
Key Takeaways
- Melhor opção por orçamento: Menos de US$ 200 — RX 6700 XT 12GB (US$ 150–200, a mais barata, atrito de configuração AMD) ou RTX A4000 16GB se a encontrar abaixo de US$ 230 (melhor VRAM por dólar). ~US$ 220 usada — RTX 3060 12 GB (melhor opção usada geral). ~US$ 390–400 nova — RTX 5060 Ti 16GB (melhor opção nova, mais margem de VRAM). Menos de US$ 500 — RTX 4070 Super 12GB (a mais rápida, 25–30 tok/s).
- RTX 3060 12 GB (US$ 170-220 usada): Roda todos os modelos 7B-8B em Q4/Q5 e a maioria dos densos 13B-14B em Q4. Melhor opção econômica usada.
- RTX 5060 Ti 16GB (~US$ 390-400 nova): Placa de geração atual com 4 GB a mais de VRAM que a 3060 — roda modelos 13B-14B com folga para janelas de contexto maiores. Melhor opção nova econômica.
- RTX 3060 6 GB: Limitada a modelos 3B (Phi-4 Mini, Llama 3.2 3B). Insuficiente para 7B.
- Melhor modelo geral em 12 GB: Qwen3 14B a ~9 GB VRAM, 9-12 tok/s. Melhor qualidade densa que cabe confortavelmente.
- Melhor modelo de código em 12 GB: Qwen3 8B a 16-20 tok/s.
- Melhor modelo de raciocínio em 12 GB: DeepSeek-R1 7B a 10-12 tok/s. Chain-of-thought.
- Descarte se: você quiser modelos de 70B, Llama 4 Scout (precisa de ~55 GB) ou 13B em Q8 — você precisa de 24 GB+ (RTX 4090).
A RTX 3060 12 GB (US$ 200–250 usada) roda o Qwen3 14B a 9–12 tok/s e é a melhor GPU econômica para LLMs locais em 2026.
Uma GPU econômica para IA é uma placa de vídeo que custa menos de US$ 300, mas ainda tem memória de vídeo (VRAM) suficiente para rodar um modelo de IA capaz numa velocidade utilizável no seu próprio computador.
O que você pode rodar na RTX 3060 12 GB?
A RTX 3060 12 GB é a melhor GPU econômica para LLMs locais em 2026. 12 GB de VRAM cabem todos os modelos 7B em quantização Q4/Q5, e a maioria dos 13B em Q4. Para orientação detalhada sobre os requisitos de VRAM por tamanho de modelo, veja o guia de requisitos de VRAM →. Veja abaixo os modelos exatos e as velocidades que você pode esperar:
A RTX 3060 12 GB roda o Qwen3 14B em Q4 (9 GB, ~9–12 tok/s), o Qwen3 8B (5,5 GB, ~16–20 tok/s) e todos os modelos 7B com folga.
A RTX 3060 12 GB tem 12 gigabytes de memória de vídeo — suficiente para modelos de IA de até cerca de 14 bilhões de parâmetros. Modelos maiores não cabem e rodam devagar.
| Modelo | Tamanho | Quantização | VRAM usada | Velocidade | Ideal para |
|---|---|---|---|---|---|
| Qwen3 14B | 14B (denso) | Q4_K_M | ~9 GB | 9-12 tok/s | Melhor qualidade geral que cabe |
| Qwen3 8B | 8B | Q4_K_M | ~7 GB | 16-20 tok/s | Código, uso geral |
| Gemma 4 E12B | 26B MoE | Q4_K_M | ~9 GB | 11-14 tok/s | Visão, multimodal |
| Mistral Small v0.3 | 7B | Q4_K_M | ~7 GB | 18 tok/s | Seguimento de instruções |
| DeepSeek-R1 7B | 7B | Q4_K_M | ~7 GB | 10-12 tok/s | Raciocínio, matemática |
| Gemma 4 E4B | E4B (multimodal) | Q4_K_M | ~5 GB | 18-22 tok/s | Visão leve, chat rápido |
| Llama 3.2 13B | 13B | Q4_K_M | ~11 GB | 8-10 tok/s | Chat de maior qualidade (só Q4, ajustado) |
Qwen3 14B (denso) é o modelo de maior qualidade que cabe confortavelmente numa RTX 3060 12 GB em Q4_K_M, usando ~9 GB. `ollama pull qwen3:14b`. Observação: o Llama 4 Scout (MoE de 17B ativos / 109B no total, contexto de 10M tokens, multimodal) precisa de ~55 GB em Q4 e normalmente não cabe em 12 GB — é uma opção de contexto longo / multimodal grande para máquinas com bastante VRAM, não uma recomendação de GPU econômica. O gpt-oss:20b (21B no total / 3,6B ativos MoE) precisa de 16 GB, ficando pouco fora do alcance de uma placa de 12 GB. Todas as velocidades medidas com Ollama numa RTX 3060 12 GB, 16 GB de RAM do sistema, Ryzen 7 7700X. Quantização Q4_K_M. As velocidades variam ±15% dependendo do tamanho do prompt e da janela de contexto.

O que você pode rodar na RTX 3060 6 GB?
A variante de 6 GB está muito limitada. Apenas modelos de 3B cabem confortavelmente. Modelos 7B em Q4 precisam de ~7 GB -- mais do que disponível. O offloading para CPU funciona, mas reduz a velocidade em 50-70%.
- Phi-4 Mini 3.8B (Q4): ~3 GB VRAM, 20-25 tok/s. Melhor raciocínio neste tamanho. Forte para matemática e lógica.
- Llama 3.2 3B (Q4): ~2,5 GB VRAM, 25-35 tok/s. Opção mais rápida. Boa para chat simples e perguntas e respostas.
- Gemma 2 2B (Q4): ~1,7 GB VRAM, 35-45 tok/s. Modelo mais leve. Boa para testar configurações.
- 7B com offloading: Possível, mas lento. Llama 7B com offload para CPU = ~5-8 tok/s. Utilizável apenas para processamento em lote não interativo.
- Recomendação: Se você tem uma placa de 6 GB, atualize para 12 GB usada (US$ 200-250) antes de investir tempo em soluções alternativas. O ganho de velocidade e qualidade do modelo vale a pena.
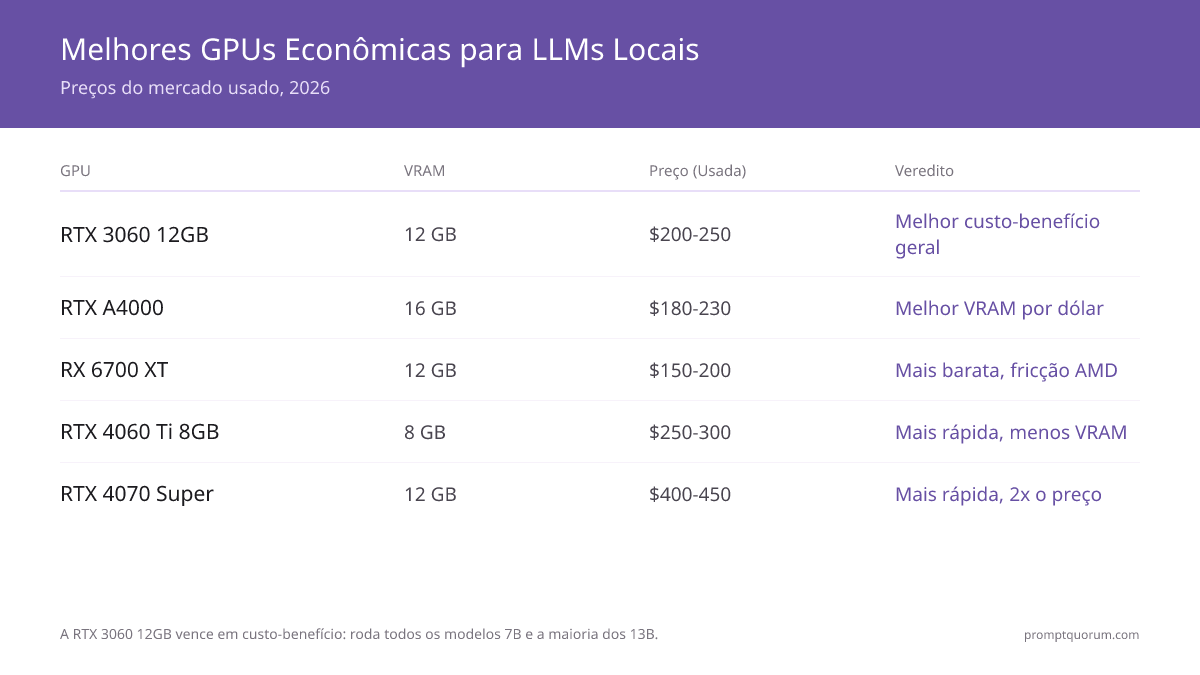
RTX 3060 vs outras GPUs econômicas
| GPU | VRAM | Preço (usada) | Velocidade 7B | Modelo máx. | Veredicto |
|---|---|---|---|---|---|
| RTX 3060 12 GB ★ | 12 GB | US$ 170-220 | 15-20 tok/s | 13B (Q4) | Melhor opção usada |
| RTX 5060 Ti 16GB | 16 GB | ~US$ 390-400 nova | 25-30 tok/s | 20B (Q4) | Melhor opção nova econômica |
| RTX 4060 Ti 8GB | 8 GB | US$ 250-300 | 20-25 tok/s | 7B (Q5 máx.) | Mais rápida mas menos VRAM |
| RTX A4000 | 16 GB | US$ 180-230 | 12-15 tok/s | 13B (Q5) | Melhor VRAM por dólar |
| RTX 4070 Super | 12 GB | US$ 400-450 | 25-30 tok/s | 13B (Q5) | Mais rápida, mas 2× o preço |
| RX 6700 XT | 12 GB | US$ 150-200 | 10-14 tok/s | 13B (Q4) | Mais barata, atrito com AMD |
A RTX 3060 12 GB vence em valor usada: 12 GB de VRAM a US$ 170-220 roda todos os modelos 7B e a maioria dos 13B. Se for comprar nova, a RTX 5060 Ti 16GB (~US$ 390-400) é a opção de geração atual com mais margem de VRAM. A RTX A4000 é uma segunda opção usada próxima se você encontrar uma por menos de US$ 230.
Quanta VRAM você precisa para modelos 7B?
Modelos 7B quantizados em Q4 (4 bits) exigem 6-8 GB de VRAM; Q5 (5 bits) exige 8-10 GB; Q8 (8 bits) exige 14-16 GB.
Na prática: 8 GB é o mínimo absoluto para inferência confortável em modelos 7B a Q4, com espaço para processamento em lote.
Placas de 6 GB (RTX 2060) tecnicamente funcionam, mas exigem otimização agressiva e não deixam margem para lotes maiores.
Se você tem menos de 8 GB de VRAM, ainda pode rodar LLMs locais com eficiência — **veja modelos otimizados para velocidade em hardware de 4-8 GB**.
O custo da GPU é um lado da economia; o custo por token é o outro. A inferência local elimina as tarifas de API por token, mas o tamanho do prompt ainda afeta a latência e o throughput. Para o panorama completo de custos — tokens, níveis de preço e estratégias de otimização — veja tokens, custos e limites: a economia do prompting com IA.
Melhores modelos por caso de uso na RTX 3060
Escolha seu modelo com base no que você realmente precisa, não na contagem de parâmetros. Estas são as melhores opções para cada caso de uso na RTX 3060 12 GB:
Hardware econômico roda modelos menores — mas um bom prompting fecha a diferença de qualidade. O guia de prompt engineering cobre técnicas como chain-of-thought e saída estruturada que ajudam modelos menores a render acima do seu peso. Uma carga de trabalho concreta que cabe no nível da RTX 3060 12 GB é a revisão automatizada de pull requests — veja revisão de código com LLM local em CI/CD para o padrão de GitHub Actions que roda o Qwen3 8B contra PRs exatamente neste hardware.
- Chat / Perguntas e respostas: `ollama run qwen3:14b` — denso de 14B, ~9 GB VRAM, melhor qualidade em 12 GB. Para uma opção mais leve: `ollama run qwen3:8b` a ~7 GB.
- Código: `ollama run qwen3:8b` — sólido para código de uso geral. ~7 GB VRAM. 16-20 tok/s.
- Raciocínio / Matemática: `ollama run deepseek-r1:7b` — Raciocínio chain-of-thought. 10-12 tok/s. Mais lento, mas significativamente mais preciso em problemas de múltiplas etapas.
- Escrita / Criativo: `ollama run mistral:7b` — Melhor seguimento de instruções. 18 tok/s. Saída limpa e estruturada. Bom para rascunhos e reescrita.
- Visão / Imagens: `ollama run gemma4:e12b` — Multimodal (aceita imagens). 11-14 tok/s. Usa ~9 GB de VRAM. Para uma opção mais leve, `ollama run gemma4:e4b` a ~5 GB. Descreve fotos, lê capturas de tela, analisa gráficos.
- Privacidade / Offline: Qualquer um dos anteriores. Todos rodam 100% localmente. Nenhum dado sai do seu computador. Não requer internet após o download do modelo.
- Automação residencial / IA always-on: `ollama run phi4-mini` — Phi-4 Mini (3,8B, ~3 GB VRAM) lida com consultas de voz do Home Assistant num mini PC sem GPU dedicada. Veja o melhor hardware para IA em smart home →.
Usada vs. nova: onde comprar?
- Usada (US$ 50-100 mais barata): eBay, Facebook Marketplace, Craigslist, lojas locais de conserto de computadores. Maior risco de placas defeituosas ou VRAM ruim. Sempre teste antes de fechar negócio.
- Nova (US$ 280-400): Newegg, Amazon, Best Buy, Microcenter. Garantia incluída. Sem surpresas. Preços estáveis. Boa para compradores avessos a risco.
- Placas de mineração (cripto, muito baratas): Risco extremo. Degradação de VRAM é comum. Compre só se puder fazer teste de estresse completo no local.
Erros comuns com GPUs econômicas
- Comprar uma RTX 2060 de 4 GB esperando inferência fluida de 7B -- você vai enfrentar erros de memória constantemente.
- Combinar uma GPU de US$ 250 com uma fonte de US$ 30 -- a queda de tensão mata a estabilidade. Orce pelo menos 650W com certificação 80+ Gold.
- Assumir que RAM DDR5 e CPU i9 aceleram a inferência de LLMs -- não aceleram. A largura de banda da VRAM da GPU é o único gargalo que importa para a velocidade de inferência.
- Assumir que o Llama 4 Scout cabe em 12 GB. O Scout é um MoE de 17B ativos / 109B no total que precisa de ~55 GB em Q4 (só cabe em 24 GB com quantização extrema de 1,78 bit, ~20 tok/s). Numa RTX 3060 de 12 GB, rode modelos densos: Qwen3 14B (~9 GB), Qwen3 8B ou Gemma 4 E12B.
- Comprar uma placa de 16 GB só para modelos 13B. Uma RTX 3060 de 12 GB já roda o Qwen3 14B em Q4. Suba para 16 GB só se você precisar especificamente do gpt-oss:20b (16 GB), modelos densos de 20B+ ou mais margem de contexto.
Próximos passos
- Melhores GPUs AMD para LLMs locais — Considera AMD? Comparação completa AMD vs NVIDIA →
- Melhores modelos Ollama open source — Quais modelos rodam melhor em GPU econômica →
- Quanta VRAM preciso? — Encontre o equilíbrio entre GPU e tamanho do modelo →
- Melhor GPU custo-benefício nos Emirados Árabes Unidos — preços reais em AED de varejistas como Sharaf DG, noon.com e Amazon.ae →
Como as leis regionais de privacidade afetam a escolha de GPU para LLMs locais?
LGPD (Brasil): a inferência local em GPU econômica está em conformidade total -- sem nuvem, sem transferência de dados. Rodar Qwen3 ou Gemma 4 numa RTX 3060 mantém toda a inferência no dispositivo, o que atende às exigências de medidas de segurança técnicas da LGPD e reduz a exposição frente à ANPD, já que nenhum dado sai do computador para processamento em nuvem. Escritórios de advocacia, consultórios e freelancers brasileiros usam cada vez mais setups NVIDIA econômicos para processar documentos que não podem tocar APIs na nuvem.
UE (GDPR) e Ásia-Pacífico: a inferência local em GPU elimina a transferência de dados transfronteiriça. Empresas que atendem clientes europeus ou asiáticos evitam questões de residência de dados ao rodar o Ollama localmente numa GPU econômica -- a inferência acontece no dispositivo, sem chamadas de rede.
PMEs no Brasil e no mundo: setups de GPU econômica reduzem o custo de API e eliminam o vendor lock-in. Para pequenas empresas, uma RTX 3060 (US$ 200-250 usada) se paga em cerca de 2-3 meses comparado ao uso de API de modelos proprietários em volumes de tokens equivalentes, sem custos por token depois disso.
Perguntas frequentes
A RTX 3060 12 GB ainda vale a pena comprar em 2026?
Sim. Tem mais de 4 anos, mas 12 GB de VRAM é atemporal. Roda Qwen3 14B, Qwen3 8B, Gemma 4 E12B e Mistral Small sem esforço em Q4. Cabe em todos os modelos 7B-8B e na maioria dos densos 13B-14B.
Devo comprar a RTX 5060 Ti ou a RTX 4060 Ti para LLMs locais?
A RTX 5060 Ti 16GB (~US$ 390-400) é agora a melhor compra: 8 GB a mais de VRAM que a RTX 4060 Ti de 8GB e 10-15% mais rápida por geração. É a opção econômica de geração atual para uma placa nova. Se o orçamento for apertado, a RTX 4060 Ti de 8GB ainda é sólida para modelos 7B. Evite a 4060/5060 base (8GB) e a 4070 (12GB) se planeja rodar modelos 13B+ — pouca margem de VRAM.
Posso usar uma AMD RX 7900 XT ou RX 7900 XTX no lugar?
Sim, mas o suporte a drivers da AMD é mais fraco que NVIDIA + CUDA. A configuração de HIP/ROCm exige mais esforço. A RTX é mais segura para iniciantes.
12 GB de VRAM é suficiente para modelos de 13B?
Por pouco, em quantização Q4. Q5 ou Q8 causarão erros de OOM. Se você quer conforto com 13B, mire em 16 GB.
Devo comprar uma GPU empresarial usada como a RTX A4000?
Sim, se disponível. 16 GB de VRAM, refrigeração de nível profissional, normalmente US$ 180-230 usada. Um pouco mais lenta que a RTX 3060, mas a folga de VRAM vale a pena.
Qual potência de fonte devo comprar com uma GPU de US$ 250?
650W, 80+ Gold no mínimo. Uma GPU de US$ 250 + CPU + placa-mãe não ultrapassa 400W de consumo, mas você quer margem para picos.
Posso rodar o Ollama com uma GPU econômica de US$ 200?
Sim. O Ollama é leve. Uma RTX 3060 de 4 anos com Ollama roda o Qwen3 14B a 9-12 tok/s ou o Qwen3 8B a 16-20 tok/s -- totalmente utilizável para chat interativo e assistência de código.
Posso rodar o Llama 4 Scout numa RTX 3060 12 GB?
Normalmente não. O Llama 4 Scout é um MoE de 17B ativos / 109B no total que precisa de ~55 GB de VRAM em Q4 -- muito além de uma placa de 12 GB. Só cabe em 24 GB com uma quantização extrema de 1,78 bit (~20 tok/s). Numa RTX 3060 12GB, rode modelos densos: `ollama pull qwen3:14b` (melhor qualidade que cabe), Qwen3 8B ou Gemma 4 E12B. O Scout é uma opção de contexto longo (10M tokens) / multimodal grande para máquinas com 48 GB+.
Qual é a melhor GPU econômica por menos de US$ 200?
RTX 2080 usada (8GB, ~US$ 150) ou RTX A2000 (12GB, ~US$ 180-200). Ambas rodam modelos 7B em Q4. A A2000 é preferível pela folga de 12GB de VRAM.
Como testo uma GPU usada em busca de defeitos de VRAM antes de comprar?
Rode testes de estresse de VRAM: gpu-burn (Linux), teste de estresse de memória do HWiNFO64 (Windows), ou carregue um modelo grande no Ollama e observe erros de OOM. Teste antes de devolver a placa.
Posso fazer upgrade da minha GPU atual para rodar modelos maiores depois?
Sim, upgrades de GPU são simples em PCs de mesa. Comece com a RTX 3060 12GB e depois faça upgrade para a RTX 4090 ou 5090. O slot PCIe é retrocompatível entre gerações.
Qual é a melhor GPU NVIDIA econômica para inferência de LLM local?
RTX 4060 Ti (8 GB, ~US$ 250) para modelos 7B, ou RTX 4070 Super (12 GB, ~US$ 350-400) para modelos 13B. Usada: a RTX 3060 12GB (US$ 200–250) roda modelos 7-13B sem esforço em Q4. Melhor valor: RTX 3060 12GB usada, ou RTX 4070 Super nova.
Como a AMD 6800 XT se compara à RTX 4070 para inferência de IA?
A AMD RX 6800 XT (16 GB) supera a RTX 4070 (12 GB) em VRAM e desempenho em jogos, mas fica atrás na velocidade de inferência de LLM (15-20% mais lenta). A configuração do driver ROCm para llama.cpp também é mais complexa que CUDA. Para trabalho puro com LLM, a RTX 4070 é mais fácil; para jogos + LLMs, a 6800 XT oferece melhor custo-benefício.
Qual é a GPU com melhor preço por GB de VRAM para LLMs locais em 2026?
RTX 3090 usada (24 GB, ~US$ 450-500) = US$ 18-20 por GB. RTX 3060 usada (12 GB, ~US$ 150-180) = US$ 12-15 por GB. RTX 4070 Ti (12 GB, ~US$ 600 nova) = US$ 50 por GB. Melhor valor: RTX 3060 12GB usada. Mais capacidade por dólar: RTX 3090 24GB usada. Equilíbrio entre preço e potência: RTX 4070 nova.
A RTX 3060 12 GB funciona bem para conteúdo em português?
Sim. A GPU apenas executa o modelo -- a qualidade do idioma depende do modelo escolhido. Qwen3 8B ou Qwen3 14B (ambos com excelente suporte em português) rodam bem na RTX 3060 12 GB.
Onde comprar uma RTX 3060 12 GB usada no Brasil?
Mercado Livre, OLX e grupos de Facebook são as melhores fontes para GPUs usadas no Brasil. Espere pagar R$ 900-1.200 por uma RTX 3060 12 GB usada em bom estado. Verifique a procedência e teste antes de comprar.
Leitura relacionada
- Mini PCs AMD Ryzen AI Max+ (2026) — Alternativa a GPUs dedicadas: iGPU + NPU de 50 TOPS a US$ 1.200–2.500.
- Quanta VRAM para LLMs locais
- RTX 5090 vs RTX 4090
- GPUs usadas para LLMs locais
- Melhores GPUs para LLMs locais
- Calculadora de VRAM
- Laptop vs Desktop para LLMs locais — Comparação completa de plataformas: GPU desktop vs MacBook para LLMs locais.
- Prompt Engineering para LLMs locais — otimize prompts para modelos rodando em hardware econômico.
- Chain-of-Thought Prompting — melhora significativamente a qualidade de saída do DeepSeek-R1.
- Mac Mini M5 como servidor de IA local — Alternativa econômica a builds com GPU: IA always-on a US$ 599 de hardware + US$ 35/ano de eletricidade.
- Apple Silicon M5 para LLMs locais — Guia completo M5 Pro/Max: benchmarks, configurações de Mac, níveis de memória e qual Mac comprar para inferência local.
- Apple Silicon vs GPU NVIDIA para LLMs locais — Comparação completa de custo e desempenho: quando um Mac supera uma GPU econômica.
- Melhores modelos para Apple Silicon 2026 — Recomendações de modelos para níveis de memória unificada de 16GB–128GB.
- Melhor GPU custo-benefício no Japão — guia de preços em lojas de Akihabara, Mercari e Yahoo Auctions
- Melhor GPU custo-benefício nos Emirados Árabes Unidos/Golfo — guia de preços da Sharaf DG, noon.com, Amazon.ae e dubizzle
Fontes
- Meta AI. (2025). "Llama 4 Model Card." — Arquitetura MoE do Scout, requisitos de VRAM
- Qwen Team. (2026). "Qwen3 Technical Report." — Especificações do Qwen3 8B
- Banco de dados de GPU TechPowerUp: especificações e consumo de energia da RTX 3060 / RTX 4060 Ti / RTX 4070 Super
- Matriz de capacidade CUDA da NVIDIA: largura de banda de memória de GPU e throughput teórico para cargas de inferência
- Requisitos de modelos do Ollama: recomendações de VRAM para níveis de quantização do Llama 4 Scout, Qwen3 e Mistral Small