB | Llama 3.3 70B | Q4 | 42 GB | 10–13 | 20–25 | Qwen3 72B Q4 (44 GB) |
| 128 GB | Llama 3.3 70B | Q5 | 49 GB | 8–11 | 14–18 | Qwen3 72B Q5 (51 GB) |
| 128 GB | Llama 3.3 70B | Q8 | 74 GB | N/A | 9–12 | أفضل جودة، M5 Max فقط |
الأحجام بصيغة GGUF. المكافئات MLX بدقة 4-bit متقاربة. قد تختلف الأسعار حسب بلدك.
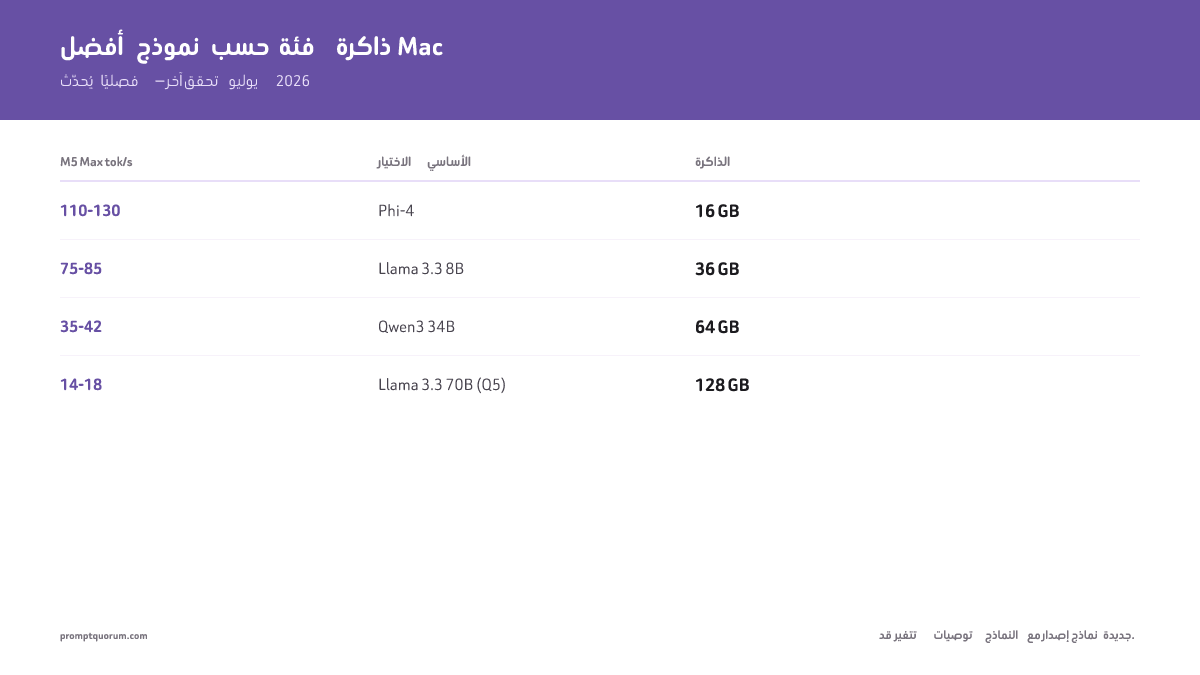
معايير جودة النماذج (اختبارات قياسية 2026)
| النموذج | MMLU | HumanEval | GSM8K | المتوسط | ملاحظات |
|---|---|---|---|---|---|
| Phi-4 (3.8B) | 84.8 | 82.6 | 91.0 | 86.1 | أفضل نموذج صغير |
| Llama 3.3 8B | 73.0 | 72.6 | 84.5 | 76.7 | جيد لكل شيء |
| Qwen3 14B | 79.7 | 83.5 | 90.2 | 84.5 | استدلال متين |
| Mistral Small | 60.1 | 30.5 | 50.0 | 46.9 | قديم لكن سريع |
| Qwen3 34B | 83.3 | 88.4 | 93.0 | 88.2 | أفضل حجم متوسط |
| Mixtral 8x22B | 70.6 | 40.2 | 60.4 | 57.1 | بنية MoE |
| Llama 3.3 70B | 86.0 | 80.5 | 95.1 | 87.2 | الأفضل عموماً |
| Qwen3 72B | 86.1 | 86.6 | 95.8 | 89.5 | استدلال متفوّق |
| Llama 3.3 405B | 88.6 | 89.0 | 96.8 | 91.5 | لا يتناسب محلياً |
| GPT-5.5 (مرجع) | 88.7 | 90.2 | 95.8 | 91.6 | مرجع سحابي |
يقترب Qwen3 72B على جهاز Mac بسعة 128 GB من جودة GPT-5.5 بتكلفة تشغيل صفرية. هذا أهم تقدم في الذكاء الاصطناعي المحلي في 2026.
أفضل النماذج حسب حالة الاستخدام (2026)
| حالة الاستخدام | الأفضل لـ Mac 36 GB | الأفضل لـ Mac 64 GB | الأفضل لـ Mac 128 GB |
|---|---|---|---|
| البرمجة (عام) | Llama 3.3 8B | DeepSeek Coder V2 16B | Llama 3.3 70B |
| البرمجة (Python) | DeepSeek Coder V2 Lite | DeepSeek Coder V2 16B | DeepSeek Coder V2 236B |
| الكتابة الطويلة | Llama 3.3 8B Q8 | Qwen3 34B Q5 | Llama 3.3 70B Q5 |
| الدردشة / المحادثة | Mistral Small | Mixtral 8x22B | Llama 3.3 70B |
| الاستدلال / الرياضيات | Qwen3 14B | Qwen3 34B | Qwen3 72B |
| RAG / الأسئلة والأجوبة | Llama 3.3 8B + nomic-embed | Llama 3.3 8B + bge-large | Llama 3.3 70B + bge-large |
| الرؤية / متعدد الوسائط | LLaVA 7B | Llama 3.2 Vision 11B | Llama 3.2 Vision 90B |
| الترجمة | Qwen3 14B | Qwen3 34B | Aya Expanse 32B |
| التلخيص | Llama 3.3 8B | Qwen3 34B | Llama 3.3 70B |
| مراجعة الكود | DeepSeek Coder V2 Lite | DeepSeek Coder V2 16B | Llama 3.3 70B |
كثيراً ما تتفوق النماذج المتخصصة على العامة في المهام المحددة. يتفوق DeepSeek Coder على Llama 3.3 في الكود حتى عندما يكون Llama هو النموذج الأكبر.
تكوينات حقيقية حسب نوع المستخدم
💡Tip: مطوّر مستقل (Mac Mini M5 Pro 64 GB، 1,200 دولار) - البرمجة: DeepSeek Coder V2 Lite (16B Q4، 10 GB) - الكتابة: Llama 3.3 8B Q8 (8.5 GB) للتوثيق والبريد - دائم التشغيل: كلا النموذجين محمّلان مع `OLLAMA_MAX_LOADED_MODELS=2` - التكلفة اليومية: 0 دولار (مقابل 30–100 دولار/شهرياً لـ Copilot + ChatGPT) - قد تختلف الأسعار حسب بلدك.
💡Tip: محترف يهتم بالخصوصية (MacBook Pro M5 Pro 48 GB، 2,500 دولار) - الأساسي: Llama 3.3 8B Q8 للعمل العام - الحساس: Qwen3 14B Q5 للمستندات القانونية/الطبية/المالية - السفر: يعمل دون اتصال في الطائرات والبيئات الآمنة - لا تغادر أي بيانات الحاسوب - قد تختلف الأسعار حسب بلدك.
💡Tip: باحث / مهندس ML (Mac Studio M5 Max 128 GB، 4,000 دولار) - الأساسي: Llama 3.3 70B Q5 (49 GB) للجودة - المتخصص: Qwen3 72B Q4 للبحث بلغات أخرى - البرمجة: DeepSeek Coder V2 16B - الرؤية: Llama 3.2 Vision 11B لأشكال المقالات - النماذج الأربعة محمّلة في آن واحد - قد تختلف الأسعار حسب بلدك.
💡Tip: خادم ذكاء اصطناعي عائلي (Mac Mini M5 Pro 64 GB، دائم التشغيل) - مساعد صوتي: Llama 3.3 8B + Whisper + Piper - RAG: أسئلة وأجوبة حول مستندات العائلة بالتضمينات - مساعدة برمجية لأفراد العائلة عبر REST API - تكلفة الكهرباء: ~35 دولار/سنوياً - يحل محل: ChatGPT Plus لـ 4 أشخاص = 1,000 دولار/سنوياً - قد تختلف الأسعار حسب بلدك.
نماذج يجب تجنّبها في 2026 (ولماذا)
⚠️Warning: Llama 2 (أي حجم) لم يعد موصى به — تم استبداله بـ Llama 3.3؛ تُظهر لوحات الصدارة القياسية نتائج أضعف بشكل ملحوظ مقارنةً بالإصدارات الأحدث. لا يزال يظهر في الدروس القديمة — لا تتبعها. استبدله بـ: Llama 3.3 8B.
⚠️Warning: تجنّب Vicuna وAlpaca وWizardLM — ضبط دقيق مجتمعي من 2023. تضاهي النماذج الأساسية الحديثة (Llama 3.3، Qwen3) أداءها أو تتفوق عليه. استبدلها بـ: Qwen3 14B أو Llama 3.3 8B.
⚠️Warning: تجنّب Falcon 180B — لا يتناسب مع Apple Silicon الاستهلاكي. يتفوق عليه Llama 3.3 70B (الأصغر). استبدله بـ: Llama 3.3 70B Q5.
⚠️Warning: تجنّب تكميم FP16 على العتاد الاستهلاكي — Llama 3.3 70B FP16 = 140 GB، لا يتناسب مع أي جهاز Mac. مكسب الجودة مقابل Q5 أقل من 1%. استبدله بـ: Q4_K_M أو Q5_K_M.
⚠️Warning: تجنّب النماذج الأساسية الصرفة (دون إصدار instruct) — تكمل النماذج الأساسية النص لكنها لا تتبع التعليمات. ابحث عن اللاحقة "-instruct" أو "-chat". استبدلها بـ: إصدار instruct من النموذج نفسه.
⚠️Warning: توخَّ الحذر مع النماذج ذات نشاط التطوير المنخفض — StableLM، RedPajama، MPT، Pythia: ذات نشاط تطوير حديث منخفض (منتصف 2026). استخدم نماذج من Meta وAlibaba وMistral وMicrosoft ذات التحديثات المنتظمة.
مرجع سريع لصيغ النماذج
| الصيغة | يستخدمها | الحجم مقابل الأصلي |
|---|---|---|
| GGUF Q4_K_M | Ollama, llama.cpp | ~30% من FP16 |
| GGUF Q5_K_M | Ollama, llama.cpp | ~35% من FP16 |
| GGUF Q8_0 | Ollama, llama.cpp | ~50% من FP16 |
| MLX 4-bit | إطار MLX | ~30% من FP16 |
| MLX 8-bit | إطار MLX | ~50% من FP16 |
| FP16 (الأصلي) | جميع الأطر | 100% |
الأحجام في هذا المقال بصيغة GGUF Q4_K_M ما لم يُذكر خلاف ذلك. المكافئات MLX بدقة 4-bit بحجم مماثل. للبايتات الدقيقة، راجع بطاقة النموذج على HuggingFace. يشغّل llama.cpp صيغة GGUF مباشرةً عبر واجهة Metal الخلفية، وهو ما تستخدمه Ollama داخلياً — أما MLX فهو إطار Apple الخاص ويميل إلى أن يكون أسرع مع البنى المصممة خصيصاً لـ MLX على الشريحة نفسها. يدعم LM Studio كلاً من GGUF وMLX ويتيح تبديل الواجهة الخلفية لكل نموذج من واجهته.
مرجع سريع: تنزيل هذه النماذج
# Mac 16 GB
ollama pull phi4
# Mac 36 GB (elige uno)
ollama pull llama3.3:8b
ollama pull qwen3:14b
ollama pull mistral-small
# Mac 64 GB
ollama pull qwen3:34b
ollama pull mixtral:8x22b
# Mac 128 GB
ollama pull llama3.3:70b
ollama pull qwen3:72b
# Modelos especializados
ollama pull deepseek-coder-v2:16b # programación
ollama pull llama3.2-vision:11b # visión
ollama pull aya-expanse:32b # traducciónهل يمكنني تشغيل نموذجين مختلفين في آن واحد؟
نعم، اضبط `OLLAMA_MAX_LOADED_MODELS=2` في متغيرات البيئة. مع 64 GB يمكنك تشغيل 8B + 34B في آن واحد.
أي نموذج أفضل للمبتدئين؟
Llama 3.3 8B. متاح على نطاق واسع، بجودة إخراج جيدة وسجل مُثبت. يعمل على أي Mac M1+.
هل Mixtral 8x22B أسرع من Llama 8B؟
لا، إنه أبطأ قليلاً (40–50 tok/s مقابل 50–60 tok/s على M5 Pro). لكن الاستدلال أعلى.
ما أفضل LLM محلي في 2026؟
لمعظم المستخدمين على Apple Silicon: يتصدّر Qwen3 (بأي حجم يتناسب مع جهاز Mac لديك) حالياً معايير الجودة. Llama 3.3 70B مماثل على أجهزة Mac بسعة 128 GB. دون 16 GB: يتفوق Phi-4 على فئته بـ 3.8B معامل، مضاهياً نماذج 8B من 2024.
هل يمكنني تشغيل Llama 3.3 405B على جهاز Mac؟
لا. يتطلب Llama 3.3 405B أكثر من 200 GB حتى مع تكميم Q4 — لا يملك أي Mac استهلاكي ذاكرة موحدة كافية. انتظر M5 Ultra (متوقع منتصف 2026، 256 GB) — سيكون أول عتاد استهلاكي قادر على تشغيل 405B بصيغة Q3–Q4.
هل Qwen أفضل من Llama للاستخدام المحلي؟
في معظم المهام، يتفوق Qwen3 قليلاً على Llama 3.3 بنفس عدد المعاملات في المعايير (1–3 نقاط في MMLU). يملك Llama مجتمعاً أوسع ومزيداً من إصدارات الضبط الدقيق المتاحة. لن يلاحظ معظم المستخدمين الفرق — اختر حسب التوافر ونظام الضبط الدقيق.
ما أصغر نموذج مفيد فعلاً؟
Phi-4 بـ 3.8B معامل. يحصل على 84.8 في MMLU — مضاهياً بعض نماذج 8B من 2024. للدردشة والأسئلة والأجوبة، إنه قادر بشكل مفاجئ. للبرمجة أو الاستدلال المعقد، انتقل إلى Llama 3.3 8B أو Qwen3 14B.
هل يعمل vLLM على Apple Silicon؟
دعم vLLM لـ Metal محدود مقارنةً بمساره على CUDA — تحسينات الإنتاجية والتجميع (batching) التي تجعل vLLM جذاباً على معالجات Nvidia الرسومية لا تنطبق إلى حد كبير على Mac. بالنسبة لـ Apple Silicon، تمنحك Ollama (llama.cpp/Metal) أو LM Studio (GGUF/MLX) معدل tok/s أفضل للمستخدم الواحد وإعداداً أسهل. لا تفكّر في vLLM إلا إذا كنت تخدم عدداً كبيراً من الطلبات المتزامنة من جهاز Linux/Nvidia إلى جانب جهاز Mac لديك.
ماذا يمكن لجهاز MacBook Air M5 تشغيله؟
يأتي MacBook Air M5 بتصميم بلا مروحة وعادةً بذاكرة موحدة تتراوح بين 16 و32 GB، لذا عامله كجهاز Mac من فئة 16 GB أو 36 GB من الجدول أعلاه: Phi-4 براحة، وLlama 3.3 8B Q8 إذا كانت لديك 24 GB أو أكثر. قد تنخفض السرعة قليلاً في التوليد الطويل المستمر بسبب غياب المروحة — توقّع الطرف الأدنى من نطاقات tok/s الخاصة بـ M5 Pro في هذا المقال.
ما أفضل إعداد لجهاز MacBook Pro M5 Max بذاكرة 128GB؟
Llama 3.3 70B Q5 (49 GB) للاستخدام اليومي، مع مساحة كافية لإبقاء نموذج ثانٍ — Qwen3 14B Q5 أو DeepSeek Coder V2 16B — محمّلاً في الوقت نفسه عبر `OLLAMA_MAX_LOADED_MODELS=2`. توقّع نحو 14–18 tok/s على 70B Q5. إذا أردت أقصى جودة ويمكنك تحمّل نحو 9–12 tok/s، فإن Llama 3.3 70B Q8 (74 GB) يتناسب أيضاً.