Key Takeaways
- Regra prática 7B em Q4: um modelo 7B em quantização Q4_K_M precisa de cerca de 4-5 GB de VRAM (ou RAM do sistema para inferência por CPU) — aproximadamente 0,6 GB por bilhão de parâmetros em 4 bits. É a forma mais rápida de estimar a memória de qualquer modelo classe 7B sem fazer o cálculo completo de VRAM abaixo.
- Cálculo de VRAM: (Tamanho do modelo em GB) ÷ Quantização = VRAM necessária. Exemplo: 70B em Q4 = 70 ÷ 8 = 8,75 GB × parâmetros ≈ 39 GB no total.
- 12 GB de VRAM (RTX 4070 Ti): Melhor modelo: Llama 3.1 8B Q8 (~9 GB, 80 tok/sec). Também: Qwen3 8B (~8 GB, melhor em multilíngue + codificação). Nota: o Llama 4 Scout (17B ativos / 109B total MoE) precisa de ~55 GB em Q4 e NÃO cabe em 12 GB.
- 16 GB de VRAM (RTX 5080 / RTX 5070 Ti): Melhor modelo: Mistral Small 3.1 24B Q4_K_M (~13 GB, 55 tok/sec). Também: Devstral Small 24B Q4_K_M para codificação agêntica. O Mistral Small 4 (março de 2026) é o sucessor mais novo de modelo único que integra raciocínio, visão e codificação.
- 24 GB de VRAM (RTX 4090 / RTX 5090): A maioria dos modelos 70B em Q4_K_M (~40 GB) NÃO cabe. Melhor opção: Qwen3.6 27B Q4_K_M (~16 GB, 77,2% SWE-bench, melhor codificador denso) ou DeepSeek-R1 32B Q4_K_M (~19 GB, 60 tok/sec).
- Apenas CPU (16 GB de RAM do sistema): Llama 3.2 3B Q8 (20 tok/sec) ou Phi-4 Mini Q4_K_M (25 tok/sec). Uma RTX 4060 8 GB usada (~$250) ou uma RTX 5060 Ti 16 GB nova (~$394) é 5-10× mais rápida.
- MacBook com 8 GB de RAM: rode apenas modelos 3-4B — Phi-4 Mini, Llama 3.2 3B ou Gemma 3 4B em Q4_K_M via llama.cpp/Ollama (Metal). 7B fica no limite com 8 GB; 16 GB é o mínimo confortável no Mac.
- Apple M5 Max (128 GB unificada): roda modelos 70B em Q4_K_M confortavelmente (~12-15 tok/sec) em um laptop ou Mac Studio — junto com o Mac Studio e os sistemas AMD Strix Halo de 128 GB que também comportam um modelo 70B. Nenhum deles comporta o GLM-5.2 (precisa de ~239 GB mesmo em 2 bits).
- Preços de julho de 2026: a escassez de GDDR7 piorou, não melhorou — o preço de rua da RTX 5090 subiu de ~$4.000 em junho para $4.300–$5.000+ em meados de julho, e a RTX 4090 continua descontinuada. Compradores com orçamento apertado também devem considerar a RX 9070 XT da AMD (16 GB GDDR6, ~$630–700) — a GDDR6 escapou da maior parte da escassez, tornando-a visivelmente mais barata que a RTX 5070 Ti com VRAM similar. Compre de anúncios em estoque; verifique os preços ao vivo antes da compra.
- Dica de velocidade do llama.cpp: Sempre defina `--n-gpu-layers 99`. Só isso já dobra a velocidade na RTX 4070 Ti, de ~40 para ~85 tok/sec.
- Referência rápida: 7B@Q4_K_M = 4-5 GB | 70B@Q4_K_M = 40 GB | GLM-5.2@2-bit = ~239 GB | RTX 4070 Ti = ~80 tok/s | RTX 4090 = ~150 tok/s | Apenas CPU 16 GB = 12-28 tok/s
O hardware para LLMs locais é determinado pela VRAM: modelos 7B precisam de 8 GB, 13–14B precisam de 12–16 GB, e modelos 70B precisam de 35–48 GB — uma RTX 4060 8 GB usada (~US$250) é a melhor GPU de entrada em 2026.
VRAM é a memória dedicada da sua placa de vídeo. Quanto maior o modelo de IA, mais VRAM ele precisa. Regra geral: divida o tamanho do modelo em gigabytes pelo nível de compressão (Q4 = dividir por 8) para estimar a VRAM necessária.
Requisitos de Hardware para LLM Local 2026
O hardware mínimo para rodar um LLM local em 2026 é uma GPU com 8 GB de VRAM — ou um Mac com Apple Silicon e 16 GB de memória unificada — para modelos da classe 7B. Os requisitos então escalam com o tamanho do modelo: 14B precisa de 12 GB, 24B precisa de 16 GB, 32B precisa de 24 GB, e um modelo 70B precisa de ~40 GB em Q4_K_M. A VRAM da GPU é o limite rígido: ela decide quais modelos carregam, de fato. A CPU e a RAM do sistema afetam o tempo de carregamento e a velocidade de fallback apenas em CPU, mas não qual modelo cabe na GPU.
Use esta tabela como a resposta direta para "que hardware eu preciso" — encontre o tamanho do seu modelo ou a faixa de VRAM, depois pule para as escolhas de modelo por faixa abaixo.
| Tamanho do modelo | VRAM em Q4_K_M | Exemplo de GPU (2026) | Melhor modelo | Velocidade |
|---|---|---|---|---|
| 3-4B | 4-5 GB | Qualquer 8 GB / Mac 8 GB | Phi-4 Mini, Gemma 3 4B | 60-90 tok/s |
| 7-8B | 5-9 GB | RTX 5060 Ti, RTX 4060 (8 GB) | Llama 3.1 8B, Qwen3 8B | 50-80 tok/s |
| 14B | ~9 GB | RTX 5070 (12 GB) | Qwen3 14B | ~80 tok/s |
| 24B | ~14 GB | RTX 5070 Ti / 5080 (16 GB) | Mistral Small 3.1 24B | ~55 tok/s |
| 27-32B | 16-19 GB | RTX 4090 / 5090 (24-32 GB) | Qwen3.6 27B, DeepSeek-R1 32B | 55-60 tok/s |
| 70B | ~40 GB | RTX 5090 dupla, A100, Mac M5 Max 128 GB | Llama 3.3 70B | 10-60 tok/s |
•KeyPoint: Em uma frase: combine o modelo com a sua VRAM — 8 GB roda 7B, 12 GB roda 14B, 16 GB roda 24B, 24 GB roda 32B, e somente 40 GB+ roda um modelo 70B com qualidade Q4_K_M utilizável.
•ProTip: Adicione folga para o cache KV (contexto da conversa): reserve 25% além dos pesos do modelo para contexto de 8K e até 100% para 32K. Veja a seção de cache KV abaixo.
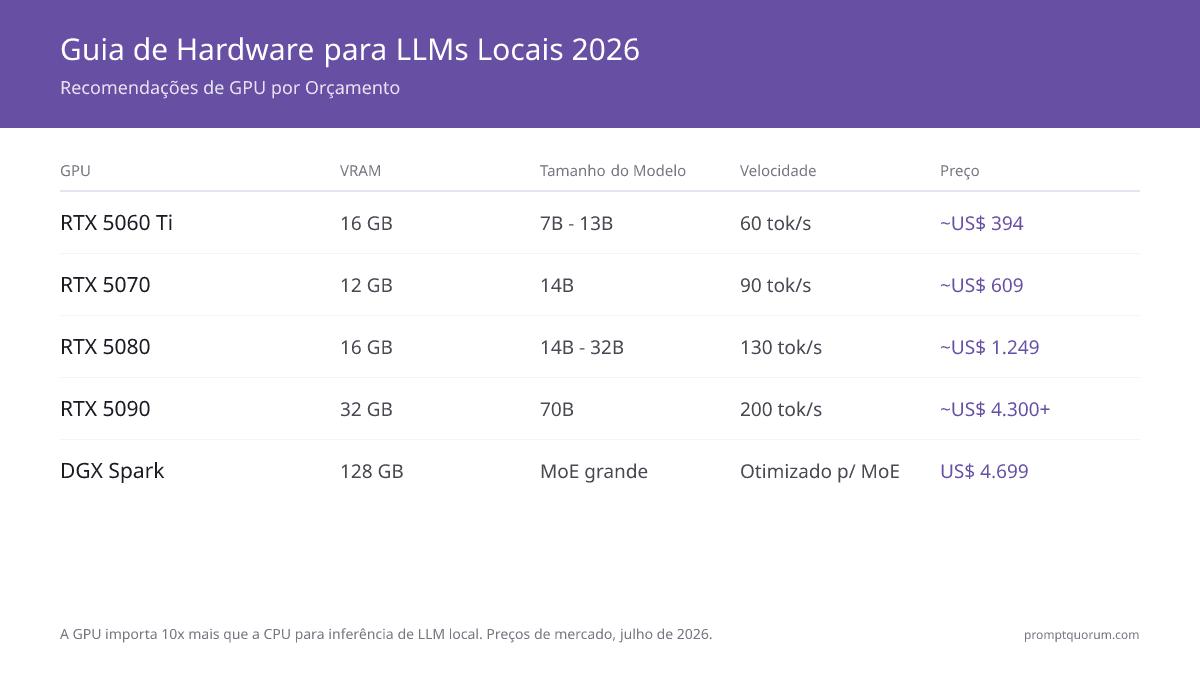
Melhores GPUs para Comprar — Recomendações 2026
A escolha disponível em estoque para LLMs locais em julho de 2026 é a NVIDIA RTX série 50 (Blackwell): 5060 Ti, 5070, 5070 Ti, 5080, 5090. A RTX série 40 (4060, 4070 Ti, 4090) foi descontinuada e agora é vendida escassa e acima dos seus preços antigos no mercado usado. Uma escassez de GDDR7/memória em 2026 continuou piorando ao longo de julho, empurrando até mesmo as placas da série 50 ainda mais acima do MSRP, então trate cada valor abaixo como um preço de rua típico de meados de julho de 2026 e verifique os anúncios ao vivo antes de comprar. Recomendações por caso de uso:
- Para Modelos 7B (Mistral, Phi-4, Llama 3.1) — Econômica: RTX 5060 Ti 16 GB (~$394, próximo ao MSRP) ou uma RTX 4060 8 GB usada (~$250). Roda qualquer modelo 7B em Q4_K_M (~4-5 GB). Velocidade: 50–70 tok/sec. Faixa: Entusiastas econômicos.
- Para Modelos 14B (Qwen3 14B, DeepSeek-R1) — Mainstream: RTX 5070 (12 GB, ~$609). Melhor placa nova em custo-benefício. O Qwen3 14B Q4_K_M roda bem com folga. Velocidade: 85–110 tok/sec. Faixa: Mais popular.
- Para Modelos 24-32B (Qwen3.6, Mistral Small) — Intermediária: RTX 5070 Ti (16 GB, ~$979) ou RTX 5080 (16 GB, ~$1,249). Roda Mistral Small 3.1 24B e Devstral Small 24B Q4_K_M. Velocidade: 110–150 tok/sec. Faixa: Desenvolvedores profissionais. Alternativa econômica: AMD RX 9070 XT (16 GB GDDR6, ~$630–700) — a GDDR6 escapou em grande parte da escassez, então agora ela custa $150–250 a menos que a RTX 5070 Ti com VRAM similar, embora o ROCm tenha suporte de ferramentas para LLM local mais limitado que o CUDA.
- Para Modelos 70B (Llama 3.3) — Topo de Linha: RTX 5090 (32 GB, ~$2,000 MSRP mas ~$4,300–5,000+ de rua e ainda subindo) comporta 70B em Q4_K_M com leve offload de CPU. Uma RTX 4090 usada (24 GB, ~$2,300) roda 70B apenas em Q2_K. Para Q4_K_M completo, use RTX 5090 dupla. Velocidade: ~200 tok/sec (5090, modelos menores). Faixa: Pesquisa + produção.
- Para GLM-5.2 (744B MoE, 40B ativos) — Extrema: nenhuma GPU de consumo única é suficiente. O GGUF dinâmico de 2 bits ainda precisa de ~239 GB combinados de VRAM/RAM. Caminhos locais realistas: uma configuração com 4× RTX 3090/4090 e 192 GB+ de RAM do sistema, ou um Mac Studio de 256 GB+, ambos a cerca de 3–9 tok/sec via offload híbrido CPU/GPU.
- Melhor Custo-Benefício 2026: uma única RTX 5070 Ti ou 5080 (16 GB) é o ponto ideal — roda tudo até 32B em Q4_K_M sem a especulação de preço da série 50 sobre a 5090.
- Para Usuários Apple: o Mac M5 Max (128 GB de memória unificada, ~$6,000) roda 70B em Q4_K_M a ~12-15 tok/sec — mais lento que um desktop com múltiplas GPUs, mas silencioso, eficiente em energia e portátil.
| GPU | Melhor Para | Preço | Velocidade | Faixa |
|---|---|---|---|---|
| RTX 5060 Ti (16 GB) | modelos 7-13B | ~$394 | 50–70 tok/s | Econômica |
| RTX 5070 (12 GB) | modelos 14B | ~$609 | 85–110 tok/s | Mainstream |
| RX 9070 XT (16 GB) | modelos 24-32B | ~$630–700 | 90–130 tok/s | Alternativa econômica |
| RTX 5070 Ti / 5080 (16 GB) | modelos 24-32B | ~$979–1,249 | 110–150 tok/s | Profissional |
| RTX 4090 (24 GB, usada) | 32B, 70B (Q2) | ~$2,300 | 150–180 tok/s | Fim de vida / usada |
| RTX 5090 (32 GB) | 70B (Q4, leve offload) | ~$2,000 MSRP (~$4,300–5,000+ de rua) | ~200 tok/s | Topo de linha |
| RTX 5090 dupla | 70B (Q4) completo | ~$8,600–10,000 | 300+ tok/s | Empresarial |
| Mac M5 Max 128GB | 70B (Q4) | ~$6,000 | ~12–15 tok/s (70B) | Laptop pro |
| 4× RTX 3090/4090 + 192GB RAM | GLM-5.2 (2-bit) | ~$6,000–9,000 | 3–9 tok/s | MoE extrema |
⚠️Warning: Os preços de julho de 2026 são voláteis e continuam piorando. A escassez de GDDR7 empurrou a RTX 5090 de cerca de $4.000 de rua em junho para $4.300–$5.000+ em meados de julho — mais que o dobro do seu MSRP de $1,999 — e a descontinuada RTX 4090 agora custa mais usada do que custava nova. Os preços acima são valores de rua típicos — sempre verifique os anúncios atuais antes de comprar. A RX 9070 XT da AMD, baseada em GDDR6, é uma exceção notável: ela escapou em grande parte do salto de preços.
Como Você Calcula os Requisitos de VRAM?
Os requisitos de VRAM dependem de três fatores: tamanho do modelo (parâmetros), quantização (bits por peso) e modo de inferência. Use esta fórmula para determinar se a sua GPU tem memória suficiente. Para uma calculadora interativa, veja a calculadora de VRAM para LLMs locais.
Fórmula:
```text VRAM (GB) = (Tamanho do Modelo × Bits de Quantização) ÷ 8 ```
Valores de quantização: FP16 = 16 bits, Q8_0 = 8 bits, Q5_K_M = 5 bits, Q4_K_M = 4 bits. O ponto ideal prático é o Q4_K_M -- ele usa pesos de 4 bits com K-quantização, que as GPUs NVIDIA aceleram de forma mais eficiente que o formato Q4_0 mais antigo.
| Modelo | FP16 | Q8_0 | Q5_K_M | Q4_K_M |
|---|---|---|---|---|
| Llama 4 Scout (109B total MoE) | ~218 GB | ~109 GB | ~68 GB | ~55 GB |
| Llama 3.1 8B | 16 GB | 8.5 GB | 5.7 GB | 4.7 GB |
| Qwen 3.6 27B | ~54 GB | ~28 GB | ~19 GB | ~16 GB |
| Qwen3 8B | ~16 GB | ~8.5 GB | ~5.7 GB | ~5 GB |
| Llama 3.3 70B | 140 GB | 70 GB | 48 GB | 40 GB |
| Qwen3 32B | 64 GB | 33 GB | 22 GB | 19 GB |
| Mistral Small 3.1 24B | 48 GB | 25 GB | 17 GB | 14 GB |
| Phi-4 Mini 3.8B | 7.6 GB | 4.1 GB | 2.7 GB | 2.3 GB |
O Q4_K_M é o padrão recomendado para hardware de consumo -- 90-95% da qualidade do FP16 a 25-30% do custo de VRAM. O Llama 4 Scout usa arquitetura MoE com 17B de parâmetros ativos de 109B no total. Todos os 109B experts precisam ser carregados na memória, então o Scout precisa de ~55 GB em Q4 (cabe em 24 GB apenas com 1,78 bit). A MoE reduz a computação por token, não o consumo de VRAM.

•KeyPoint: Em uma frase: a VRAM é o pool de memória dedicado da GPU -- o único número que determina quais modelos de IA você pode rodar localmente e com qual qualidade.
Cache KV: O Custo Oculto de VRAM
A fórmula de VRAM (Tamanho do Modelo × Bits ÷ 8) cobre apenas os pesos do modelo -- o cache KV adiciona uma VRAM significativa que a maioria dos guias ignora.
O cache KV armazena o estado de atenção para cada token na sua janela de contexto. Ele cresce linearmente com o comprimento do contexto e permanece na VRAM durante toda a sessão.
Fórmula de VRAM do cache KV: `cache KV ≈ camadas × cabeças × head_dim × 2 × comprimento_do_contexto × 2 bytes`
| Modelo | contexto 4K | contexto 32K | contexto 128K |
|---|---|---|---|
| Llama 3.1 8B | 0.5 GB | 4 GB | 16 GB |
| Llama 3.3 70B | 2 GB | 16 GB | 64 GB |
| Qwen3 32B | 1 GB | 8 GB | 32 GB |
•KeyPoint: Em uma frase: o cache KV é VRAM temporária usada para armazenar o contexto da conversa -- ele cresce a cada token que você gera e é separado do armazenamento dos pesos do modelo.
⚠️Warning: Um Llama 3.1 8B em Q4_K_M precisa de 4,7 GB para os pesos -- mas adicione uma janela de contexto de 32K e a VRAM total sobe para ~8,7 GB. Em uma placa de 8 GB, isso causa erros de OOM.
•KeyPoint: Regra geral: Adicione 25% ao tamanho dos pesos do modelo para um contexto típico de 8K, 100% para contexto de 32K. O contexto padrão do Ollama é 2.048 tokens. Para definir um valor maior: PARAMETER num_ctx 32768 no seu Modelfile.
Qual Faixa de GPU Combina com a Sua Carga de Trabalho?
Em julho de 2026, as GPUs NVIDIA entregam o maior número de tokens/sec para inferência de LLM local em todas as faixas de preço. As seções abaixo de cada faixa trazem recomendações de modelos específicos. Para uma comparação detalhada de benchmarks, veja o guia das melhores GPUs para LLM local.
| Faixa | GPU | VRAM | Melhor Para | Velocidade |
|---|---|---|---|---|
| Econômica (~$394) | RTX 5060 Ti | 16 GB | modelos 7-13B | ~60 tok/s |
| Mainstream (~$609) | RTX 5070 | 12 GB | modelos 7-14B | ~90 tok/s |
| Intermediária (~$979) | RTX 5070 Ti | 16 GB | modelos 14-32B | ~110 tok/s |
| Alta (~$1,249) | RTX 5080 | 16 GB | modelos 14-32B | ~130 tok/s |
| Topo (~$4,300–5,000+ de rua) | RTX 5090 | 32 GB | 70B (Q4, leve offload) | ~200 tok/s |
| Servidor ($7,000+) | RTX 6000 Ada / A100 | 48-80 GB | Multiusuário, 70B+ | Produção |
| IA de Desktop ($4,699) | NVIDIA DGX Spark | 128 GB | Grandes modelos MoE (não o GLM-5.2) | ~3 tok/s (70B denso) |

•KeyPoint: Em julho de 2026, a RTX série 50 (Blackwell) é a geração atual e as únicas placas de consumo NVIDIA ainda em produção — a RTX série 40 foi descontinuada. A RTX 5090 (32 GB) é a placa a comprar para trabalho com 70B, embora a escassez de memória, que continua piorando, mantenha os preços de rua bem mais que o dobro do seu MSRP de $1,999.
Melhores LLMs Locais por Faixa de VRAM (julho de 2026)
Use isto como uma consulta rápida pela faixa de VRAM da sua GPU:
Todos os modelos listados abaixo são de pesos abertos — baixáveis, ajustáveis (fine-tuning) e gratuitos para rodar localmente. Se você está escolhendo entre pesos abertos e APIs proprietárias, veja nossa comparação de LLMs open-source vs proprietários para os trade-offs de custo e desempenho em diferentes volumes de tokens.
O hardware determina quais modelos você pode rodar; a engenharia de prompt determina o quão bem eles se saem. Um prompt bem estruturado em um modelo 7B muitas vezes supera um prompt preguiçoso em um modelo 70B. Veja o guia completo de engenharia de prompt para técnicas que maximizam a qualidade da saída em qualquer contagem de parâmetros.
- 8 GB de VRAM (RTX 5060 Ti, RTX 4060, Intel B580): Llama 3.1 8B Q4_K_M (4,7 GB, ~70 tok/s) -- recomendado. Qwen3 8B (5 GB, melhor em multilíngue + codificação). Phi-4 Mini 3.8B (2,3 GB, mais rápido). Gemma 3 4B (~3 GB, modelo pequeno atual do Google, multimodal). Evite modelos 13B+.
- 12 GB de VRAM (RTX 4070 Ti, RTX 5070, Intel B770): Llama 3.1 8B (4,7 GB, rápido com folga). Qwen3 14B Q4_K_M (8,5 GB, melhor raciocínio com orçamento limitado). Qwen3 8B (5 GB, melhor em multilíngue + codificação). DeepSeek-R1 8B (5 GB, melhor raciocínio). Evite modelos 30B+ e MoE como o Llama 4 Scout (~55 GB em Q4).
- 16 GB de VRAM (RTX 4080, RTX 5070 Ti, RTX 5080): Mistral Small 3.1 24B Q4_K_M (14 GB, melhor qualidade na faixa). Devstral Small 24B Q4_K_M (~16 GB) para codificação agêntica. Qwen3 14B (9 GB, rápido com folga de contexto). Llama 3.3 70B em Q2_K (17 GB, possível mas com qualidade degradada).
- 24 GB de VRAM (RTX 5090, RTX 4090, Tesla L40): Qwen 3.6 27B Q4_K_M (~16 GB, 77,2% SWE-bench, melhor modelo de codificação denso). DeepSeek-R1 32B Q4_K_M (~19 GB, melhor raciocínio). Qwen3 32B Q5_K_M (~21 GB). O Llama 3.3 70B precisa de 2× GPUs de 24 GB em Q4_K_M.
- 32 GB de VRAM (RTX 5090): Llama 3.3 70B Q4_K_M (40 GB -- precisa de offload mínimo de CPU para as últimas camadas). Qwen3 32B (19 GB, cabe inteiro com 13 GB sobrando). Para codificação agêntica, a linha Kimi K2 (MoE, 1T total / 32B ativos, MIT Modificada) é a escolha pesada -- o Kimi K2.7 Code (junho de 2026) é o mais recente, com o K2.6 sendo o lançamento geral anterior; ambos precisam de quantização e offload pesado nesta faixa. A RTX 5090 é a primeira GPU de consumo única que comporta um 70B denso com offload mínimo.
- 48+ GB de VRAM (RTX 6000 Ada, A100, DGX Spark): Llama 3.3 70B Q4_K_M (40 GB, cabe inteiro). Llama 4 Scout (17B ativos / 109B total MoE, ~55 GB em Q4 -- melhor escolha de contexto longo de 10M tokens / multimodal). Llama 4 Maverick (17B ativos, 400B total, MoE). Llama 3.3 70B Q8_0 (70 GB -- precisa de A100 de 80 GB). A NVIDIA DGX Spark (128 GB unificada) comporta todo modelo de pesos abertos até e incluindo 70B em Q8_0 com 58 GB de sobra -- mas não os modelos MoE de fronteira mais novos: o GLM-5.2 (744B no total, 40B ativos) precisa de ~239 GB mesmo em quantização agressiva de 2 bits, bem além da DGX Spark ou de um único Mac Studio de 128 GB.
Calculadora Interativa de VRAM
Use esta calculadora para calcular os requisitos exatos de VRAM para qualquer combinação de modelo, quantização, contexto e tamanho de lote. Selecione sua configuração e veja quais GPUs são compatíveis.
Popular Models
Base Model
6.50 GB
Context OH
1.50 GB
Batch OH
0.00 GB
System OH
1.00 GB
Total Minimum
9.00 GB
Recommended (with 25% safety margin)
11.25 GB
👉 Look for a GPU with at least 11.25 GB VRAM
Compatible GPUs
RTX 3060 (12 GB)
0.8 GB headroom
RTX 4070 (12 GB)
0.8 GB headroom
RTX 4070 Ti (12 GB)
0.8 GB headroom
RTX 4080 (16 GB)
4.8 GB headroom
RTX 4090 (24 GB)
12.8 GB headroom
Mac mini M5 (16 GB) (16 GB)
4.8 GB headroom
Mac mini M4 (16 GB) (16 GB)
4.8 GB headroom
MacBook Pro (24 GB) (24 GB)
12.8 GB headroom
M3 Max (36 GB) (36 GB)
24.8 GB headroom
💡 Pro Tips:
- Always use the "with safety margin" figure when buying a GPU
- Q4 gives 90-95% quality with 25% size reduction. Q5 is better if you have room
- Context overhead grows with conversation length. Budget 1-3 GB for typical usage
- Batch size matters for multi-user APIs. Single-user chat can ignore batch overhead
📋 Share this configuration:
Melhores LLMs Locais para 16 GB de VRAM (2026)
O melhor LLM local para uma GPU de 16 GB de VRAM em 2026 é o Mistral Small 3.1 24B em Q4_K_M: ele usa ~13 GB, roda a 55 tok/sec, e é o modelo geral mais forte que cabe com folga de contexto. Placas de 16 GB (NVIDIA RTX 5080, RTX 5070 Ti, RTX 4080 usada, ou uma RTX 4090 de laptop) chegam ao teto em modelos 14-24B — um modelo 70B precisa de ~40 GB e não cabe.
Para codificação agêntica, o Devstral Small 24B Q4_K_M cabe em ~16 GB; para raciocínio, o DeepSeek-R1 14B Q8_0 é a escolha. O mais novo Mistral Small 4 (março de 2026) é um modelo único que integra raciocínio, visão e codificação e é o sucessor natural como padrão da classe de 16 GB. A tabela abaixo mostra o que cabe e o que não cabe — as linhas "NÃO cabe" são o erro mais comum que os donos de 16 GB cometem.
| Modelo | Quantização | VRAM Usada | Velocidade (RTX 4080) | Melhor Para | Cabe em 16 GB? |
|---|---|---|---|---|---|
| Mistral Small 3.1 24B | Q4_K_M | ~13 GB | 55 tok/sec | Chat geral | ✅ Sim |
| Devstral Small 24B | Q4_K_M | ~16 GB | 45 tok/sec | Codificação agêntica | ✅ Apertado |
| Qwen3 14B | Q8_0 | ~15 GB | 45 tok/sec | Codificação + raciocínio | ✅ Sim |
| DeepSeek-R1 14B | Q8_0 | ~15 GB | 40 tok/sec | Matemática + análise | ✅ Sim |
| Llama 3.1 8B | FP16 | ~16 GB | 70 tok/sec | Respostas mais rápidas | ✅ Apertado |
| Llama 3.3 70B | Q4_K_M | ~39 GB | -- | -- | ❌ Não (precisa de 39 GB) |

•ProTip: 🏆 Melhor geral para 16 GB: Mistral Small 3.1 24B Q4_K_M a ~13 GB, 55 tok/sec. Para codificação agêntica, use o Devstral Small 24B (Mistral AI, França) a 45 tok/sec. Melhor raciocínio: DeepSeek-R1 14B Q8_0 a 40 tok/sec.
⚠️Warning: As GPUs RTX 4090 de laptop têm 16 GB de VRAM (não 24 GB). Elas compartilham o mesmo teto de modelos da RTX 4080 de desktop.
•KeyPoint: Quando migrar para 24 GB (RTX 4090 desktop): apenas se você precisar de modelos 32B+ em Q8, ou quiser rodar dois modelos simultaneamente sem recarregar.
Quais LLMs Locais Rodam Melhor em 12 GB de VRAM?
Em uma GPU de 12 GB de VRAM (NVIDIA RTX 5070, RTX 4070 Ti ou RTX 3060 12 GB), você pode rodar modelos 7-8B em Q8 ou 14B em Q4_K_M. Nota: modelos MoE como o Llama 4 Scout NÃO cabem aqui -- embora o Scout ative apenas 17B de parâmetros por token, todos os 109B experts no total precisam ser carregados na memória, exigindo ~55 GB em Q4.
O Llama 3.1 8B em Q8_0 é a escolha mais confiável para configurações conservadoras: 9 GB de VRAM, 80 tok/sec e qualidade total de seguir instruções. O Qwen3 14B em Q4_K_M também cabe em ~8,5 GB e entrega um raciocínio notavelmente melhor que a faixa de 8B.
| Modelo | Quantização | VRAM Usada | Velocidade (RTX 4070 Ti) | Melhor Para | Cabe em 12 GB? |
|---|---|---|---|---|---|
| Llama 3.1 8B | Q8_0 | ~9 GB | 80 tok/sec | Melhor geral, chat geral + codificação | ✅ Sim |
| Qwen3 14B | Q4_K_M | ~8.5 GB | 65 tok/sec | Melhor raciocínio com orçamento limitado | ✅ Sim |
| Llama 3.2 11B Vision | Q5_K_M | ~8 GB | 65 tok/sec | Tarefas de imagem + texto | ✅ Sim |
| Qwen3 8B | Q8_0 | ~8 GB | 85 tok/sec | Melhor em multilíngue + codificação | ✅ Sim |
| Mistral Small v0.3 | FP16 | ~14 GB | -- | -- | ❌ Não (precisa de 14 GB em FP16) |
| Llama 4 Scout (109B total MoE) | Q4_K_M | ~55 GB | -- | -- | ❌ Não (todos os 109B experts precisam carregar) |
•ProTip: 🏆 Melhor geral para 12 GB: Llama 3.1 8B Q8_0 a ~9 GB, 80 tok/sec. Para melhor raciocínio na mesma placa, use o Qwen3 14B Q4_K_M a ~8,5 GB. O Llama 4 Scout não cabe -- seus 109B experts MoE no total precisam de ~55 GB em Q4.
•KeyPoint: A RTX 3060 12GB é o ponto de entrada econômico (~$200 usada). Ela roda todos os modelos de 12 GB, mas a ~60-70 tok/sec vs ~80-90 tok/sec na RTX 4070 Ti, devido à arquitetura de memória mais antiga.
Quais Modelos 70B Realmente Cabem em 24 GB de VRAM (RTX 4090)?
O requisito de hardware para rodar um modelo 70B localmente com qualidade Q4_K_M utilizável é de ~40 GB de VRAM — então uma única RTX 4090 de 24 GB não é suficiente. Suas opções reais para 70B em 2026 são: 2× RTX 5090 (64 GB combinados), uma RTX 5090 (32 GB) com leve offload de CPU, uma GPU de servidor de 48-80 GB (RTX 6000 Ada / A100), ou um Apple M5 Max / sistema com 128 GB de memória unificada. O equívoco comum é achar que "Q4 é pequeno" — com 70B de parâmetros, até o Q4 precisa de ~40 GB.
Em uma única placa de 24 GB, a melhor estratégia é um modelo 27-32B, que entrega forte qualidade e cabe confortavelmente com folga de contexto. O Qwen3.6 27B em Q4_K_M é o melhor modelo de codificação denso (77,2% SWE-bench); o DeepSeek-R1 32B é a melhor escolha de raciocínio. Uma GPU de 24 GB só comporta 70B em Q2_K, onde a qualidade cai visivelmente. Veja como rodar modelos 70B em 24 GB de VRAM para técnicas de offload e dual-GPU.
| Modelo | Quantização | VRAM Necessária | Cabe em 24 GB? | Velocidade (RTX 4090) | Notas |
|---|---|---|---|---|---|
| Qwen 3.6 27B | Q4_K_M | ~16 GB | ✅ Sim | 55 tok/sec | Melhor modelo de codificação denso, 77,2% SWE-bench |
| DeepSeek-R1 32B | Q4_K_M | ~19 GB | ✅ Sim | 60 tok/sec | Melhor raciocínio, forte qualidade geral |
| Qwen3 32B | Q5_K_M | ~21 GB | ✅ Sim | 55 tok/sec | Alta qualidade, excelente codificação + instrução |
| Qwen3 32B | Q8_0 | ~34 GB | ❌ Não | -- | Requer GPU de 48 GB |
| Llama 3.3 70B | Q2_K | ~24 GB | ⚠️ Mal | 30 tok/sec | Cabe, mas a qualidade do Q2 é visivelmente degradada |
| Llama 3.3 70B | Q4_K_M | ~39 GB | ❌ Não | -- | Precisa de 2× RTX 4090 ou A100 80 GB |

•KeyPoint: 🏆 Melhor para RTX 4090 (24 GB): Qwen 3.6 27B Q4_K_M (~16 GB, 77,2% SWE-bench) como melhor modelo de codificação denso. Para raciocínio: DeepSeek-R1 32B Q4_K_M (~19 GB, 60 tok/sec). Melhor que o Llama 3.3 70B Q2_K com muito menos VRAM.
⚠️Warning: Se você precisa especificamente de qualidade 70B em Q4+, a RTX 4090 não é a GPU certa. Você precisa de 2× RTX 4090 (48 GB combinados via paralelismo de tensores) ou uma RTX 6000 Ada (48 GB). Rodar 70B em Q2_K em uma única 4090 prejudica visivelmente a qualidade da saída.
De Qual CPU e RAM Você Precisa?
Com uma GPU dedicada, CPU e RAM são componentes secundários. A GPU lida com a matemática de matrizes; CPU/RAM gerenciam a preparação do contexto. Para uma comparação completa das velocidades de inferência de GPU vs CPU vs Apple Silicon, veja o guia de GPU vs CPU vs Apple Silicon.
CPU mínima: processador de 8 núcleos (Intel Core i7 14ª geração, AMD Ryzen 7 7700X ou mais novo). CPUs mais antigas adicionam 20%+ de latência.
RAM: 16 GB no mínimo (com GPU). Se rodar sem GPU, recomenda-se 32+ GB. A RAM não limita diretamente o tamanho do modelo quando há uma GPU presente.
Armazenamento: SSD de 500 GB para os arquivos de modelo e o SO. M.2 NVMe é preferível (carregamento de modelo mais rápido).
Quais Modelos Rodam Bem em 16 GB de RAM do Sistema Sem uma GPU?
Sem uma GPU, uma máquina com 16 GB de RAM do sistema pode rodar modelos 3B-7B a 8-20 tokens/sec usando inferência por CPU. O gargalo é a largura de banda de memória, não a capacidade de RAM -- as CPUs têm largura de banda muito menor que as GPUs, e é por isso que a inferência é 5-10× mais lenta.
Com 16 GB de RAM do sistema, a regra prática é: tamanho do arquivo do modelo + 4 GB de sobrecarga do SO ≤ 16 GB. Um modelo 7B em Q4_K_M (4,9 GB) cabe, mas deixa pouca folga para contextos longos. A tabela abaixo mostra opções realistas em julho de 2026.
Para um guia completo de modelos otimizados para velocidade cobrindo as faixas de apenas CPU, 4 GB, 6 GB e 8 GB de VRAM com benchmarks reais, veja **LLMs Locais Mais Rápidos para PCs de Baixo Desempenho**.
| Modelo | Quantização | RAM Usada | Velocidade (Ryzen 9 7950X) | Melhor Para | Notas |
|---|---|---|---|---|---|
| Gemma 2 2B | Q8_0 | ~2.7 GB | 28 tok/sec | Mais rápido, RAM mínima | Deixa 13 GB livres para o SO |
| Phi-4 Mini 3.8B | Q4_K_M | ~2.5 GB | 25 tok/sec | Codificação em CPU | Melhor relação qualidade-por-RAM |
| Llama 3.2 3B | Q8_0 | ~3.8 GB | 20 tok/sec | Chat geral, pouca RAM | Confiável, amplamente suportado |
| Llama 3.1 8B | Q4_K_M | ~4.9 GB | 12 tok/sec | Melhor qualidade em CPU | 12 tok/sec é lento mas usável para tarefas em lote |
| Llama 3.1 8B | Q8_0 | ~9 GB | 8 tok/sec | Qualidade máxima em CPU | Lento demais para uso interativo na maioria das CPUs |

•ProTip: 🏆 Melhor para 16 GB de RAM, sem GPU: Phi-4 Mini 3.8B Q4_K_M (2,5 GB, 25 tok/sec). Entrega codificação e raciocínio surpreendentemente fortes para o seu tamanho.
•KeyPoint: Realidade de velocidade CPU vs GPU: Uma NVIDIA RTX 3060 12 GB usada (~$200) roda o Llama 3.1 8B a 70+ tok/sec -- 5-8× mais rápido que o Ryzen 9 7950X em inferência apenas por CPU. Se a velocidade importa, compre uma GPU antes de adicionar RAM.
⚠️Warning: Rodar um modelo 7B em 16 GB de RAM apenas por CPU deixa menos de 7 GB para o SO e o navegador. Com contextos de conversa longos (32k+ tokens), o arquivo do modelo cresce além do seu tamanho base e pode causar esgotamento de RAM. Mantenha o tamanho do contexto abaixo de 4096 em máquinas de 16 GB apenas por CPU.
Quanto Armazenamento Você Precisa?
Os arquivos de modelo são grandes: um modelo 7B em quantização de 4 bits tem 4-5 GB. Planeje o armazenamento em torno do número e do tamanho dos modelos que você quer manter localmente.
- SSD de 500 GB: SO + 1-2 modelos pequenos (3B, 7B)
- SSD de 1 TB: SO + 3-5 modelos (mistura de 7B e 13B)
- SSD de 2 TB: SO + 10+ modelos (vários tamanhos)
- NVMe RAID de 4 TB: Configuração de produção, carregamento rápido de modelos
Qual Montagem de Hardware Você Deve Comprar?
Montar uma máquina para LLM local do zero significa priorizar a GPU primeiro, depois a CPU e a RAM. Aqui estão três configurações realistas. Para montagens com múltiplas GPUs, veja o guia de LLM local com múltiplas GPUs. Para configurações de automação residencial, mini PCs compactos costumam ser mais adequados que montagens de desktop completas — veja o melhor Mini PC para Home Assistant com IA local →.
| Orçamento | GPU | CPU | RAM | Modelos | Custo |
|---|---|---|---|---|---|
| $1500 (entrada) | RTX 4070 Ti | i7 13700 | 16 GB | 7-13B | Realista |
| $2500 (sólida) | RTX 4080 | i7 14700K | 32 GB | 13-30B | Recomendada |
| $4000 (topo de linha) | 2× RTX 4090 | Ryzen 9 7950X | 128 GB | Qualquer (70B+) | Exagero para uso pessoal |

E Se Você Não Puder Pagar Pelo Hardware?
Se uma GPU de $250–400 está fora do seu orçamento, ou seu laptop é antigo demais para suportar motores de inferência modernos, os LLMs locais podem não ser custo-efetivos para você em 2026.
Calcule o custo real:
- Local: $800–2,000 de hardware inicial + eletricidade + manutenção ao longo de 2–3 anos
- Nuvem: $5–50/mês para uso típico de desenvolvedor (API do Llama ou GPT-5.5 mini)
Para usuários leves (< 100.000 tokens/mês), as APIs de nuvem custam $5–10/mês e exigem zero hardware. Para usuários pesados (> 10M tokens/mês), o local se paga em 6–12 meses.
Compare os trade-offs completos de custo e desempenho de local vs nuvem** para encontrar o seu ponto de equilíbrio. Muitos desenvolvedores descobrem que a nuvem é mais barata para o seu padrão de uso real.
Já está procurando abaixo das faixas de VRAM recomendadas? Veja Melhor App de IA Local para um PC de Baixo Desempenho para saber quais combinações de modelo e app realmente rodam em 8 GB ou menos.
Como Você Maximiza a Velocidade do llama.cpp na RTX 4070 Ti?
Com as configurações corretas, o llama.cpp em uma RTX 4070 Ti atinge 85-95 tokens/sec no Llama 3.1 8B Q4_K_M -- mais que o dobro da velocidade padrão de fábrica. A flag de maior impacto é a `--n-gpu-layers 99`, que descarrega todas as camadas do modelo para a GPU. Sem ela, as camadas voltam para a CPU, criando um gargalo severo.
Essas configurações se aplicam ao llama.cpp diretamente e ao Ollama (que usa o llama.cpp internamente). O Ollama define `--n-gpu-layers 99` automaticamente em hardware NVIDIA se os drivers estiverem instalados corretamente.
- O Q4_K_M supera o Q4_0 em 15-20% na RTX 4070 Ti. A variante K_M usa quantização mista que os tensor cores da NVIDIA aceleram de forma mais eficiente. Sempre escolha Q4_K_M em vez de Q4_0 quando ambos estiverem disponíveis.
- O IQ4_XS é o formato menor (~8% menor que o Q4_K_M) com perda mínima de qualidade. Útil para encaixar o Qwen3 14B em 12 GB de VRAM quando o Q4_K_M fica no limite.
- O Q5_K_M roda em quase a mesma velocidade que o Q4_K_M nas GPUs NVIDIA (< 5% mais lento) enquanto oferece uma qualidade de saída notavelmente melhor. Vale a pena usar quando você tem 20% de folga de VRAM.
| Flag | O Que Faz | Impacto | Padrão | Notas |
|---|---|---|---|---|
| --n-gpu-layers 99 | Descarrega todas as camadas para a GPU | +100-150% de velocidade | 0 (apenas CPU) | Flag mais importante -- sempre defina esta primeiro |
| --threads [núcleos] | Threads de CPU para processamento do prompt | +10-15% de velocidade | Todas as threads (incluindo HT) | Defina apenas como a contagem de núcleos físicos. Hyperthreading prejudica a inferência. |
| --ctx-size 2048 | Tamanho do cache KV / janela de contexto | Economiza 0,5-8 GB de VRAM | 4096 | 2048 = ~0,5 GB de VRAM extra. 32768 = ~8 GB extra. Só aumente se necessário. |
| --n-batch 512 | Tamanho do lote de processamento do prompt | +5-10% de throughput | 512 | Bom padrão. Aumente para 1024 em cargas de trabalho em lote se a VRAM permitir. |
| --flash-attn | Kernel Flash Attention 2 | -20-30% de VRAM em contexto longo | Desativado | Disponível desde o llama.cpp b2900. Reduz a VRAM para contextos > 8k tokens. |

•ProTip: Rode `ollama ps` para confirmar que seu modelo está carregado na GPU. Se a utilização da GPU mostrar 0% no `nvidia-smi` durante a geração, os drivers não estão roteando corretamente para o CUDA. Reinstale o NVIDIA CUDA Toolkit e reinicie o Ollama.
•KeyPoint: Referência de velocidade da RTX 4070 Ti: Llama 3.1 8B Q4_K_M = 85-95 tok/sec. Llama 3.3 13B Q4_K_M = 60-70 tok/sec. Qwen3 7B Q8_0 = 90-95 tok/sec. Estes assumem --n-gpu-layers 99 e --ctx-size 2048.
⚠️Warning: Aumentar o --ctx-size além de 8192 em uma GPU de 12 GB fará com que as camadas do modelo voltem a ser descarregadas para a CPU se o cache KV esgotar a VRAM restante. Se a velocidade cair de repente em conversas longas, reduza o tamanho do contexto ou use --flash-attn.
O Hardware Mac Pode Rodar LLMs Locais?
O Apple Silicon (série M) roda LLMs locais com eficiência usando memória unificada compartilhada entre CPU e GPU. O M5 base foi lançado em outubro de 2025; o M5 Pro e o M5 Max vieram em março de 2026. A Apple mede um processamento de prompt de LLM (tempo-até-o-primeiro-token) até 4× mais rápido no M5 Pro/Max vs a geração M4, embora os ganhos na geração de tokens sejam mais modestos.
O M5 Max com 128 GB de memória unificada (até 614 GB/s) roda modelos 70B em Q4_K_M confortavelmente — cerca de 12-15 tok/sec — em formato de laptop ou Mac Studio. O M5 Pro (até 64 GB unificada, 307 GB/s) lida com modelos 32B com folga generosa para cache KV e multitarefa. Em julho de 2026, o M5 Max é o topo do Apple Silicon em comercialização; um Mac Studio com M5 Ultra é rumor, mas ainda não foi lançado. Vale notar que o M5 Max ainda fica bem aquém dos ~239 GB que o GLM-5.2 precisa mesmo em 2 bits -- uma área em que o teto de memória unificada da Apple pesa mais que a velocidade bruta.
Em um MacBook com 8 GB de RAM, fique com modelos 3-4B. Com a memória unificada compartilhada entre o SO e o modelo, 8 GB comporta realisticamente o Phi-4 Mini 3.8B, o Llama 3.2 3B ou o Gemma 3 4B em Q4_K_M via Ollama ou llama.cpp (ambos usam o backend de GPU Metal automaticamente). Um modelo 7B fica no limite com 8 GB e fará swap sob carga; 16 GB é o mínimo confortável para modelos 7-8B em um Mac.
| Mac | Memória de GPU | Melhor Para | Limitação |
|---|---|---|---|
| Série M 8 GB (Air / base) | 8 GB unificada | modelos 3-4B (Phi-4 Mini, Gemma 3 4B) | 7B no limite; o SO compete pela RAM |
| M3 Pro MacBook Pro 16" | 18 GB unificada | modelos 7-8B (rápido) | Pode rodar 14B lentamente |
| M4 Max | 36-128 GB unificada | modelos 13-32B | 70B apenas na configuração máxima de 128 GB |
| M5 Pro (MacBook Pro) | 64 GB unificada, 307 GB/s | modelos 32B confortavelmente | O Llama 4 Scout roda bem |
| M5 Max (MacBook Pro / Studio) | 128 GB unificada, até 614 GB/s | modelos 70B em Q4_K_M | ~12-15 tok/sec em 70B |

Quando Você Deve Usar Hardware de Servidor vs de Consumidor?
Para implantação em produção (operação 24/7, múltiplos usuários), recomenda-se hardware de nível servidor em vez de GPUs de consumo. O hardware de consumo é otimizado para jogos, não para inferência sustentada.
- Consumidor (RTX 5090): ~$2,000 MSRP (~$4,300–5,000+ de rua a partir de julho de 2026), 32 GB de VRAM, monousuário, propenso a throttling térmico sob carga sustentada.
- Servidor (RTX 6000 Ada): ~$7,000, 48 GB de VRAM, projetada para uso 24/7, melhor refrigeração, correção de erros.
- Recomendação: Comece com uma RTX 5090. Se for rodar modelos 70B 24/7 para múltiplos usuários, migre para A100 dupla ou RTX 6000 Ada.

NVIDIA DGX Spark: Computador de IA de Desktop com 128 GB
A NVIDIA DGX Spark ($4,699 em fevereiro de 2026, acima do preço de lançamento de $3,999) é um computador de IA de desktop compacto com 128 GB que pode comportar o Llama 3.3 70B em Q8_0 inteiramente na memória unificada. O Apple Mac Studio / MacBook Pro com 128 GB e os sistemas AMD Strix Halo de 128 GB podem fazer o mesmo, então ela não é única — mas vem com a pilha de software CUDA da NVIDIA.
Construída sobre o Superchip GB10 Grace Blackwell, a DGX Spark foi lançada em outubro de 2025 com 128 GB de memória unificada LPDDR5x. Nota: sua largura de banda de memória real é de ~273 GB/s, então a geração de tokens em 70B denso é lenta — testes independentes (LMSYS) mediram cerca de 3 tok/sec no Llama 70B. A cifra de destaque de computação FP4 não se traduz em decodificação de fluxo único rápida. A DGX Spark é mais adequada para grandes modelos mixture-of-experts (Llama 4 Scout/Maverick, Kimi K2) onde apenas uma fração dos parâmetros é ativada por token -- mas o seu teto de 128 GB não é ilimitado: o GLM-5.2 (744B no total, 40B ativos, lançado em junho de 2026) precisa de ~239 GB mesmo em quantização de 2 bits e não cabe em uma única DGX Spark.
| Especificação | Valor |
|---|---|
| Memória unificada | 128 GB LPDDR5x |
| Llama 3.3 70B em Q4_K_M | ✅ cabe (40 GB) |
| Llama 3.3 70B em Q8_0 | ✅ cabe (70 GB) |
| GLM-5.2 em 2-bit (~239 GB) | ❌ não cabe |
| Velocidade de inferência (70B) | ~3 tok/s |
| Preço | $4,699 |
| SO | DGX OS (Ubuntu), Ollama pré-instalado |
| Largura de banda de memória | ~273 GB/s (real) |
| vs RTX 5090 | 4× mais memória, mas largura de banda muito menor |
•KeyPoint: Uma GPU discreta (RTX 5090, ou 5090 dupla) gera tokens muito mais rápido que a DGX Spark em modelos densos por causa da largura de banda de memória muito maior. Escolha a DGX Spark pela capacidade — comportar modelos MoE muito grandes em uma única caixa — não pela velocidade de fluxo único em 70B.
Quais São os Erros de Hardware Mais Comuns?
- Comprar apenas CPU quando há GPU disponível. Uma RTX 4070 Ti de $600 vai superar uma CPU de $2000. A GPU domina a velocidade do LLM.
- Não contabilizar a sobrecarga de VRAM. Tamanho do arquivo do modelo + sobrecarga do sistema + contexto = VRAM total usada. Sempre compre 25% a mais do que o tamanho do modelo.
- Assumir que todos os modelos 70B cabem em 40GB de VRAM. Eles cabem, mal, apenas em quantização Q4 (4 bits). Q5 requer 45+ GB.
- Ignorar a fonte de alimentação e a refrigeração. A RTX 4090 consome 575W. Precisa de uma PSU de 1200W e bom fluxo de ar no gabinete.
- Achar que uma GPU antiga vai funcionar. A RTX 2080 é 10× mais lenta que a RTX 4070 Ti. A arquitetura de GPU moderna supera significativamente as gerações anteriores.
- Não contabilizar a VRAM do cache KV além dos pesos do modelo: Um modelo 7B em Q4_K_M tem 4,7 GB de pesos -- mas com uma janela de contexto de 32K, o cache KV adiciona ~4 GB a mais, totalizando ~8,7 GB. Em uma placa de 8 GB isso causa erros de OOM. Sempre adicione 25-100% ao tamanho do modelo dependendo do comprimento do contexto.
- Tratar o custo do hardware como o único custo: Se você não pode pagar 16+ GB de RAM ou uma GPU dedicada, as APIs de nuvem custam menos para uso de baixo volume ($0,01–0,05 por 1K tokens). Veja LLM Local vs Nuvem: Análise de Custo para o trade-off completo.
Quais Regras de Conformidade Regional se Aplicam ao Hardware de LLM Local?
UE (GDPR + Lei de IA da UE): Rodar LLMs localmente mantém todos os dados de inferência dentro da sua infraestrutura, eliminando preocupações com transferência transfronteiriça de dados sob o Artigo 44 do GDPR. As obrigações da Lei de IA da UE para sistemas de IA autônomos de alto risco (Anexo III) estavam originalmente previstas para se aplicar a partir de 2 de agosto de 2026, mas o "Digital Omnibus on AI" — acordado provisoriamente em maio de 2026 e aguardando adoção formal em junho de 2026 — adia essa data para 2 de dezembro de 2027 (com a IA de alto risco embutida em produtos regulados adiada para 2 de agosto de 2028). Os deveres de transparência do Artigo 50 da Lei de IA ainda se aplicam no cronograma original. O hardware local atende aos requisitos de residência de dados por padrão.
Japão (APPI): A emenda de 2022 da APPI do Japão endureceu as regras de notificação de violação e de transferência transfronteiriça, mas não impõe um requisito de minimização de dados específico para IA (ela se apoia nos deveres gerais de limitação de finalidade). Mais relevantes para a IA são o pacote de reforma da APPI de 2025 do Japão e sua primeira lei de IA — a Lei de Promoção de IA (em vigor desde junho de 2025), um marco que prioriza a inovação e sem penalidades. O hardware de LLM on-premises mantém os dados pessoais dentro da sua infraestrutura para processamento de documentos e automação de suporte ao cliente.
China: As Medidas Provisórias para Serviços de IA Generativa da Administração do Ciberespaço da China (CAC) (em vigor desde agosto de 2023) exigem que provedores com influência sobre a opinião pública concluam uma avaliação de segurança da CAC e um registro de algoritmo. Desde 1º de setembro de 2025, a China também exige a rotulagem de conteúdo gerado por IA sob as Medidas de rotulagem da CAC e o padrão nacional GB 45438-2025. Rodar hardware local com modelos de pesos abertos evita a exposição à conformidade baseada em API para uso empresarial interno.
Perguntas Comuns Sobre Hardware de LLM Local
Posso rodar um modelo 70B em um laptop?
Apenas com quantização pesada (Q2, 2 bits) e fallback de CPU. Impraticável. Laptops são adequados para modelos 7B. Para 70B, use um desktop com RTX 4090+.
A RTX 4090 é exagero para uso pessoal?
Não se você rodar modelos 70B ou múltiplos modelos simultaneamente. Para apenas chat 7B, a RTX 4070 Ti é suficiente. A RTX 4090 é à prova de futuro se você quiser flexibilidade.
Devo comprar a RTX 5090 ou esperar pela RTX 6090?
A RTX 5090 está disponível (início de 2026). As GPUs de servidor RTX 6000 Ada também são sólidas. A menos que você tenha orçamento ilimitado, a RTX 5090 ou a 4090 são excelentes.
Como a quantização afeta a qualidade?
FP16 = 100% da qualidade (base), Q8 = 99%, Q5 = 95%, Q4 = 90-95%. Para a maioria das tarefas, o Q4 é indistinguível do FP16.
Posso atualizar a GPU depois?
Sim. Comece com a RTX 4070 Ti agora, migre para a RTX 5090 em 2 anos se necessário. A GPU é o componente mais substituível.
De quanta RAM eu preciso para rodar um modelo 7B localmente?
8 GB de RAM é o mínimo absoluto para um modelo 7B. 16 GB é recomendado para uso confortável junto com o navegador e o SO. 32 GB dá folga para janelas de contexto maiores e multitarefa.
Posso rodar LLMs locais no Apple Silicon (M1/M2/M3/M4/M5)?
Sim. O Apple Silicon usa memória unificada compartilhada entre CPU e GPU. O M5 Pro (64 GB, 307 GB/s) roda modelos 32B bem. O M5 Max (128 GB, até 614 GB/s) roda 70B em Q4_K_M a cerca de 12-15 tok/sec. Em um Mac de 8 GB, fique com modelos 3-4B.
Quais são os melhores modelos llama.cpp para um MacBook com M3 e 8 GB de RAM?
Em um MacBook M3 com 8 GB de RAM, rode modelos 3-4B em Q4_K_M: Phi-4 Mini 3.8B, Llama 3.2 3B ou Gemma 3 4B. Use Ollama ou llama.cpp — ambos usam o backend de GPU Metal automaticamente. Um modelo 7B fica no limite e fará swap sob carga; mantenha o contexto abaixo de 4096 tokens. Para uso confortável de 7-8B em um Mac, 16 GB de memória unificada é o mínimo prático.
Qual CPU é melhor para LLMs locais sem uma GPU?
CPUs com alta contagem de núcleos e grande cache L3: AMD Ryzen 9 7950X ou Intel Core i9-14900K. Espere 5-15 tokens/sec para modelos 7B. A inferência por CPU é 3-5× mais lenta que por GPU.
A velocidade do armazenamento afeta o desempenho do LLM local?
Sim, no momento de carregar o modelo. Um SSD NVMe (3-7 GB/s) carrega um modelo 7B em 2-5 segundos vs. 20-60 segundos em HDD. A velocidade de inferência após o carregamento não é afetada pelo armazenamento.
Posso usar múltiplas GPUs para rodar modelos maiores?
Sim, via paralelismo de tensores. Duas RTX 5090 (32 GB cada) fornecem 64 GB de VRAM, suficiente para um modelo 70B em Q4_K_M. O Ollama e o llama.cpp suportam multi-GPU via --n-gpu-layers dividido entre as placas.
Quais são os melhores LLMs locais para 16 GB de VRAM em 2026?
O Mistral Small 3.1 24B Q4_K_M (13 GB, 55 tok/sec) é o melhor geral para a RTX 5080 / RTX 5070 Ti / RTX 4090 de laptop. Para codificação agêntica: Devstral Small 24B Q4_K_M (16 GB, 45 tok/sec). Para raciocínio: DeepSeek-R1 14B (15 GB, 40 tok/sec). O mais novo Mistral Small 4 (março de 2026) é o sucessor de modelo único. O Llama 3.3 70B não cabe -- ele requer ~40 GB em Q4_K_M.
Uma única RTX 4090 pode rodar um modelo 70B com boa qualidade?
Não -- não com qualidade Q4_K_M. O Llama 3.3 70B em Q4_K_M requer ~39 GB de VRAM. A RTX 4090 tem 24 GB. Você pode rodá-lo em Q2_K (~24 GB), mas a qualidade cai visivelmente. Melhores opções: Qwen 3.6 27B Q4_K_M (~16 GB, 77,2% SWE-bench, melhor codificação densa) ou DeepSeek-R1 32B Q4_K_M (~19 GB, melhor raciocínio).
Qual é o melhor LLM local para 16 GB de RAM do sistema sem uma GPU?
O Phi-4 Mini 3.8B Q4_K_M (2,5 GB de RAM, ~25 tok/sec no Ryzen 9 7950X) é a melhor opção para inferência apenas por CPU em 16 GB de RAM do sistema. O Gemma 2 2B Q8 é o mais rápido a ~28 tok/sec. O Llama 3.1 8B Q4_K_M (4,9 GB) também cabe, mas roda a ~12 tok/sec -- lento para uso interativo.
Qual é a regra prática de memória para um modelo 7B em quantização Q4?
Um modelo 7B em quantização Q4_K_M precisa de cerca de 4-5 GB de VRAM (ou RAM do sistema para inferência apenas por CPU) -- aproximadamente 0,6 GB por bilhão de parâmetros em precisão de 4 bits. Isso escala linearmente: um modelo 14B precisa de ~9 GB, um modelo 32B precisa de ~19 GB, e um modelo 70B precisa de ~40 GB, todos em Q4_K_M.
Que hardware eu preciso para rodar o GLM-5.2 localmente?
O GLM-5.2 (Z.ai, lançado em junho de 2026) é um modelo MoE de 744B de parâmetros com 40B ativos por token. Mesmo o GGUF dinâmico mais agressivo, de 2 bits, precisa de ~239 GB de VRAM/RAM combinadas -- grande demais para uma única RTX 5090 (32 GB), uma DGX Spark de 128 GB ou um Mac Studio de 128 GB. Caminhos locais realistas são uma configuração com 4× RTX 3090/4090 e 192 GB+ de RAM do sistema, ou um Mac Studio de 256 GB+, ambos rodando a cerca de 3-9 tokens/sec via offload híbrido CPU/GPU. Para a maioria dos usuários, o GLM-5.2 é, na prática, apenas para nuvem.
Fontes
- NVIDIA. (2026). "GeForce GPU Specifications." https://www.nvidia.com/en-us/geforce/graphics-cards/ -- Especificações oficiais de VRAM e largura de banda para as GPUs RTX série 40 e RTX série 50.
- Apple. (2026). "Apple M5 Chip." https://www.apple.com/mac/ -- Especificações do M5 Pro/Max, largura de banda de memória, alegações de desempenho de LLM. O M5 é o primeiro Mac que roda confortavelmente modelos 70B em Q4_K_M.
- NVIDIA. (2025). "DGX Spark Product Page." https://www.nvidia.com/en-us/products/workstations/dgx-spark/ -- Especificações oficiais do Superchip GB10 Grace Blackwell e dos 128 GB de memória unificada.
- Meta AI. (2024). "Llama 3.3 Model Card." https://llama.meta.com/ -- Especificações oficiais e requisitos de VRAM do Llama 3.3 70B.
- Meta AI. (2025). "Llama 4 Model Card." https://llama.meta.com/ -- Arquitetura MoE do Llama 4 Scout/Maverick, requisitos de VRAM.
- Z.ai. (2026). "GLM-5.2: Built for Long-Horizon Tasks." https://huggingface.co/blog/zai-org/glm-52-blog -- Ficha oficial do modelo GLM-5.2: arquitetura MoE de 744B total / 40B ativos, licença MIT, data de lançamento.