Key Takeaways
- البرمجة: يتصدر Qwen 3.6 27B في SWE-bench (77.2% في العالم الحقيقي، أفضل نموذج كثيف). للبرمجة بالوكلاء: Mistral Devstral Small 24B. للإكمال التلقائي في IDE: Mistral Codestral 22B.
- الاستدلال العام: Llama 3.3 70B وQwen3 72B لا يزالان شبه متعادلين؛ Llama 3.x أقوى في الإنجليزية، وQwen في متعدد اللغات.
- الكفاءة (الجودة لكل GB من RAM): يقدّم Mistral Small 3.1 24B جودة قريبة من 70B بـ 14 GB فقط من RAM -- بلا تغيير منذ أبريل.
- اللغات غير الإنجليزية: يدعم Qwen3 29 لغة أصليًا؛ Llama وMistral محسّنان أساسًا للإنجليزية.
- سياق MoE الطويل (جديد في 2026): Llama 4 Scout (17B نشط / 109B إجمالي، 16 خبيرًا، متعدد الوسائط) يقدّم سياق 10M token، لكنه يتطلب ~55 GB من VRAM بـ Q4 -- لا يتسع في بطاقة رسوم استهلاكية بسعة 24 GB بالتكميمات العادية (إلا بدقة 1.78 بت، ~20 token/ثانية).
- نماذج قديمة لا تزال ذات صلة: Mistral Small 24B وQwen 3 14B وLlama 3.3 8B لا تزال منتشرة على نطاق واسع. يغطي قسم "مرجع المعايير القديمة" أدناه متى تُرقّي مقابل متى تبقى.
يفوز Qwen 3.6 27B في البرمجة على أجهزة المستهلكين (77.2% SWE-bench، يناسب 24 جيجابايت بضغط Q4)؛ ويتصدر Llama 4 Scout في السياق الطويل ومتعدد الوسائط (10M سياق، MoE، ~55 جيجابايت بضغط Q4).
هذه ثلاث من أشهر عائلات نماذج الذكاء الاصطناعي مفتوحة المصدر التي يمكن تشغيلها محلياً. Qwen3 (من Alibaba) يتفوق في البرمجة، وLlama 4 (من Meta) يعالج المستندات الطويلة جداً والصور، وMistral (ذكاء اصطناعي فرنسي) يوفر نماذج صغيرة فعّالة. جميعها مجانية وتعمل دون إنترنت.
•Info: 📌 هل تبحث عن المقارنة السابقة؟ انتقل إلى المعايير القديمة لـ Mistral 24B مقابل Qwen 3 14B مقابل Llama 3.3 8B أدناه.
أي عائلة نماذج مفتوحة المصدر ينبغي أن تختار؟
لا تزال نماذج الجيل السابق (Qwen3، Llama 3.3) متاحة في Ollama وتُستخدم على نطاق واسع. تركّز هذه المقارنة على نماذج الجيل الحالي. هل أنت مستعد لتشغيل أحدها؟ دليل إعداد محلي كامل لـ Qwen ←
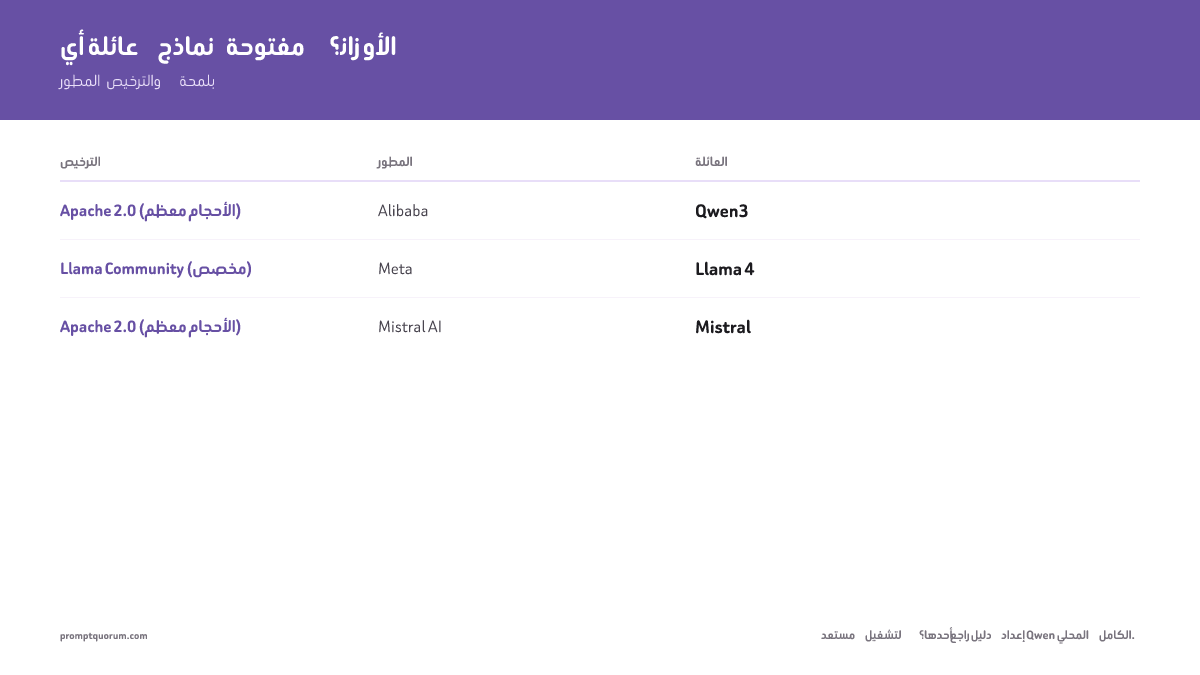
| Familia | Desarrollador | Versiones actuales | Licencia |
|---|---|---|---|
| Qwen3 | Alibaba | Qwen3 (أبريل 2026)، Qwen 3.5 (متعدد الوسائط)، Qwen 3.6 27B (SWE-bench 77.2%) | Apache 2.0 (معظم الأحجام) |
| Llama 4 | Meta | Scout (17B نشط/109B MoE، 16 خبيرًا، سياق 10M، متعدد الوسائط، ~55 GB VRAM Q4)، Maverick (17B نشط/400B MoE)، القديم: 3.3 70B | Llama Community (مخصص) |
| Mistral | Mistral AI | Small 3.1 (24B)، Devstral Small 24B (بالوكلاء)، Codestral 22B (FIM/IDE) | Apache 2.0 (معظم الأحجام) |
كيف تقارن هذه النماذج في المعايير؟
SWE-bench (حل مشكلات GitHub الحقيقية) هو معيار البرمجة الرئيسي لعام 2026 للتقييم العملي. يختبر التغييرات عبر ملفات متعددة وفهم قاعدة الكود وكتابة الاختبارات. يبقى HumanEval (دالة Python بملف واحد) مفيدًا للمقارنة لكنه ثانوي. يقيّم MMLU وMATH المعرفة العامة والاستدلال. معايير Llama 4 Scout محدودة بسبب إطلاقه الحديث وتعقيد MoE. الشرطات تشير إلى معايير لم تُنشر بعد أو غير قابلة للتطبيق.
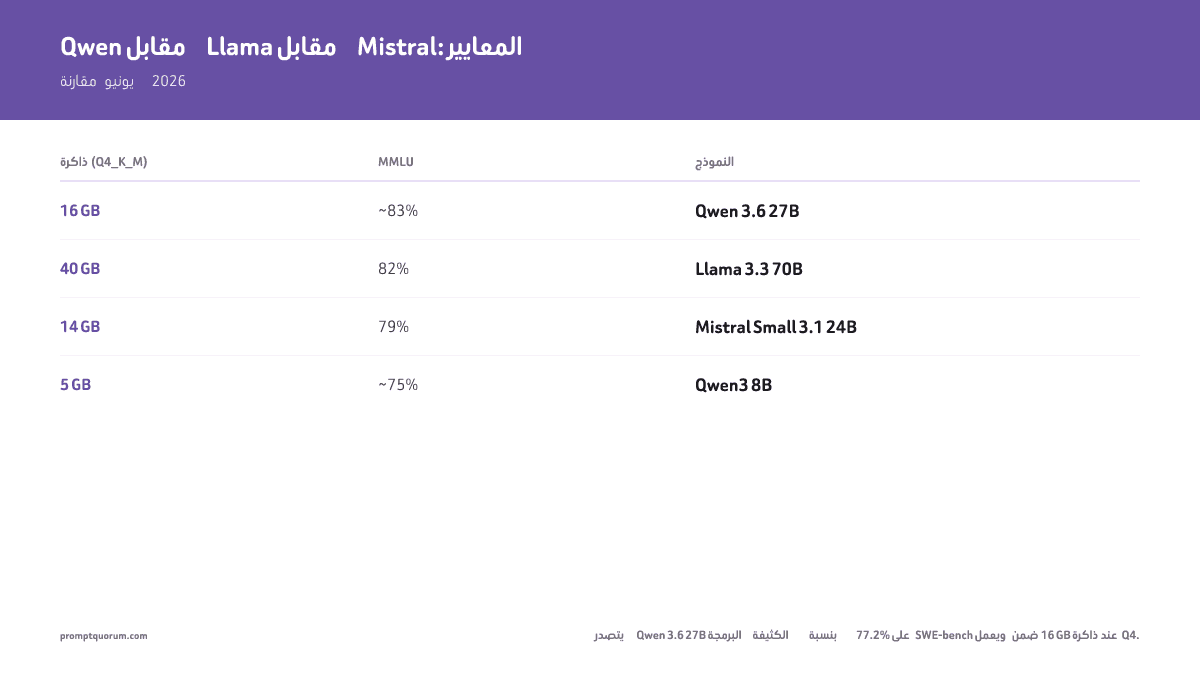
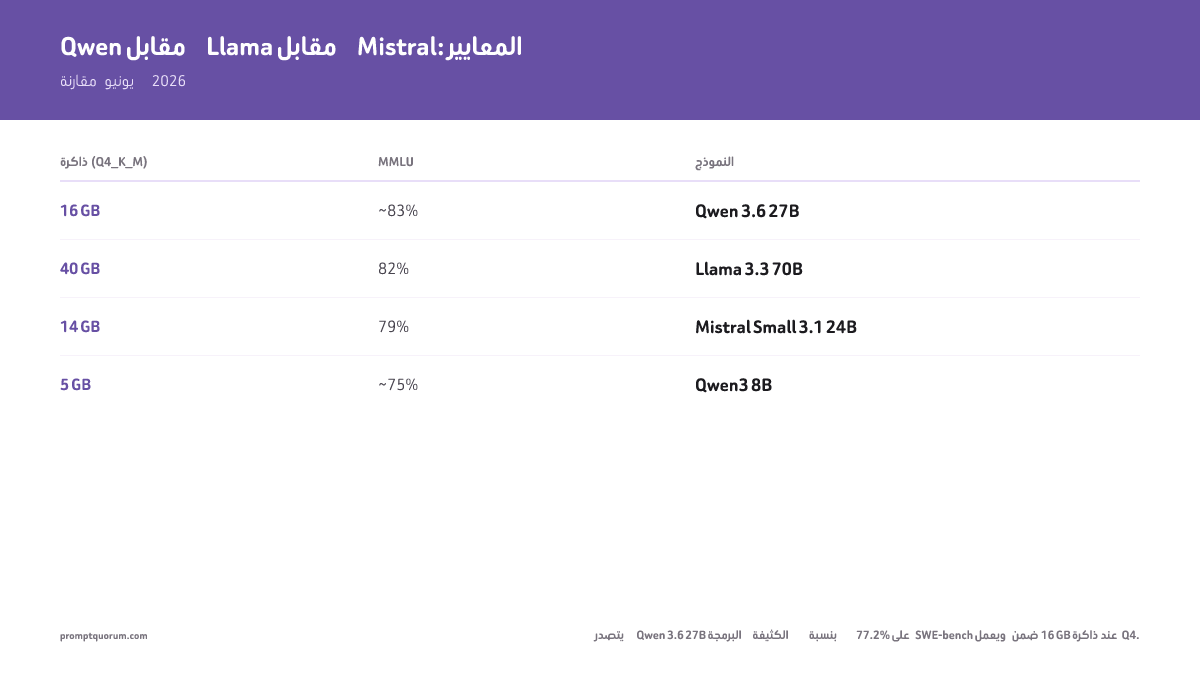
| Modelo | MMLU | SWE-bench | MATH | RAM (Q4_K_M) |
|---|---|---|---|---|
| Qwen 3.6 27B | ~83% | 77.2% | ~80% | 16 GB |
| Qwen3 72B | ~85% | — | ~84% | 43 GB |
| Llama 4 Scout 17B (MoE) | — | — | — | ~55 GB |
| Llama 3.3 70B (قديم) | 82% | — | 77% | 40 GB |
| Mistral Small 3.1 24B | 79% | — | 65% | 14 GB |
| Devstral Small 24B | — | عالٍ (بالوكلاء) | — | 16 GB |
| Qwen3 8B | ~75% | — | ~55% | 5 GB |
| Mistral Small v0.3 | 64% | — | 28% | 4.5 GB |
في أي مهام يتميّز Qwen3 / Qwen 3.6؟
Qwen3 (أبريل 2026) وQwen 3.6 (مايو 2026) من Alibaba يتصدران معايير البرمجة. يحصل Qwen 3.6 27B على 77.2% في SWE-bench — أفضل نموذج برمجة كثيف متاح. ويواصل Qwen3 72B تصدّر MMLU بـ ~85%. يضيف Qwen 3.5 قدرات متعددة الوسائط. تتضمن عائلة Qwen3 نماذج كثيفة ومتغيرات MoE (35B-A3B).
نقاط القوة: البرمجة (Python، JavaScript، SQL، متصدر SWE-bench)، الاستدلال الرياضي (84% MATH عند 72B)، الدعم الأصلي لـ 29 لغة، وضع JSON، استدعاء الدوال، نافذة سياق 128K في جميع الأحجام.
نقاط الضعف: قد يبدو أسلوب اتباع التعليمات بالإنجليزية أقل طبيعية من Llama أو Mistral؛ يفيد بعض المستخدمين بأن الكتابة الإبداعية بالإنجليزية أقل سلاسة. يثير منشأ Alibaba مخاوف معالجة بيانات لبعض مستخدمي المؤسسات، رغم الأوزان المفتوحة.

لماذا Llama 4 Scout هو الخيار للسياق الطويل؟
قدّم Llama 4 (أبريل 2025) بنية MoE إلى عائلة Llama. يقدّم Scout (17B نشط / 109B إجمالي، 16 خبيرًا، متعدد الوسائط) نافذة سياق 10M token — أوسع سياق لأي نموذج قابل للتشغيل محليًا — لكنه يتطلب ~55 GB من VRAM بـ Q4 ولا يتسع في بطاقة رسوم استهلاكية بسعة 24 GB بالتكميمات العادية (إلا بدقة 1.78 بت، ~20 token/ثانية). يستهدف Maverick (17B نشط / 400B إجمالي) إعدادات متعددة بطاقات الرسوم. يبقى Llama 3.3 70B النموذج الكثيف الأكثر اختبارًا في الميدان. لأفضل أداء عام على الأجهزة الاستهلاكية، يتفوق Qwen 3.6 27B (يتسع في 24 GB بـ Q4) على Scout؛ اختر Scout عندما تحتاج إلى سياق 10M أو إدخال متعدد الوسائط.
نقاط القوة: نافذة سياق 10M (Scout)، إدخال متعدد الوسائط، أفضل اتباع تعليمات بالإنجليزية وكتابة إبداعية، أوسع دعم نظام بيئي لأي عائلة مفتوحة المصدر، Llama 3.3 70B لا يزال مضبوطًا جدًا.
نقاط الضعف: طلب VRAM عالٍ (~55 GB بـ Q4) يُخرج Scout عن متناول بطاقة رسوم استهلاكية واحدة بسعة 24 GB بالتكميمات العادية؛ بلا دعم متعدد اللغات أصلي (لا يزال Qwen3 يتصدر اللغات غير الإنجليزية بفارق كبير)؛ معايير Llama 4 Scout لا تزال قيد التطوير. لا يزال Llama 3.3 70B وLlama 3.3 8B متاحين وهما أكثر النماذج الأساسية ضبطًا.
ما أكبر ميزة لـ Mistral؟
تنتج Mistral AI أكثر النماذج كفاءةً في المعاملات في هذه المقارنة وتقدّم الآن متغيرات متخصصة. يقدّم Mistral Small 3.1 عند 24B درجات معايير قريبة من فئة 70B بـ 14 GB فقط من RAM -- أفضل نسبة جودة-RAM. Devstral Small 24B (Mistral AI، 2026) مصمم للبرمجة بالوكلاء — تعديلات عبر ملفات متعددة واستدعاء أدوات وحلقات تصحيح. Codestral 22B هو نموذج Mistral المحسّن لـ FIM للإكمال التلقائي في IDE — النموذج الموصى به لتكاملات Continue.dev وCursor.
نقاط القوة: أفضل نسبة جودة-RAM (Small 3.1)، Devstral للبرمجة بالوكلاء، Codestral لـ IDE/FIM، دعم قوي لاستدعاء الدوال والأدوات، ترخيص Apache 2.0 نظيف في النماذج الرئيسية، منشأ أوروبي (فرنسا) للامتثال لقانون الذكاء الاصطناعي الأوروبي.
نقاط الضعف: Mistral Small v0.3 صار الآن متجاوزًا في المعايير من Qwen3 7B وLlama 3.3 8B؛ خيارات أحجام أقل في الطليعة من Qwen أو Llama (رغم أن التخصص يعوّض هذا جزئيًا).
مقارنة استدعاء الأدوات والاستدلال
يتيح استدعاء الأدوات (استدعاء الدوال) للنموذج استدعاء واجهات API وأدوات خارجية في سير العمل بالوكلاء. اعتبارًا من أبريل 2026، تدعمه العائلات الثلاث أصليًا.
| Modelo | Tool Calling | Razonamiento (MATH) | Mejor para |
|---|---|---|---|
| Qwen3 72B | ✅ أصلي | 83% | وكلاء معقدون متعددو الخطوات |
| Llama 3.3 70B | ✅ أصلي | 77% | سير عمل بالوكلاء بالإنجليزية |
| Mistral Small 3.1 24B | ✅ أصلي، مختبر جيدًا | 65% | استخدام الأدوات في الإنتاج بـ 16 GB |
| Qwen3 14B | ✅ أصلي | 70% | استدعاء أدوات اقتصادي |
| Llama 3.2 3B | ✅ أصلي | 51% | وكلاء خفيفون |
| Mistral Small v0.3 | ⚠️ محدود | 28% | غير موصى به لاستدعاء الأدوات |
للمهام كثيفة الاستدلال (الرياضيات، المنطق، مراجعة الكود): يتفوق DeepSeek-R1 (ترخيص MIT، 7B-32B) على العائلات الثلاث في معايير MATH. فكّر في تضمينه إلى جانب هذه الثلاث لسير العمل التحليلي. (أصدرت DeepSeek منذ ذلك الحين DeepSeek-V4 — Flash/Pro — كجيل جديد بأوزان مفتوحة؛ يظل R1/V3 صالحًا للتشغيل محليًا.)
أي عائلة نماذج تفوز حسب المهمة؟
اختيار النموذج هو الخطوة الأولى؛ وتصميم الأمر هو الخطوة الثانية. قد يُنتج الأمر نفسه نتائج مختلفة جدًا على Qwen وLlama وMistral. للتقنيات المنهجية التي تولّد نتائج متسقة مع أي عائلة نماذج، راجع دليل هندسة الأوامر.
| Tarea | Ganador | Por qué |
|---|---|---|
| برمجة Python / JavaScript (توليد) | Qwen 3.6 | 77.2% SWE-bench — أفضل نموذج برمجة كثيف |
| برمجة بالوكلاء (ملفات متعددة، تصحيح) | Mistral (Devstral) | مصمم لسير العمل بالوكلاء |
| إكمال تلقائي في IDE (FIM) | Mistral (Codestral) | محسّن لـ FIM، دعم Continue.dev/Cursor |
| أسئلة عامة (إنجليزية) | Llama 3.3 / Qwen3 (تعادل) | كلاهما يحصل على 82-85% MMLU عند 70B |
| الاستدلال الرياضي | Qwen3 | 84% MATH عند 72B مقابل 77% لـ Llama 3.3 70B |
| اللغات غير الإنجليزية | Qwen3 | 29 لغة أصلية؛ Llama وMistral أولويتهما الإنجليزية |
| كتابة إبداعية (إنجليزية) | Llama 3.x/4 | أسلوب توليد بالإنجليزية أكثر طبيعية |
| الجودة بـ 16 GB من RAM | Mistral Small 3.1 | جودة قريبة من 70B بـ 14 GB من RAM — بلا تغيير |
| مهام السياق الطويل (10M+ token) | Llama 4 Scout | نافذة سياق 10M token — لا منافس يضاهيها |
| أول نموذج للمبتدئين | Llama 4 3B | الأفضل توثيقًا، أكثر دعم مجتمعي — بلا تغيير |

كيف تقارن النماذج على المقياس نفسه؟
فئة 3B-4B: يتفوق Qwen3 3B وPhi-4 Mini 3.8B على Llama 4 3B في البرمجة والرياضيات. للاستخدام العام بالإنجليزية، Llama 4 3B أكثر موثوقية.
فئة 7B-8B: يتفوق Qwen3 8B (~5 GB) وLlama 3.3 8B (~5.5 GB) بشكل كبير على Mistral Small v0.3. يتصدر Qwen3 8B في البرمجة؛ ويتصدر Llama 3.3 8B في اتباع التعليمات بالإنجليزية.
فئة 14B-24B: Qwen3 14B وMistral Small 3.1 24B هما الخياران الرئيسيان. Mistral Small 3.1 أقوى إجمالًا، رغم أنه يتطلب مزيدًا من RAM. Devstral Small 24B هو الخيار الأفضل للمطورين الذين يقومون بالبرمجة بالوكلاء في هذا المستوى.
فئة MoE (جديدة في 2025-2026): يستخدم Llama 4 Scout (17B نشط / 109B إجمالي، 16 خبيرًا) وQwen3.6-35B-A3B (3B نشط / 35B إجمالي، 73.4 SWE-bench) بنية Mixture-of-Experts — تُفعَّل فقط نسبة من المعاملات لكل token. يتطلب Scout ~55 GB من VRAM بـ Q4 (يتسع في بطاقة رسوم بسعة 24 GB إلا بدقة 1.78 بت، ~20 token/ثانية)، لذا فهو خيار سياق طويل/متعدد الوسائط أكثر من كونه خيار كفاءة VRAM استهلاكية؛ متغيرات MoE الأصغر أكفأ بكثير في VRAM. كما يعمل gpt-oss:20b (21B إجمالي / 3.6B نشط MoE) في 16 GB بمستوى ~o3-mini مع استدلال قابل للضبط.
فئة 70B-72B: Llama 3.3 70B وQwen3 72B هما أفضل النماذج الكثيفة القابلة للتشغيل محليًا في 2026. اختر Qwen3 72B للبرمجة ومتعدد اللغات؛ واختر Llama 3.3 70B للمهام العامة بالإنجليزية.
تغطي Qwen وLlama وMistral مشهد المصدر المفتوح. لمقارنة تشمل البدائل التجارية — GPT-5.5 وClaude Opus 4.8 وGemini 3.5 — ومتى تختار المملوك مقابل المفتوح المصدر، راجع كيفية اختيار نموذج الذكاء الاصطناعي المناسب.

Mistral Small 24B مقابل Qwen 3 14B مقابل Llama 3.3 8B: مرجع المعايير القديمة
لا يزال كثير من المطورين يشغّلون الجيل السابق: Mistral Small 24B (2024) وQwen 3 14B (2024) وLlama 3.3 8B (2024). لا تزال هذه النماذج متاحة في Ollama ومنتشرة على نطاق واسع في الإنتاج. يقارنها هذا القسم مباشرة للفرق التي لم تُرقِّ بعد ويوضح متى يكون من المنطقي الترقية إلى Qwen 3 أو Llama 4 أو Mistral الحالي.
- Mistral Small 24B يقدّم أعلى المعايير المطلقة من الثلاثة، لكنه يتطلب 14 GB من RAM. مثالي للأجهزة بسعة 16 GB أو أكثر حيث تهم الجودة أكثر من الهامش.
- Qwen 3 14B هو أقوى نموذج برمجة في هذا المستوى القديم، بـ 71% في HumanEval باستخدام 8 GB من RAM. مثالي للمطورين بـ 12-16 GB من RAM الذين يُولون الأولوية لتوليد الكود.
- Llama 3.3 8B يملك أوسع دعم نظام بيئي — مزيد من الضبط الدقيق، ومزيد من الدروس، ومزيد من مساعدة المجتمع. مثالي للمستخدمين المبتدئين أو الفرق التي تحتاج إلى موارد مجتمعية واسعة.
- متى تُرقّي Mistral Small 24B ← Mistral Small 3.1 24B: إذا كنت تحتاج إلى برمجة بالوكلاء (استخدم Devstral Small 24B)، أو إكمال تلقائي في IDE (استخدم Codestral 22B)، أو تحسينات جودة تدريجية بنفس بصمة RAM.
- متى تُرقّي Qwen 3 14B ← Qwen 3 14B أو Qwen 3.6 27B: إذا كنت تحتاج إلى أداء في SWE-bench (يحصل Qwen 3.6 27B على 77.2%، أفضل نموذج برمجة كثيف لعام 2026)، أو لديك بالفعل 16 GB من RAM، أو تحتاج إلى دعم أصلي لـ 29 لغة (وسّع Qwen 3 التغطية متعددة اللغات).
- متى تُرقّي Llama 3.3 8B ← Llama 4 Scout: فقط إذا كان لديك ~55 GB+ من VRAM بـ Q4 (يُفعّل MoE من 16 خبيرًا في Scout 17B/109B معامل لكنه يتطلب ~55 GB بـ Q4؛ يتسع في بطاقة رسوم بسعة 24 GB إلا بدقة 1.78 بت، ~20 token/ثانية) وتحتاج إلى سياق 10M token (مقابل 128K لـ Llama 3.3) أو إدخال متعدد الوسائط. على بطاقة رسوم استهلاكية واحدة بسعة 24 GB، Qwen 3.6 27B (يتسع في 24 GB بـ Q4) هو الترقية الأفضل.
- ابقَ على النماذج القديمة إذا: بُني ضبطك الدقيق على Llama 3.3 8B أو Qwen 3 (تكلفة الترحيل تفوق الفائدة)، أو كان الاستقرار في الإنتاج يهم أكثر من المعايير (النماذج القديمة مختبرة في الميدان)، أو لم يتطلب عبء عملك القدرات الجديدة (دردشة عامة، تلخيص، أسئلة وأجوبة أساسية).
- مصفوفة قرار سريعة للمستخدمين القدامى:
- • لديك 8 GB من RAM، تقوم بدردشة عامة: ابقَ على Llama 3.3 8B أو Mistral Small v0.3.
- • لديك 12-16 GB من RAM، تقوم بالبرمجة: رقِّ Qwen 3 14B ← Qwen 3 14B أو Qwen 3.6 27B.
- • لديك 16+ GB من RAM، تريد أفضل جودة: رقِّ Mistral 24B ← Mistral Small 3.1 24B (عام) أو Devstral 24B (برمجة بالوكلاء).
- • لديك 24 GB من VRAM: استخدم Qwen 3.6 27B (يتسع في 24 GB بـ Q4) لأفضل أداء عام على الأجهزة الاستهلاكية. احجز Llama 4 Scout (MoE، سياق 10M، ~55 GB بـ Q4) للفرق متعددة بطاقات الرسوم أو محطات العمل التي تحتاج إلى سياقه الطويل أو إدخاله متعدد الوسائط.
| Modelo | Parámetros | RAM (Q4_K_M) | MMLU | HumanEval | Mejor para |
|---|---|---|---|---|---|
| Mistral Small 24B | 24B كثيف | 14 GB | 79% | 73% | أفضل جودة لكل RAM (مستوى قديم) |
| Qwen 3 14B | 14B كثيف | 8 GB | 73% | 71% | البرمجة على أجهزة متوسطة المواصفات |
| Llama 3.3 8B | 8B كثيف | 5 GB | 68% | 65% | الأكثر توثيقًا، أسهل بداية |
السياق الإقليمي: أي عائلة للاتحاد الأوروبي واليابان والصين؟
الامتثال للاتحاد الأوروبي وGDPR: العائلات الثلاث (Qwen3، Llama 3.x/4، Mistral) تعمل بالكامل محليًا دون نقل بيانات خارجي، مما يضمن الامتثال لـ GDPR. لـ Mistral (فرنسية المنشأ، Mistral AI) أقوى موقف امتثال للاتحاد الأوروبي. Devstral Small 24B وCodestral 22B فرنسيان المنشأ (Mistral AI)، Apache 2.0 — أقوى نماذج برمجة أوروبية المنشأ متاحة. كلٌّ من Qwen3 (Apache 2.0) وLlama 3.x/4 يعملان جيدًا تحت متطلبات الشفافية لقانون الذكاء الاصطناعي الأوروبي وقابلية تدقيق المصدر المفتوح. يدعم Qwen3 أصليًا الألمانية والفرنسية ولغات الاتحاد الأوروبي الأخرى دون تدهور جودة. يؤثر الموعد النهائي لقانون الذكاء الاصطناعي الأوروبي في أغسطس 2026 في تصنيف هذه المستويات من النماذج.
اليابان والامتثال لـ METI: يتماشى Qwen3 وLlama 3.x/4 مع إرشادات حوكمة الذكاء الاصطناعي المحلية لوزارة الاقتصاد والتجارة والصناعة (METI) في اليابان. لا تُطلب تقارير خاصة عند النشر على بنية تحتية خاصة داخل شبكات الشركات اليابانية. يستفيد Qwen3 من دعم قوي للغة اليابانية (تجزئة أصلية) ضمن لغاته الـ 29، مما يجعله مفضّلًا لأعباء العمل باليابانية. تمتثل Mistral أيضًا، لكنها أقل توثيقًا في سياقات حوكمة الذكاء الاصطناعي اليابانية. كفاءة MoE في Llama 4 Scout جذّابة للشركات اليابانية ذات الأجهزة المحدودة.
الصين ومتطلبات CAC: يُفضَّل Qwen3 (Alibaba، محلي) على نطاق واسع للامتثال لـ CAC (إدارة الفضاء السيبراني في الصين). Qwen3 محسّن أصليًا لتجزئة الصينية دون تدهور في لغاته الـ 29 — ميزة حاسمة لدعم الماندارين واللهجات. كما يتوفر Kimi K2.6 (Moonshot AI، 1T إجمالي / 32B نشط MoE، ترخيص MIT معدّل) للبرمجة المؤسسية في الصين — أداء طليعي (58.6 SWE-Bench Pro)، ترخيص MIT معدّل. Llama وMistral مقبولان عند النشر على خوادم خاصة داخل الأراضي الصينية، لكن استدعاءات API السحابية تحمل تدقيق CAC أعلى ومتطلبات إقامة بيانات. للامتثال في الإشراف على المحتوى، يضمن إرث تدريب Qwen3 بالصينية المحاذاة مع سياسات المحتوى المحلية.
الأخطاء الشائعة عند اختيار عائلات النماذج
- مقارنة نماذج بأعداد معاملات مختلفة -- Qwen 32B مقابل Llama 70B ليست مقارنة ندٍّ لندٍّ.
- سوء فهم VRAM لـ MoE. لـ Llama 4 Scout 109B معامل إجمالي لكن 17B فقط نشط لكل token — ومع ذلك، بـ Q4 يتطلب ~55 GB من VRAM (يجب أن يقيم كل الخبراء في الذاكرة)، لا ~14 GB التي يستخدمها نموذج كثيف بحجم 17B. لا يتسع في بطاقة رسوم استهلاكية بسعة 24 GB بالتكميمات العادية (إلا بدقة 1.78 بت، ~20 token/ثانية). قارن حسب بصمة VRAM الفعلية والمعيار، لا حسب عدد المعاملات النشطة.
- استخدام Qwen3 عندما يتوفر Qwen3. يحسّن Qwen3 8B على Qwen3 7B في معايير البرمجة. ما لم يكن لديك ضبط دقيق محدد مبني على Qwen3، رقِّ إلى Qwen3.
- عدم مراعاة نماذج Mistral المتخصصة. لـ Mistral الآن ثلاثة خطوط نماذج متمايزة: Small 3.1 (عام)، Devstral (برمجة بالوكلاء)، Codestral (إكمال تلقائي في IDE). اختيار "Mistral" دون تحديد أي نموذج لأي مهمة يهدر الميزة الرئيسية للعائلة — التخصص.
- تجاهل المعايير متعددة اللغات عند الاختيار بين النماذج إذا كان عبء عملك متعدد اللغات.
- تجاهل Mistral Small 3.1: يتخطّى كثير من المستخدمين Small 3.1 (24B) ظنًّا أنه يتطلب 30+ GB من RAM. يتسع بتكميم Q5 بـ 22 GB، متفوقًا على Llama 3.3 8B في كثير من المهام.
الأسئلة الشائعة
هل Qwen أم Llama أفضل لحالة استخدامي؟
الأفضل إجمالًا على الأجهزة الاستهلاكية: Qwen 3.6 27B (77.2% SWE-bench، يتسع في 24 GB بـ Q4). للبرمجة والمهام متعددة اللغات: Qwen 3.6 27B أو Qwen3 8B. للسياق الطويل (10M token) أو الإدخال متعدد الوسائط: Llama 4 Scout (يتطلب ~55 GB من VRAM بـ Q4). لأقصى جودة لكل GB من RAM: Mistral Small 3.1. اختبر بأوامر عينة من عبء عملك الفعلي.
ما هو Llama 4 Scout وبماذا يختلف عن Llama 3.3؟
يستخدم Llama 4 Scout بنية Mixture-of-Experts (MoE) من 16 خبيرًا — 17B معامل نشط لكل token من إجمالي 109B، وهو متعدد الوسائط. يجب أن يقيم كل الخبراء في الذاكرة، لذا بـ Q4 يتطلب ~55 GB من VRAM (لا ~14 GB لنموذج كثيف بحجم 17B) ولا يتسع في بطاقة رسوم استهلاكية بسعة 24 GB بالتكميمات العادية — إلا بدقة 1.78 بت (~20 token/ثانية). جاذبيته هي نافذة سياق 10M token — الأوسع لأي نموذج قابل للتشغيل محليًا. Llama 3.3 70B نموذج كثيف يتطلب 40 GB من VRAM. على بطاقة رسوم واحدة بسعة 24 GB، Qwen 3.6 27B هو الخيار العام الأفضل؛ اختر Scout للسياق الطويل أو متعدد الوسائط إذا كان لديك VRAM.
هل أستخدم Qwen3 أم Qwen3؟
استخدم Qwen3 للمشاريع الجديدة. يحسّن Qwen3 8B على Qwen3 7B في معايير البرمجة والاستدلال. Qwen 3.6 27B (77.2% SWE-bench) هو أفضل نموذج برمجة كثيف متاح. السبب الوحيد للبقاء على Qwen3 هو إذا كان لديك ضبط دقيق أو سير عمل قائم يعتمد على سلوكه المحدد. للتثبيتات الجديدة، ابدأ دائمًا بـ Qwen3.
كم Mistral أسرع على الأجهزة الاستهلاكية؟
يعمل Mistral Small 3.1 (24B) أسرع بـ 1.5-2× من Llama 3.3 8B على نفس الجهاز. لأعباء العمل الحساسة للأداء، Mistral Small هو الأسرع بـ 40-60 token/ثانية على بطاقة رسوم واحدة. Codestral 22B محسّن لـ FIM (الملء في الوسط) في سير عمل الإكمال التلقائي في IDE.
هل يمكن للثلاثة العمل بـ 8 GB من VRAM؟
نعم، يمكنها جميعًا تشغيل نماذج 7B بتكميم Q4 بـ 8 GB. يستخدم Qwen3 8B ~5 GB، وLlama 3.3 8B ~5.5 GB، وMistral Small ~4.5 GB بـ Q4_K_M. Llama 4 Scout (MoE) لا يتسع في 8 GB — يتطلب ~55 GB من VRAM بـ Q4.
هل أحتاج إلى RTX 5090 لتشغيلها؟
لا، ليس للخيارات الاستهلاكية. تشغّل RTX 5070 (12 GB) نماذج 7B بأريحية. بطاقة رسوم بسعة 24 GB تشغّل Qwen 3.6 27B بـ Q4 (الأفضل إجمالًا على الأجهزة الاستهلاكية). يتطلب Llama 4 Scout ~55 GB بـ Q4 — فريق متعدد بطاقات الرسوم أو محطة عمل، لا بطاقة استهلاكية واحدة. RTX 5090 مبالغة ما لم تشغّل نماذج كثيفة بحجم 70B+.
أي تكميم ينبغي أن أستخدم؟
ابدأ بـ Q4_K_M (4 بت) -- توازن جيد بين الجودة والسرعة عبر جميع الأجهزة. استخدم Q5_K_M إذا كان لديك هامش VRAM وتحتاج إلى جودة أعلى. Q3_K_S للأجهزة محدودة الموارد.
أيها أفضل للبرمجة؟
Qwen3 8B (~76% HumanEval) لمستوى 8 GB. Qwen 3.6 27B (77.2% SWE-bench) لأفضل برمجة كثيفة. Devstral Small 24B لسير العمل بالوكلاء عبر ملفات متعددة. Codestral 22B للإكمال التلقائي في IDE (FIM).
المصادر
- Qwen Team. (2026). Qwen3 Technical Report. -- معايير عائلة Qwen3، SWE-bench لـ Qwen 3.6 27B (77.2%)، متغيرات MoE.
- Meta AI. (2025). Llama 4 Model Card. -- المعيار الرسمي وبنية Llama 4 Scout/Maverick MoE، نافذة سياق 10M.
- Mistral AI. (2026). Devstral Small 24B. -- بنية ومعايير نموذج البرمجة بالوكلاء.
- Mistral AI. (2025). Codestral. -- نموذج البرمجة المحسّن لـ FIM للإكمال التلقائي في IDE.
- Meta AI. (2024). Llama 3.3 Model Card. -- بيانات المعايير الرسمية لـ Llama 3.3 70B (قديم، لا يزال مستخدمًا كثيرًا).
سجل التحديثات
- 2026-05-17: أُضيف قسم "مرجع المعايير القديمة" يقارن Mistral Small 24B وQwen 3 14B وLlama 3.3 8B. حُدّث العنوان لربط عمليات البحث عن النماذج القديمة والحالية.