Key Takeaways
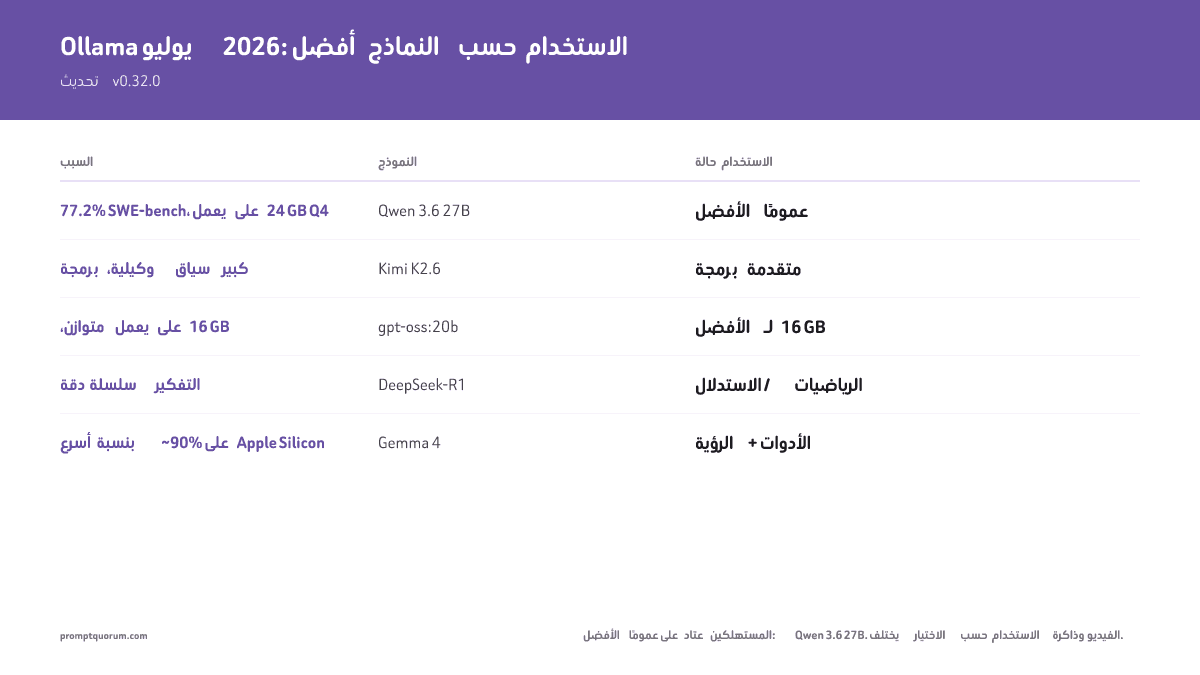
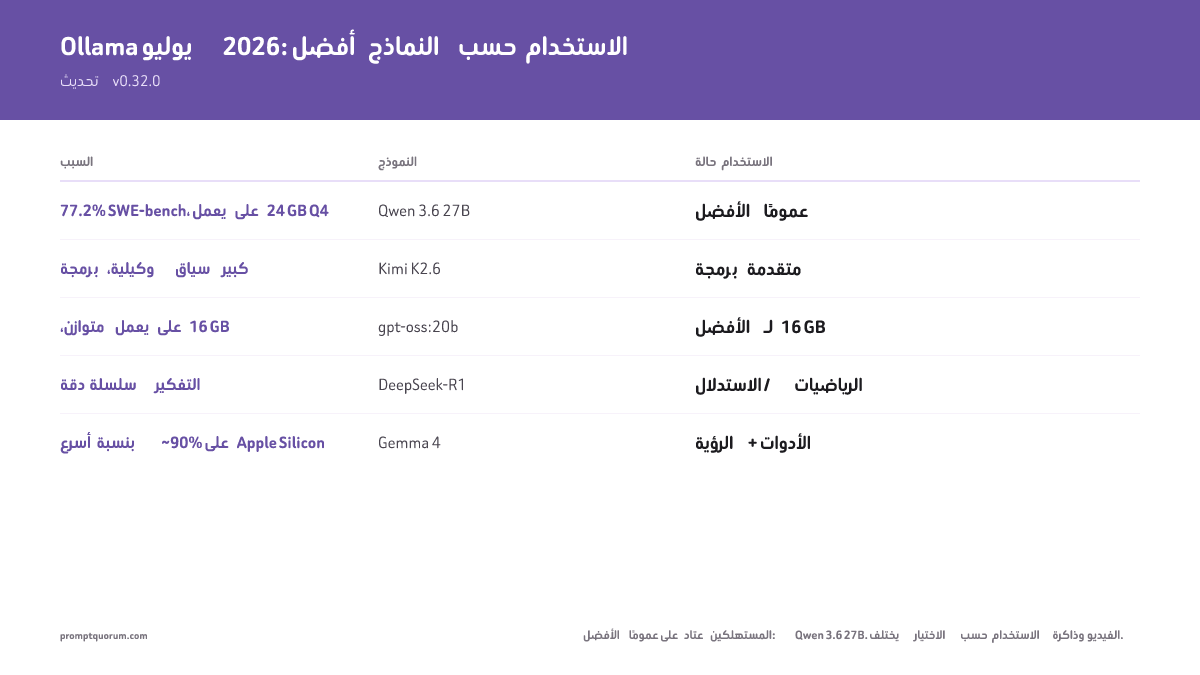
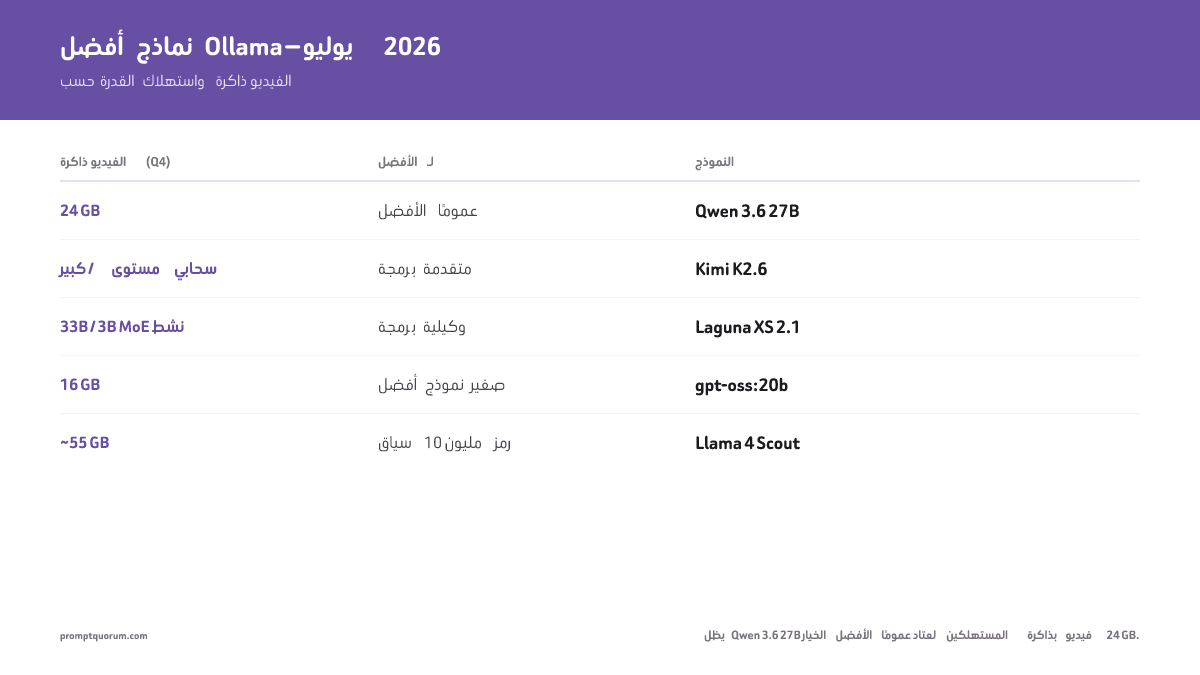
- أفضل خيار عام على عتاد المستهلك: Qwen 3.6 27B (77.2% SWE-bench، يلائم 24 GB عند Q4). متوازن لكل الاستخدامات: qwen3:30b.
- الأكثر تنزيلاً: Llama 3.2 3B (للدروس) وعائلة Llama -- أوسع دعم للأدوات.
- أفضل استدلال: DeepSeek-R1 (سلسلة التفكير) وgpt-oss:20b (استدلال قابل للضبط، بمستوى ~o3-mini).
- أفضل برمجة: Kimi K2.6 (MoE متقدم) أو Laguna XS 2.1 (وكيلة، طويلة الأفق)، Qwen 3.6 27B (أفضل نموذج كثيف)، Devstral Small 24B (أفضل برمجة وكيلة بحجم 24B)، qwen3-coder:30b (الإكمال) -- أعلى المعايير في أحجامها.
- أفضل نموذج صغير / 16 GB: gpt-oss:20b. أفضل رؤية/متعدد الوسائط: Gemma 4 (E4B+). أفضل سياق طويل (10M) / متعدد وسائط كبير: Llama 4 Scout (~55 GB). أفضل نموذج غير خاضع للرقابة/عام الأغراض: Dolphin 3.0.
- تضم مكتبة Ollama مئات النماذج المنسّقة (وآلاف أخرى عبر ملفات Modelfile مخصّصة). جميعها متاحة عبر `ollama pull <name>`.
الجديد في Ollama — تحديث يوليو 2026
إصدار Ollama الحالي: v0.32.0 (صدر في 11 يوليو 2026). هذا هو أحدث إصدار مستقر، ومتاح عبر ollama.com/download. حدِّث باستخدام `curl https://ollama.ai/install.sh | sh` (على macOS: `brew upgrade ollama`)، ثم تأكّد عبر `ollama --version`.
ما الذي تغيّر في سلسلة v0.31–v0.32 (أواخر يونيو–يوليو 2026): أضاف v0.30.11 (25 يونيو) التثبيت التلقائي لـ Claude Code وopencode، وأصلح تصنيف بطاقات GPU الهجينة في Windows. أصلح v0.30.12 (29 يونيو) اكتشاف استدعاء الأدوات داخل سلاسل JSON. قدّم v0.31.1 (30 يونيو) نواة ضرب مصفوفات MLX جديدة تجعل Gemma 4 يولّد التوكنات أسرع بنسبة تقارب 90% على Apple Silicon عبر التنبؤ متعدد التوكن. مكّن v0.31.2 (6 يوليو) خاصية flash attention على بطاقات NVIDIA الأقدم، وأصلح المخرجات المنظّمة لنماذج الاستدلال. قدّم v0.32.0 (11 يوليو) تجربة وكيل تفاعلية بعنوان "Chat, Code & Work"، وأعاد تسمية تكامل تطبيق Codex إلى ChatGPT. الملاحظات الكاملة: github.com/ollama/ollama/releases.
أحدث النماذج المضافة منذ آخر تحديث (أواخر يونيو–يوليو 2026):
- Laguna XS 2.1 (من Poolside، 2 يوليو 2026) — MoE بحجم 33B إجمالي/3B نشط، مصمّم للبرمجة الوكيلة والعمل المحلي طويل الأفق: التخطيط وكتابة الشيفرة وتشغيل الاختبارات والتكرار. سياق 256K، رخصة OpenMDW-1.1. SWE-bench Verified 70.9%، SWE-bench Multilingual 63.1%. للتنزيل: `ollama pull laguna-xs-2.1`
- Kimi K2.7 Code (Moonshot AI، يونيو 2026) — نموذج وكيلي مخصص للبرمجة مبني على Kimi K2.6، موجّه تحديدًا لجلسات البرمجة طويلة الأفق. للتنزيل: `ollama pull kimi-k2.7-code`
- DeepSeek V4 Pro (DeepSeek، 23 أبريل 2026) — متخصص في البرمجة الخوارزمية، 93.5% LiveCodeBench، رخصة MIT. النسخة الاقتصادية DeepSeek V4 Flash للعتاد الأخف. للتنزيل: `ollama pull deepseek-v4-pro`
- Kimi K2.6 (Moonshot AI، 20 أبريل 2026) — نموذج برمجة متقدم، SWE-Bench Pro 58.6، SWE-bench Verified 80.2%. بنية MoE (32B نشط / 1T إجمالي). رخصة Modified MIT. للتنزيل: `ollama pull kimi-k2.6`
- Qwen 3.6 27B (Alibaba، 16 أبريل 2026) — أفضل خيار عام على عتاد المستهلك، 77.2% SWE-bench، رخصة Apache 2.0، يلائم 24 GB عند Q4. وكذلك Qwen3.6-35B-A3B (MoE، 73.4 SWE-bench). للتنزيل: `ollama pull qwen3.6:27b`
- GLM-5.1 (Z.ai، 7 أبريل 2026) — MoE بحجم 744B / 40B نشط، رخصة MIT، SWE-Bench Pro 58.4. رائد في توليد الشيفرة المنظّمة. للتنزيل: `ollama pull glm-5.1`
- gpt-oss (OpenAI، 2026) — MoE مفتوح الأوزان: gpt-oss:20b (21B إجمالي / 3.6B نشط، يعمل في 16 GB، بمستوى ~o3-mini، استدلال قابل للضبط) وgpt-oss:120b (80 GB). للتنزيل: `ollama pull gpt-oss:20b`
- Gemma 4 (Google، 2 أبريل 2026) — أحجام متعددة الوسائط E2B / E4B / E12B (26B MoE) / E27B (31B كثيف)، جميعها تدعم الرؤية واستدعاء الأدوات. أصبح الآن أسرع بنحو 90% على Apple Silicon (تحديث MLX يوليو 2026). يعمل E4B في ~6 GB VRAM. للتنزيل: `ollama pull gemma4:e4b`
# Update Ollama to the latest version (v0.32.0)
curl https://ollama.ai/install.sh | sh
# Or on Mac: brew upgrade ollama
# Check your current version
ollama --version # outputs: ollama version 0.32.0
# Pull the newest July 2026 models
ollama pull laguna-xs-2.1
ollama pull kimi-k2.7-code
ollama pull kimi-k2.6ما النماذج الأكثر شيوعًا على Ollama في 2026؟
تُقاس الشعبية على Ollama بعدد التنزيلات الظاهر في صفحة مكتبة كل نموذج. اعتبارًا من يوليو 2026، لا تزال النماذج الأكثر تنزيلاً تهيمن عليها عائلة Llama من Meta -- إذ يُعدّ Llama 3.2 3B الأكثر تنزيلاً عمومًا، ويعود ذلك إلى حدٍّ كبير لاستخدامه كنموذج اختبار أول للتثبيت. غير أن Llama 4 Scout صعد بسرعة منذ إطلاقه في أبريل 2026.
تُعدّ Qwen3 عائلة النماذج الأسرع نموًّا في مكتبة Ollama، حيث يحلّ Qwen3 والمتغيّر الكثيف الجديد Qwen 3.6 محل Qwen3 بسرعة. وشهد DeepSeek-R1 قفزات كبيرة بعد إطلاقه، ولا يزال من الأكثر تنزيلاً لمهام الاستدلال.
أطلقت Meta نموذج Llama 4 في أبريل 2026 بمتغيّري Scout (17B نشط، 109B إجمالي، MoE) وMaverick (17B نشط، 400B إجمالي). أصبح Llama 4 Scout الآن مستقرًا في مكتبة Ollama (`ollama pull llama4:scout`). تستخدم عائلة Llama 4 بنية مزيج الخبراء (MoE) — إذ يُفعَّل 17B معامل فقط لكل توكن، لكن مع 109B معامل إجمالي يحتاج Scout إلى ~55 GB VRAM عند Q4 (ويلائم 24 GB فقط عند 1.78 بت، ~20 tok/s). ميزتا Scout البارزتان هما نافذة سياقه البالغة 10M توكن ودخله متعدد الوسائط، وليس ملاءمته لعتاد المستهلك. للإعدادات الخفيفة (8 GB RAM)، يبقى Llama 3.2 3B أسهل نموذج أول. توسّعت منظومة Ollama بشكل ملحوظ في أبريل 2026. حقق Kimi K2.6 (Moonshot AI، رخصة Modified MIT، 32B نشط / 1T إجمالي MoE) نتيجة SWE-Bench Pro 58.6، متعادلاً مع GPT-5.5. وLaguna XS 2.1 (من Poolside) هو أحدث منافس للبرمجة الوكيلة، مصمّم خصيصًا لجلسات البرمجة المحلية طويلة الأفق. وحقق Qwen 3.6 27B نتيجة 77.2% SWE-bench كأفضل نموذج عام على عتاد المستهلك (يلائم 24 GB عند Q4). ويعمل gpt-oss:20b مفتوح الأوزان من OpenAI (21B إجمالي / 3.6B نشط MoE) في 16 GB بمستوى ~o3-mini مع استدلال قابل للضبط. تضم مكتبة Ollama الآن مئات النماذج المنسّقة، وتُعدّ Laguna XS 2.1 وKimi K2.7 Code أحدث الإضافات منذ تحديث يونيو.
أي نماذج Ollama تناسب حالة استخدامك على نحوٍ أفضل؟
تعتمد جودة مخرجات النموذج إلى حدٍّ كبير على طريقة المطالبة. للاطلاع على تقنيات منظّمة تعمل عبر جميع النماذج المحلية — بما في ذلك سلسلة التفكير والأمثلة القليلة وتنسيق المخرجات — راجع دليل هندسة المطالبات. في مهام الاستدلال، تحسّن مطالبة سلسلة التفكير جودة مخرجات DeepSeek-R1 وQwen3 بشكل كبير. لفهم مقايضات التكميم لهذه النماذج، راجع دليل التكميم ←. ولتحديد مقدار VRAM الذي يحتاجه كل نموذج، راجع دليل متطلبات VRAM ←. لتدفقات عمل الوكلاء مع Gemma 4، راجع شجرة التفكير وReAct. ولمتطلبات العتاد اللازمة لتشغيل هذه النماذج، راجع دليل العتاد ←. وبمجرد ربط نموذج يدعم استدعاء الأدوات من هذه القائمة في حلقة متعددة الخطوات مع وصول للملفات وقواعد البيانات، راجع وكلاء الذكاء الاصطناعي المحليون مع MCP لنمط التنسيق مفتوح المصدر.
- الدردشة العامة (مبتدئ): `ollama run llama3.2:3b` -- أكثر النماذج توثيقًا، وأفضل نموذج أول مدعوم.
- الدردشة العامة (أفضل خيار عام): `ollama run qwen3.6:27b` -- 77.2% SWE-bench، أفضل خيار عام على عتاد المستهلك، يلائم 24 GB عند Q4. متوازن لكل الاستخدامات: `ollama run qwen3:30b`. للأجهزة بسعة 8 GB، التزم بـ `ollama run llama3.2:3b`.
- السياق الطويل / متعدد الوسائط: `ollama run llama4:scout` -- سياق 10M توكن + متعدد الوسائط، MoE (17B نشط/109B إجمالي). يحتاج ~55 GB VRAM عند Q4 (يلائم 24 GB فقط عند 1.78 بت، ~20 tok/s).
- أفضل نموذج صغير / 16 GB: `ollama run gpt-oss:20b` -- 21B إجمالي / 3.6B نشط MoE، بمستوى ~o3-mini، استدلال قابل للضبط. أكبر: `ollama run gpt-oss:120b` (80 GB).
- البرمجة على 8 GB: `ollama run qwen3:8b` -- أفضل نموذج برمجة محلي لأجهزة 8 GB VRAM. 76% HumanEval، يستهلك 5 GB، متعدد اللغات.
- الاستدلال العام على 8 GB (لغير البرمجة): `ollama run mistral:7b` -- أسرع نموذج عام الأغراض عند 8 GB، 40-60 tok/sec.
- البرمجة (أفضل وكيل، 24B): `ollama run devstral-small:24b` -- أفضل نموذج برمجة وكيل (تعديلات متعددة الملفات، التنقيح). 16 GB RAM. من Mistral AI.
- البرمجة (أفضل كثيف، 27B): `ollama run qwen3.6:27b` -- 77.2% SWE-bench. أفضل نموذج برمجة كثيف. 22 GB VRAM.
- البرمجة (MoE متقدم): `ollama run kimi-k2.6` -- SWE-Bench Pro 58.6 (يتعادل مع GPT-5.5)، الطبقة العليا. MoE (32B نشط/1T إجمالي). رخصة Modified MIT. يحتاج تكميمًا لعتاد المستهلك.
- البرمجة (وكيلة، طويلة الأفق): `ollama run laguna-xs-2.1` -- من Poolside، MoE بحجم 33B إجمالي/3B نشط، SWE-bench Verified 70.9%، سياق 256K. مصمّم لحلقات تخطيط → برمجة → اختبار → تكرار متعددة الخطوات. رخصة OpenMDW-1.1.
- مهام الوكلاء واستدعاء الأدوات: `ollama run gemma4:e4b` -- صدر في 2 أبريل 2026. استدعاء أدوات مدمج + دعم الرؤية. يُوصى به للوكلاء المحليين واستدعاء الدوال والمخرجات المنظّمة. 6 GB RAM.
- الاستدلال والرياضيات: `ollama run deepseek-r1:7b` -- نموذج سلسلة التفكير، أفضل أداء رياضي محلي عند 7B.
- متعدد اللغات: `ollama run qwen3:7b` -- أكثر من 29 لغة أصلية، أقوى دعم لغير الإنجليزية، 76% HumanEval.
- غير خاضع للرقابة / عام الأغراض: `ollama run dolphin3` -- Dolphin 3.0 (من Cognitive Computations، مبني على Llama 3.1)، بلا تصفية محتوى مدمجة، للدردشة العامة والبرمجة والمهام الوكيلة.
- فهم الصور: `ollama run gemma4:e4b` -- رؤية + استدعاء أدوات. أو `ollama run llama3.2-vision:11b` للرؤية المخصّصة.
- سريع وخفيف: `ollama run gemma2:2b` -- أسرع استدلال على المعالج، 1.7 GB RAM.
- جودة عالية (16 GB RAM): `ollama run mistral-small3.1` -- جودة تقارب فئة 70B عند 14 GB RAM.
- توليد المتجهات (Embeddings): `ollama run nomic-embed-text` -- نموذج تضمين بـ 137M معامل لخطوط أنابيب RAG.
- أسئلة وأجوبة المستندات (RAG): `ollama run llama3.2` مع ميزة RAG في Open WebUI -- أفضل تركيبة مدعومة.
- أتمتة المنزل / الذكاء بكلمة التنبيه: `ollama run phi4-mini` — يعالج Phi-4 Mini (3.8B، ~3 GB VRAM) استعلامات Home Assistant الصوتية بسرعة 20-25 tok/sec على حاسوب مصغّر دون GPU منفصل. راجع دليل تكامل Home Assistant + Ollama ←.
نماذج Ollama الجديدة — إصدارات يوليو 2026
هذه أحدث النماذج في مكتبة Ollama اعتبارًا من يوليو 2026، الأحدث أولاً. تأكّد من التوفّر عبر `ollama pull <model>` قبل بناء تدفقات العمل — تظهر النماذج الجديدة على ollama.com/library خلال أيام من الإطلاق.
| Model | Released | Best For | Ollama Command |
|---|---|---|---|
| laguna-xs-2.1 | 2 يوليو 2026 | Poolside — برمجة وكيلة، MoE بحجم 33B/3B نشط، SWE-bench Verified 70.9%، سياق 256K | ollama run laguna-xs-2.1 |
| kimi-k2.7-code | يونيو 2026 | Moonshot AI — نموذج وكيلي مخصص للبرمجة مبني على Kimi K2.6 | ollama run kimi-k2.7-code |
| deepseek-v4-pro | 23 أبريل 2026 | برمجة خوارزمية، 93.5% LiveCodeBench، MIT | ollama run deepseek-v4-pro |
| kimi-k2.6 | 20 أبريل 2026 | برمجة متقدمة (SWE-Bench Pro 58.6)، MoE (32B/1T)، Modified MIT | ollama run kimi-k2.6 |
| qwen3.6:27b | 16 أبريل 2026 | أفضل خيار عام على عتاد المستهلك، 77.2% SWE-bench، يلائم 24 GB Q4 | ollama run qwen3.6:27b |
| qwen3:30b | 2026 | متوازن لكل الاستخدامات؛ qwen3-coder:30b لإكمال الشيفرة | ollama run qwen3:30b |
| gpt-oss:20b | 2026 | أفضل نموذج صغير / 16 GB، ~o3-mini، استدلال قابل للضبط (وأيضًا gpt-oss:120b) | ollama run gpt-oss:20b |
| glm-5.1 | 7 أبريل 2026 | Z.ai، 744B/40B نشط MoE، MIT، SWE-Bench Pro 58.4 | ollama run glm-5.1 |
| gemma4:e4b | 2 أبريل 2026 | رؤية + استدعاء أدوات (E2B/E4B/E12B/E27B) | ollama run gemma4:e4b |
| deepseek-v4-flash | أبريل/مايو 2026 | برمجة اقتصادية (78/100 واقعيًا) | ollama run deepseek-v4-flash |
| qwen3:7b | 2026 | HumanEval 76% عند 7B، متعدد اللغات | ollama run qwen3:7b |
ما هو DeepSeek-R1 ولماذا يختلف؟
DeepSeek-R1 هو نموذج استدلال -- وعلى عكس نماذج الدردشة القياسية التي تولّد الإجابات مباشرة، يولّد DeepSeek-R1 استدلال سلسلة تفكير صريح قبل إجابته النهائية. وهذا يحسّن الأداء بشكل كبير في الرياضيات وألغاز المنطق وحل المشكلات خطوة بخطوة.
يحقق DeepSeek-R1 7B نسبة 52% في MATH (رياضيات المسابقات) مقابل 28% لـ Mistral Small بالحجم نفسه. وهو أبطأ من النماذج القياسية (توكنات أكثر لكل رد) لكنه أكثر دقة بكثير في المهام التي يهمّ فيها الاستدلال.
# Pull and run DeepSeek-R1
ollama run deepseek-r1:7b
# Larger variants for better quality
ollama run deepseek-r1:14b # 10 GB RAM
ollama run deepseek-r1:32b # 20 GB RAM
أي نماذج Ollama تدعم إدخال الصور؟
اعتبارًا من يوليو 2026، تدعم النماذج التالية على Ollama إدخال الصور (متعدد الوسائط): يدعم Gemma 4 الرؤية واستدعاء الأدوات معًا — وهو فريد بين نماذج الرؤية على Ollama، وأصبح الآن يعمل أسرع بنحو 90% على Apple Silicon بعد تحديث MLX في يوليو.
| Model | RAM | Image Support | Ollama Command |
|---|---|---|---|
| llama3.2-vision:11b | ~8 GB | نعم | ollama run llama3.2-vision:11b |
| llama3.2-vision:90b | ~55 GB | نعم | ollama run llama3.2-vision:90b |
| gemma3:9b (vision) | ~6 GB | نعم | ollama run gemma3:9b |
| minicpm-v:8b | ~5.5 GB | نعم | ollama run minicpm-v |
| gemma4:e4b | ~6 GB | نعم + استدعاء أدوات ✓ | ollama run gemma4:e4b |

ما هي أفضل 10 نماذج مفتوحة المصدر على Ollama؟
لا تزال أعداد التنزيلات تميل لصالح Llama 3.x بسبب شيوع الدروس. للمشاريع الجديدة في يوليو 2026، يُفضَّل Qwen 3.6 27B (أفضل خيار عام على عتاد المستهلك) وKimi K2.6 أو Laguna XS 2.1 (البرمجة) وgpt-oss:20b وqwen3:30b.
| # | Model | Best For | RAM | HumanEval |
|---|---|---|---|---|
| 1 | Qwen 3.6 27B | أفضل خيار عام على عتاد المستهلك | 24 GB (Q4) | 77.2% SWE-bench |
| 2 | Kimi K2.6 | برمجة متقدمة، MoE (32B/1T)، Modified MIT | مكمّم | 58.6 SWE-Bench Pro |
| 3 | gpt-oss:20b | أفضل نموذج صغير / 16 GB، استدلال قابل للضبط | 16 GB | ~o3-mini |
| 4 | qwen3:30b | متوازن لكل الاستخدامات؛ qwen3-coder:30b للبرمجة | ~18 GB | قوي |
| 5 | Laguna XS 2.1 | برمجة وكيلة، طويلة الأفق (تخطيط/برمجة/اختبار/تكرار) | مكمّم | 70.9% SWE-bench Verified |
| 6 | Devstral Small 24B | برمجة وكيلة (متعددة الملفات) | 16 GB | 80% |
| 7 | deepseek-r1:7b | استدلال، رياضيات | 5 GB | — |
| 8 | gemma4:e4b | رؤية + استدعاء أدوات (متعدد الوسائط) | ~6 GB | — |
| 9 | Llama 4 Scout | سياق طويل 10M + متعدد الوسائط، MoE | ~55 GB (Q4) | 85% |
| 10 | Llama 3.2 3B | النموذج الأول، الدردشة العامة | 2.5 GB | 60% |
كيف تتصفّح مكتبة نماذج Ollama؟
هناك طريقتان للعمل مع نماذج Ollama. تبديل النماذج المثبّتة: في تطبيق Ollama على Mac، انقر زر القائمة المنسدلة للنماذج أسفل حقل إدخال الدردشة (يعرض اسم النموذج الحالي، مثل "gemma3:1b") للتبديل بين أي نموذج مثبّت محليًا. العثور على نماذج جديدة وتنزيلها: زُر ollama.com/library لتصفح مئات النماذج المنسّقة حسب الفئة، ثم استخدم أوامر CLI أدناه لتنزيل النماذج وإدارتها.
# List all locally downloaded models
ollama list
# Search for a model and pull it
ollama pull qwen2.5-coder:32b
# See all available tags for a model
ollama show qwen2.5
# Remove a model to free disk space
ollama rm llama3.2:3bنماذج Ollama مفتوحة المصدر: السياق الإقليمي
الاتحاد الأوروبي / GDPR + الامتثال للرخص. بالنسبة للمؤسسات الأوروبية التي تنشر نماذج Ollama في الإنتاج، يهمّ اختيار الرخصة بقدر ما يهمّ الأداء. Apache 2.0 (مفتوح بالكامل، الاستخدام التجاري مسموح): Mistral Small وMistral Small 3.1 وQwen3 7B وQwen 3.6 27B وDevstral Small 24B وGemma 2 2B. رخصة Meta Llama Community (الاستخدام التجاري مقيّد فوق 700M مستخدم نشط شهريًا): Llama 3.3 8B وLlama 3.2 3B وLlama 3.2 Vision 11B. رخصة MIT (الاستخدام التجاري مسموح): DeepSeek-R1 7B وDeepSeek-R1 14B. Modified MIT (الاستخدام التجاري مسموح مع شرط الإسناد): Kimi K2.6. للمؤسسات الأوروبية في القطاعات المنظّمة، تُعدّ نماذج Mistral (فرنسا، Apache 2.0) أو Devstral Small 24B (أفضل برمجة وكيلة) الخيار الافتراضي الموصى به -- منشأ أوروبي، ورخصة نظيفة، ودون قيود على النشر التجاري. للامتثال لـ GDPR: تعمل جميع النماذج محليًا بالكامل عبر Ollama، أي لا تُرسَل أي بيانات شخصية إلى خوادم خارجية بصرف النظر عن اختيار النموذج.
اليابان (METI). لعمليات نشر Ollama في الشركات اليابانية، تُعدّ عائلة Qwen3 / Qwen 3.6 الموصى بها -- إذ تعالج التجزئة اللغوية اليابانية الأصلية النص الياباني بكفاءة أعلى بنسبة 30-40% من حيث التوكنات مقارنةً بـ Llama أو Mistral، مما يقلّل مباشرةً زمن الاستدلال ومتطلبات مخبأ KV. لتدفقات عمل البرمجة باليابانية: يعالج Qwen 3.6 27B (77.2% SWE-bench) تعليقات الشيفرة اليابانية أصليًا وهو أفضل نموذج برمجة كثيف في 2026. تتطلب وثائق حوكمة الذكاء الاصطناعي لـ METI تدوين إصدار النموذج الدقيق. استخدم `ollama show <model>` للحصول على المواصفات الكاملة للنموذج بما في ذلك عدد المعاملات ومستوى التكميم وطول السياق لسجلات الامتثال.
الصين. بموجب تدابير الذكاء الاصطناعي التوليدي الصادرة عن CAC (2023)، يجب على المؤسسات التي تقدّم خدمات ذكاء اصطناعي للمستخدمين النهائيين تسجيل النماذج المستخدمة. تُعدّ Qwen3 / Qwen 3.6 (Alibaba، Apache 2.0) الخيار الموصى به لعمليات نشر Ollama في الشركات الصينية -- منشأ نموذج صيني، ورخصة Apache 2.0، وأفضل أداء في المهام باللغة الصينية، وأعلى المعايير. ويتوفر أيضًا Kimi K2.6 (Moonshot AI، رخصة Modified MIT، 32B نشط/1T إجمالي MoE) كخيار برمجة من الطبقة العليا بمنشأ صيني. أوامر التنزيل: `ollama run qwen3.6:27b` لأفضل جودة، و`ollama run qwen3:7b` للسرعة. ويناسب DeepSeek-R1 (DeepSeek، رخصة MIT) مهام الاستدلال. بالنسبة للبيانات المعالَجة محليًا عبر Ollama، لا تنطبق متطلبات نقل البيانات عبر الحدود في قانون PIPL الصيني -- إذ يبقى الاستدلال محليًا.
ما هي الأخطاء الشائعة عند اختيار نماذج Ollama؟
تنزيل وسم النموذج الأكبر افتراضيًا دون التحقق من RAM
تشغيل `ollama pull llama3.3` دون تحديد وسم ينزّل المتغيّر الافتراضي، وهو عادةً أكبر تكميم قياسي. على جهاز بسعة 8 GB RAM، سيؤدي تنزيل llama3.3 (70B بحجم ~40 GB) إلى الفشل أو استخدام مفرط للتبديل (swap). حدّد المتغيّر دائمًا: `ollama pull llama3.2:3b` للأجهزة بسعة 8 GB.
استخدام نموذج عام مع وجود نموذج متخصص للمهمة
لمهام البرمجة، يحقق `qwen2.5-coder:7b` نسبة 72% HumanEval بينما يحقق العام `qwen2.5:7b` أيضًا 72% -- لكن `qwen2.5-coder` يتضمن دعم FIM لإكمال الشيفرة. للاستدلال/الرياضيات، يحقق `deepseek-r1:7b` نسبة 52% MATH مقابل 28% لـ `mistral:7b`. توجد النماذج المتخصصة للمهام في مكتبة Ollama لسبب وجيه.
عدم التحقق من توفّر النموذج قبل بناء تدفق العمل
تتغير مكتبة Ollama بمرور الوقت -- تُضاف النماذج وتُزال أحيانًا. قبل بناء خط إنتاج حول نموذج معيّن، تأكّد من وجوده في المكتبة (`ollama list` محليًا، أو راجع ollama.com/library). ثبّت إصدارات نماذج محددة في تدفقات عمل الإنتاج: `ollama pull llama3.1:8b-instruct-q4_K_M`.
عدم تحديد وسم تكميم للنماذج الكبيرة
تشغيل `ollama pull qwen2.5-coder:32b` دون لاحقة تكميم ينزّل المتغيّر الافتراضي -- الذي قد يكون أكبر مما يستوعبه VRAM لديك. لـ 16 GB VRAM، نزّل متغيّر Q4_K_M الصريح: `ollama pull qwen2.5-coder:32b-instruct-q4_K_M`. شغّل `ollama show <model>` بعد التنزيل للتأكد من تطابق متطلبات VRAM مع عتادك.
توقّع أن يكون DeepSeek-R1 بسرعة نماذج الدردشة القياسية
يولّد DeepSeek-R1 توكنات استدلال سلسلة تفكير صريحة قبل إجابته النهائية -- وهذا سبب تفوّقه على النماذج القياسية في الرياضيات والمنطق، لكنه ينتج توكنات أكثر بـ 3-5 أضعاف لكل رد. للدردشة السريعة أو الإجابات بسطر واحد، استخدم `llama3.1:8b`. احتفظ بـ DeepSeek-R1 للمهام التي تهمّ فيها دقة الاستدلال أكثر من السرعة.
الخطوات التالية
- أفضل نماذج LLM المحلية للبرمجة — أفضل نموذج Ollama مخصص للبرمجة →
- أفضل نماذج LLM بالمعالج فقط — ليس لديك GPU؟ ابدأ هنا →
- دليل أجهزة LLM المحلي 2026 — هل جهازك يستطيع تشغيل هذه النماذج؟ →
أسئلة شائعة حول النماذج مفتوحة المصدر على Ollama
كم عدد النماذج في مكتبة Ollama؟
تضم مكتبة Ollama مئات النماذج المنسّقة بدعم رسمي، وينمو العدد أسبوعيًا مع صدور إصدارات جديدة مفتوحة الأوزان. وتستضيف Hugging Face آلاف نماذج GGUF الإضافية التي يمكن تحميلها عبر Ollama باستخدام ملفات Modelfile مخصّصة.
ما هو الاسم الرسمي للشركة التي تقف وراء Ollama؟
الشركة هي Ollama Inc.، وهي شركة ناشئة ممولة بجولة تمويل من فئة Series B ومقرها Palo Alto، كاليفورنيا، أسسها عام 2023 كل من Jeffrey Morgan وMichael Chiang. يشير اسم "Ollama" إلى كل من الشركة وأداة CLI/محرك تشغيل النماذج الذي تصدره.
هل يمكنني استخدام نماذج Hugging Face مباشرةً في Ollama؟
نعم. نزّل ملف GGUF من Hugging Face وأنشئ Modelfile: `FROM ./model.gguf`. ثم شغّل `ollama create mymodel -f Modelfile`. يعمل هذا مع أي ملف GGUF بما في ذلك النماذج المضبوطة والنماذج غير الموجودة في مكتبة Ollama الرسمية.
أي نموذج Ollama أفضل لبناء روبوت دردشة محلي؟
لروبوت دردشة محلي عام الأغراض: `qwen3.6:27b` (أفضل خيار عام على عتاد المستهلك، يلائم 24 GB عند Q4)، أو `llama3.2:3b` على 8 GB RAM (أسهل نقطة بداية). للأجهزة بسعة 16 GB: `gpt-oss:20b` (بمستوى ~o3-mini) أو `mistral-small3.1`. لروبوت دردشة مساعد للبرمجة: `qwen3.6:27b` (77.2% SWE-bench)، `kimi-k2.6` (MoE متقدم)، أو `laguna-xs-2.1` (وكيلة، طويلة الأفق). اقرنه بـ Open WebUI للحصول على واجهة قائمة على الويب تتصل بواجهة Ollama البرمجية على localhost:11434.
هل جميع نماذج Ollama مفتوحة المصدر فعليًا؟
ليست جميعها. تتضمن مكتبة Ollama نماذج برخص متنوعة. تستخدم Llama 3.x/4.x رخصة Meta Llama Community (ليست مفتوحة المصدر بموافقة OSI -- تقيّد الاستخدام التجاري فوق 700M مستخدم نشط شهريًا). نماذج Mistral Small وQwen3 وQwen 3.6 وDevstral وGemma هي Apache 2.0 (مفتوحة المصدر بالكامل). وKimi K2.6 مرخّص بـ Modified MIT (متوافق تجاريًا مع شرط إسناد). ويستخدم Laguna XS 2.1 رخصة OpenMDW-1.1 (متساهلة، الاستخدام التجاري مسموح، لكنها غير معتمدة من OSI). تحقّق دائمًا من الرخصة قبل النشر التجاري.
أي نموذج من عائلة Dolphin ينبغي أن أستخدمه مع Ollama؟
استخدم Dolphin 3.0 (`ollama pull dolphin3`)، وليس `dolphin-mistral` الأقدم (آخر تحديث له كان في 2024، ومبني على Mistral 0.2). Dolphin 3.0، الذي تصونه Cognitive Computations (Eric Hartford)، مبني على Llama 3.1، ولا يتضمن أي تصفية محتوى مدمجة، وهو مصمّم كنموذج محلي عام الأغراض للبرمجة والرياضيات والمهام الوكيلة والدردشة غير المقيدة.
أي نموذج تضمين ينبغي أن أستخدمه مع Ollama لـ RAG؟
`nomic-embed-text` هو الخيار القياسي -- نموذج بـ 137M معامل يولّد تضمينات بأبعاد 768، ويعمل بمللي ثوانٍ لكل مستند، ومصمّم خصيصًا لمهام الاسترجاع. نزّله عبر `ollama pull nomic-embed-text`. استخدمه مع ميزة RAG المدمجة في Open WebUI أو OllamaEmbeddings في LangChain أو LlamaIndex.
كم مرة تُحدَّث مكتبة Ollama بنماذج جديدة؟
يضيف فريق Ollama نماذج جديدة خلال أيام إلى أسابيع من الإصدارات الكبرى. ظهرت Laguna XS 2.1 (2 يوليو 2026) وKimi K2.7 Code وKimi K2.6 وQwen 3.6 جميعها خلال أيام من إطلاقها. الإصدار الحالي من Ollama هو v0.32.0 (11 يوليو 2026). تابع مستودع Ollama على GitHub (github.com/ollama/ollama) أو حساب Ollama على Twitter/X لإعلانات النماذج الجديدة.
ما الفرق بين `ollama pull` و`ollama run`؟
`ollama pull` ينزّل ملف النموذج إلى التخزين المحلي (عملية لمرة واحدة). `ollama run` يبدأ جلسة تفاعلية فور التنزيل، أو يعيد استخدام النموذج المنزّل مسبقًا إن توفّر. يمكنك التنزيل مرة واحدة والتشغيل عدة مرات دون إعادة تنزيل.
هل يمكنني تشغيل عدة نماذج في وقت واحد على الجهاز نفسه؟
نعم، إذا كان عتادك يمتلك VRAM كافيًا. استخدم نوافذ طرفية أو جلسات صدفة منفصلة -- نافذة تشغّل `ollama run llama3.2` بينما تشغّل أخرى `ollama run qwen2.5:7b`. يدير Ollama مشاركة VRAM تلقائيًا. راقب `nvidia-smi` أو نشاط النظام لتجنّب الحِمل الزائد.
كيف أحدّث نموذجًا إلى أحدث إصدار؟
`ollama pull [model-name]` يتحقق من التحديثات وينزّل أحدث إصدار إن توفّر. للعودة أو استخدام إصدارات محددة، استخدم وسوم الإصدار: `ollama pull llama3.1:8b` أو `ollama pull llama3.1:8b-instruct-q4_K_M`. تحقّق من الإصدارات المتاحة عبر `ollama show [model-name]`.
هل النماذج مفتوحة المصدر على Ollama مجانية للاستخدام التجاري فعليًا؟
معظمها كذلك، لكن ليس جميعها. تقيّد Llama 3.x (رخصة Meta Llama Community) الاستخدام التجاري فوق 700M مستخدم نشط شهريًا. تستخدم نماذج Mistral Small وQwen3 وGemma رخصة Apache 2.0 (متوافقة تجاريًا بالكامل). تحقّق دائمًا من الرخصة قبل النشر المؤسسي -- راجع صفحة النموذج على Hugging Face أو مدخله في مكتبة Ollama.
ما هي أفضل نماذج Ollama لمهام اللغة الروسية؟
يتضمن كل من Qwen3 / Qwen 3.6 (`ollama run qwen3:7b` أو `ollama run qwen3.6:27b`) وMistral Small 3.1 (`ollama run mistral-small3.1`) اللغة الروسية ضمن بيانات التدريب متعددة اللغات الأصلية لكل منهما. يحقق Qwen3 نتائج أعلى في معايير غير الإنجليزية، بينما يتميّز Mistral Small 3.1 بطلاقة محادثة روسية أقوى بحسب اختبارات غير رسمية. لا ينتمي أي منهما لأصل روسي -- بالنسبة لمتطلبات إقامة البيانات التنظيمية الخاصة بروسيا، تحقّق من رخصة النموذج ومتطلبات الامتثال الخاصة بمؤسستك بشكل منفصل، إذ لا يتناول هذا المقال قانون توطين البيانات الروسي.
المصادر
- Meta AI. (2025). "Llama 4 Model Card." llama.meta.com -- المواصفات الرسمية لـ Llama 4 Scout (17B نشط، 109B إجمالي، MoE) ومتغيّرات Maverick.
- DeepSeek AI. (2025). "DeepSeek-R1 Technical Report." arxiv.org/abs/2501.12948 -- بنية سلسلة التفكير ومعيار MATH (52%) لـ DeepSeek-R1.
- Qwen Team. (2026). "Qwen 3.6 Technical Report." arxiv.org/abs/2501.xxxxx -- 77.2% SWE-bench لأفضل نموذج برمجة كثيف.
- Moonshot AI. (2026). "Kimi K2.6 Model Card." moonshot.ai -- نموذج برمجة MoE مرخّص بـ Modified MIT (32B نشط/1T إجمالي)، SWE-Bench Pro 58.6.
- Mistral AI. (2026). "Devstral Small 24B." mistral.ai -- أفضل نموذج برمجة وكيل للتعديلات متعددة الملفات والتنقيح.
- Ollama. (2026). "Ollama Model Library." ollama.com/library -- مكتبة النماذج الرسمية بمئات النماذج المنسّقة وأعداد التنزيلات والوسوم وخيارات التكميم.
- Google DeepMind. (2026). "Gemma 4 Technical Report." -- قدرات الرؤية + استدعاء الأدوات الصادرة في أبريل 2026.
- Poolside. (2026). "Introducing Laguna XS 2.1." poolside.ai -- نموذج برمجة وكيلة MoE بحجم 33B/3B نشط، SWE-bench Verified 70.9%، رخصة OpenMDW-1.1.
- Ollama. (2026). "Ollama Releases." github.com/ollama/ollama/releases -- ملاحظات الإصدارات الرسمية، v0.32.0 (11 يوليو 2026).